CS336
CS336: Language Modeling from Scratch 课程笔记
CS336
Basics
Tokenization
Byte-Pair Encoding (BPE)
根据模型参数和硬件能力粗略估计耗时
float32、float16、bfloat16、fp8 (2022, E4M3 和 E5M2)、fp4 (2025)
混合精度:bf16(参数、激活、梯度)+ fp32(优化状态),使用 AMP 库
Einops 库:张量操作
einsum、reduce、rearrange
MFU = (actual FLOP/s) / (promised FLOP/s)
MFU 典型值约 0.5:FLOP / bytes = 运算强度 怎么看是内存受限还是计算受限:Roofline 模型
Model Architecture
架构和超参数
Normalization: Pre-Norm vs Post-Norm
- 最初的 Transformer 使用 Post-Norm(LayerNorm 在残差连接之后)
- Pre-Norm:LayerNorm 放在残差连接之前,保持残差流(residual stream)干净
- Pre-Norm 训练更稳定,减少梯度峰值的大小和频率
LayerNorm vs RMSNorm
- LayerNorm vs RMSNorm:RMSNorm 省略了均值中心化步骤,运算更快
- LayerNorm 的作用:控制梯度峰值,保证信号在深层网络中传递顺畅
- 丢弃 bias:简化系统实现,现代 LLM 普遍不使用 bias
激活函数与参数量平衡
- 初始 Transformer 使用 ReLU,后续发现 GELU、SwiGLU 等激活函数性能更好
- 激活函数(如 SwiGLU)会增加额外参数量
- 保持架构总参数不变:缩小前馈维度,将 d_ff 调整为原来的 2/3
- 例:原来 d_ff = 4d_model → 使用 SwiGLU 后 d_ff = (4 × 2/3) d_model ≈ 8/3 d_model
串行 vs 并行 Layers
- 串行(Sequential):每层依次计算,先 Attention 再 FFN
- 并行(Parallel):Attention 和 FFN 并行计算后合并
- 现代模型更多使用串行,训练更稳定
位置编码:RoPE(Rotary Position Embedding)
- 当前主流方案,将位置信息编码为旋转矩阵
- 相对位置编码:通过旋转角度差表示 token 间距离
超参数选择
| 超参数 | 说明 |
|---|---|
| feedforward-size | d_ff = 4 × d_model(标准);使用 SwiGLU 时调整为 ~8/3 × d_model |
| num-heads | head_dim = d_model / num_heads,通常 head_dim ≥ 64 |
| d_model / n_layer | 深度和宽度的权衡,比值大约在 100 左右 |
| Vocab-size | 单语种 30-50k,多语种 100-250k |
| Dropout | 现代大规模预训练中较少使用 |
| Weight decay | 典型值 0.1,防止权重过大 |
训练稳定性技巧
- Softmax 不稳定:指数运算可能溢出,除 0 操作导致 NaN
- 解决:输出端添加 z-loss(对 logits 的平方惩罚)
- 解决:注意力归一化中使用 QK norm(对 Q、K 做归一化)
- Logit soft-capping:用 Tanh 将 logits 压缩到某个最大值范围内,防止极端值
Attention Heads 变体
- MHA(Multi-Head Attention):标准多头注意力
- MQA(Multi-Query Attention):多个 query head 共享同一组 K、V,减少 KV cache
- GQA(Grouped-Query Attention):介于 MHA 和 MQA 之间,每组 query head 共享 K、V,当前主流
- 滑动窗口注意力(Sliding Window Attention):交替使用 full attention 和 local attention(LR attention),兼顾全局建模与效率
Attention Alternatives & Mixture of Experts
Attention Alternatives
| 方案 | 说明 |
|---|---|
| Sliding Window + Full Attention | 组合局部与全局注意力 |
| FlashAttention | 系统工程层面优化,IO-aware 的精确注意力实现 |
| Linear Attention | 线性注意力,如 MiniMax M1 |
| Gated $\gamma_t$ | Mamba-2 的核心机制 |
| Nemotron-3 | NVIDIA 的门控线性注意力方案 |
| Gated $\gamma_t$ + $\beta_t$ | Gated DeltaNet,结合门控与 delta 更新 |
| DSA(DeepSeek Sparse Attention) | DeepSeek V3.2 / GLM-5 使用,Lightning Indexer 机制 |
注意力计算的优化思路
- 将注意力重排为 RNN 递归形式,有利于推理阶段效率(逐 token 生成时避免重复计算)
MoE(Mixture of Experts)
MoE 可以看作高效的 MLP 替代方案,将 Dense Model 转化为 Sparse Model。
核心思想:
- 在 FFN 层引入多个专家(expert),每个 token 只激活其中一部分
- 为模型增加了一个新的并行化维度(expert 并行)
路由函数(Routing)
三种路由范式:
- Token 选择 Expert:每个 token 通过路由函数决定由哪些 expert 处理
- Expert 选择 Token:expert 反向选择要处理的 token
- 全局路由:全局视角进行决策,统一调度 token 与 expert 的分配
具体路由策略:
- Top-k routing:最常用,每个 token 选择 top-k 个 expert,一般 k 大于 2,其中 Grok (K=2), Qwen (K=4), DeepSeek (K=8)
- Hash routing:基于 hash 的确定性分配,简单 baseline
- RL 学习路由:用强化学习优化门控策略
- 匹配问题求解:将路由建模为优化问题
共享专家(Shared Expert)
- 部分专家对所有 token 激活,不参与路由
- 保证基础能力的稳定输出
训练 MoE 的方法
- 强化学习优化门控策略
- 随机扰动(Stochastic Perturbations)
- 启发式策略:辅助负载均衡 loss(heuristic balancing losses)
训练 MoE 的挑战
负载均衡问题:
- 路由不均匀导致部分 expert 过载、部分闲置
并行策略:
- 数据并行:batch size 达到极限时无法继续扩展
- 模型并行:将模型拆分到多个设备
- 专家并行:不同 expert 分布在不同设备上,MoE 特有的并行方式
Upcycling
- 将已训练好的 Dense Model 复制为多个 expert 再继续训练
- 降低 MoE 训练的初始化成本
MTP(Multi-Token Prediction)
- 一次预测多个未来 token,而非仅预测下一个 token
Systems
Kernels
GPU:执行单元 + 内存层次系统 gpu-glossary
- SM (Streaming Multiprocessor):计算核心,执行 CUDA 核函数;每个 SM 包含多个 SP (Streaming Processor)
- L1 Cache, Shared Memory, Register File:SM 内部的高速存储层次
- L2 Cache:在芯片上 (on die) 的全局缓存,所有 SM 共享
- Global Memory:内存芯片,容量大但访问延迟高
| A100 | H100 | B200 | |
|---|---|---|---|
| SMs | 108 | 132 | 148 |
| Register size (per SM) | 256 KB | 256 KB | 256 KB |
| L1 cache + shared memory (per SM) | 192 KB | 256 KB | 256 KB |
| L2 cache size | 40 MB | 50 MB | 96~126 MB |
| HBM size | 80 GB | 80 GB | 192 GB |
| Register bandwidth | ~116 TB/s | ~401 TB/s | ~447 TB/s |
| L1 cache + shared memory bandwidth | ~19 TB/s | ~33 TB/s | ~19 TB/s |
| L2 cache bandwidth | ~5~8 TB/s | ~12 TB/s | ~9 TB/s |
| HBM bandwidth | 2 TB/s | 3.35 TB/s | 8 TB/s |
- Threads:线程以并行方式,所有线程执行相同的指令,但输入不同(SIMT:单指令多线程)
- Blocks:block 是由多个线程组成的 group。每个 block 在一个 SM 上运行,并拥有自己的共享内存
- Grid:thread blocks 集合
- Warp:一个 warp 由 32 个连续的线程组成
SM 运行多个 warp。每个线程使用 0~255 个寄存器。
bank conflicts(shared memory)
- 共享内存被分为 32 个 bank,每个 bank 宽 4 bytes。
- 同一 warp 内多个线程访问同一 bank 的不同地址时会冲突(访问同一地址是 broadcast,不冲突)。
- 方法:对共享内存重新排列来避免 bank 冲突。
Memory coalescing(HBM)
- 一个 warp 访问 HBM,地址连续且对齐时,一次性把整条缓存行 $32 threads \times 4 bytes = 128 bytes$ 取出。若地址不连续或未对齐,可能触发多次 128-byte 事务。
GPU 编程的优化技巧
- trick0:control divergence
- trick1:low precision computation
- trick2:operator fusion(最小化内存访问次数,减少内存带宽压力)
- trick3:recomputation(反向传播时重新计算前向结果,节省内存空间)
- trick4:memory coalescing and DRAM(矩阵乘法)
- trick5:tiling(分块,最小化全局内存访问)
影响 tile 大小的因素:合并内存访问、共享内存大小、矩阵维度是否整除
内存对齐:内存以 burst 方式加载,当 burst 与矩阵对齐时加载 tile 很快。burst:一种批量连续读内存的机制
出现抖动可能原因:wave quantization。1792 变成 1793 后,tile 大小是 256×128,那 1792×1792 的矩阵需要 7×14 = 98 个 tiles,1793×1793 的矩阵需要 8×15 = 120 个 tiles;A100 有 108 个 SM,120 个 tiles 会多出一小波调度,线程块数量最好接近 SM 数的整数倍。
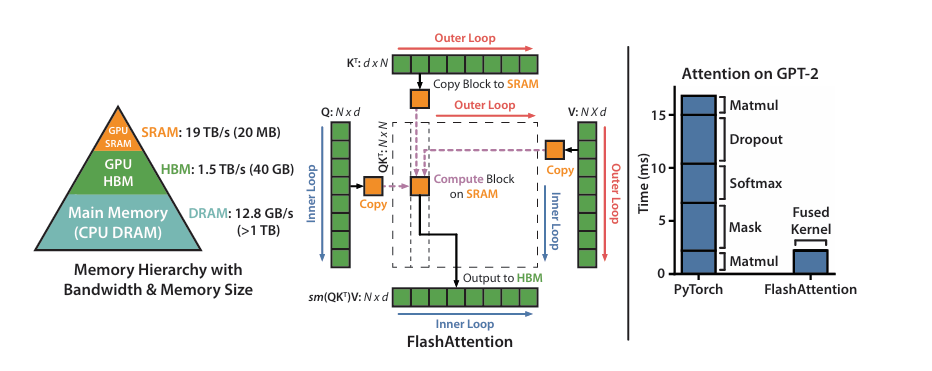
benchmark and profiling
| |
Parallelism
集合通信操作(Collective Operations)
Rank:具体的设备 World size:设备总数
基础操作
| 操作 | 说明 | 典型场景 |
|---|---|---|
| Broadcast | 将 rank0 数据拷贝给所有 rank | 初始化 checkpoint 分发 |
| Scatter | 将 rank0 数据分发到各进程 | 数据分片 |
| Gather | Scatter 的反操作,聚合数据到 rank0 | 结果收集 |
| Reduce | 用操作(sum/min/max 等)聚合所有 rank 到 rank0 | 梯度汇总 |
核心操作
| 操作 | 说明 | 典型场景 |
|---|---|---|
| All-Gather | 对所有 rank 进行 Gather,每个 rank 拿到完整结果 | 模型参数同步 |
| Reduce-Scatter | 按维度 Reduce 后 Scatter 结果 | 反向传播,梯度求和后分发 |
| All-Reduce | Reduce-Scatter + All-Gather | 数据并行梯度同步 |
| All-to-All | 每个 rank 向其他所有 rank 发送不同数据 | MoE 路由,数据给对应专家 |
通信基础设施
同一节点下的 GPU 通过 PCIe/NVLink 通信,不同节点间通过 InfiniBand/Ethernet 通信。
| 层级 | 连接方式 | 带宽参考 |
|---|---|---|
| 节点内 | 8 GPU → NVLink → NVSwitch | PCIe v7.0 (16 lanes): 242 GB/s;B200 NVLink 5.0: 1.8 TB/s |
| Pod 内 | 256 节点 → InfiniBand | ~0.05 TB/s |
| 集群/DC | N Pods → Ethernet | ~200 MB/s |
GB200/GB300 NVL72:8 GPU/tray × 9 trays/rack = 72 GPUs in one NVLink domain
RDMA(Remote Direct Memory Access):允许 GPU 直接读写另一个 GPU 的内存,不经过 CPU。InfiniBand 支持,标准以太网不支持。
RoCE(RDMA over Converged Ethernet):基于以太网的 RDMA 技术,比 InfiniBand 便宜但性能稍弱。
NCCL(NVIDIA Collective Communications Library):NVIDIA 集合通信库
分布式训练
| 策略 | 并行维度 | 切分方式 | 通信内容 |
|---|---|---|---|
| 数据并行(Data Parallelism) | batch | 数据分片,每个 GPU 负责一部分 | DDP: All-Reduce;FSDP/ZeRO: All-Gather + Reduce-Scatter |
| 张量并行(Tensor Parallelism) | width | 每个 GPU 负责每层的一部分 | 激活值(All-Gather),依赖 NVLink 等高速互联 |
| 流水线并行(Pipeline Parallelism) | depth | 每个 GPU 负责部分层 | 激活值(点对点 send/recv),通过 micro-batch 减少 pipeline bubble |
| 序列并行(Sequence Parallelism) | length | 沿序列维度切分,Attention 计算并行化 | KV/激活值(All-Gather) |
| 专家并行(Expert Parallelism) | width | MoE 中的 FFN/MLP 并行化,不同 expert 分布在不同 GPU | token 路由(All-to-All) |
ZeRO(Zero Redundancy Optimizer):用于降低数据并行(DP)中的冗余内存开销。根据 stage 不同,可分别切分优化器状态、梯度和参数,并通过 Reduce-Scatter / All-Gather 等通信完成同步。
Inference
vLLM, SGLang, TensorRT-LLM, llama.cpp
衡量指标:
- TTFT(Time-to-first-token):首 token 延迟
- Latency (seconds/token):单查询 token 生成速度
- Throughput (tokens/second):多查询总生成速度
推理两阶段
| 维度 | Prefill(预填充) | Decode(解码生成) |
|---|---|---|
| 计算方式 | 批量并行,一次性处理 Prompt | 串行增量,每次处理一个 token |
| 资源需求 | 计算密集型 | 内存密集型 |
| KV Cache | 首次构建 | 仅追加新 token 的 K/V |
| 耗时决定因素 | Prompt 长度 | 生成 token 数 |
KV cache:对每个 sequence(B)、token(S)、layer(L)、head(K),存储 $H$ 维向量
延迟-吞吐量权衡:增大 batch → 延迟增加(KV cache 更大)+ 吞吐量提升(摊薄参数读取)
- TTFT 优化:Prefill 用小 batch,Decode 用大 batch
减少 KV cache 大小
Grouped-query attention(GQA):$N$ 个 query head 共享 $K$ 个 KV head(MHA: $K=N$,MQA: $K=1$,GQA: K在1和N之间),KV cache 减小 $N/K$ 倍
Multi-head latent attention(MLA):存储压缩向量 $c = W_c h$($C$ 维),按需投影 $K = W_K c$;DeepSeek v2: $16384 \to 512$ 维;不兼容 RoPE,需额外 64 维;精度略优于 MHA
CLA:跨层共享 KV(类比 GQA 跨 head 共享),改善精度-KV 大小 Pareto 前沿
滑动窗口注意力:只关注局部上下文,KV cache 与序列长度无关;有效上下文随层数线性增长;可与全局注意力交替使用
DeepSeek v4:支持 1M 上下文,组合 Compressed Sparse Attention(CSA)(压缩 $m$ token → 1)、Deepseek Sparse Attention(DSA)(选 top-$k$)、Heavily Compressed Attention(HCA)(更高压缩比)
其他方向:线性注意力、状态空间模型(Mamba 2、GatedDeltaNet)
量化
降低精度 → 减少内存 → 提升速度(推理内存受限)
| 格式 | 大小 | 说明 |
|---|---|---|
| fp32 | 4B | 训练参数/优化器 |
| bf16 | 2B | 推理默认 |
| fp8 | 1B | H100 支持,可训练 |
| int8 | 1B | 仅推理 |
| int4 | 0.5B | 更便宜,精度更低 |
- Quantization-aware training (QAT):训练时量化-反量化模拟误差,精度好但训练贵
- Post-training quantization (PTQ):训练后执行,成本低;GPTQ 用 Hessian 信息补偿误差
- Activation-aware quantization (AWQ):根据激活值选 0.1-1% 权重保持高精度,fp16→int4 达 4x 内存降低、3.2x 加速
模型剪枝
剪枝+蒸馏:校准数据识别重要层/head → 移除不重要部分 → 蒸馏恢复精度
投机采样
Speculative Sampling:检查比生成快
- 草稿模型 $p$ 猜测若干 token(如 4 个)
- 目标模型 $q$ 并行评估,合理则采纳
- 修改版拒绝采样(保证至少一个候选)
动态工作负载
挑战:请求到达时间不同、序列有共享前缀、长度各异
连续批处理:迭代级调度,新请求即时加入 batch;选择性批处理——注意力单独处理,非注意力拼接张量
PagedAttention:KV cache 划分为非连续块(借鉴 OS 分页),解决预分配导致的内存碎片化;支持前缀共享和写时复制(CoW)
Scaling Laws
数据缩放
- 误差随数据量 $n$ 幂律下降:$\mathcal{E} = a + b n^{-\alpha}$
- log-log 下近似直线
- 理论:均值估计误差 $\sigma^2/n$;非参数学习误差 $n^{-1/d}$
模型缩放
- 架构(Transformer vs LSTM)、优化器(Adam vs SGD)可通过小模型预测
- 层数、宽深比对 loss 影响较小(参数固定时)
- 临界批量 $B_{\text{crit}}$:超过后收益递减
- 学习率需按 µP 规则缩放(宽模型)
联合缩放(数据 + 模型)
- 误差形式:$\text{Error} = n^{-\alpha} + m^{-\beta} + C$
- 用于最优分配计算预算
Kaplan(OpenAI 2020)
- $N_{\text{opt}} \propto C^{0.73},\; D_{\text{opt}} \propto C^{0.27}$
- 模型偏大,数据相对不足
Chinchilla(DeepMind 2022)
- $N_{\text{opt}} \propto C^{0.5},\; D_{\text{opt}} \propto C^{0.5}$(数据与模型等比例扩展)
- 约 20 tokens / param 为计算最优(纠正了 Kaplan 时代大模型 token 不足的问题)
- 若推理为主,应 over-train(更多 token)
注意
- 缩放定律是下界,可能被打破
- 下游任务缩放不如预训练平滑
μP(maximal-update-parameterization 最大更新参数化)
μP 是一套初始化 + 学习率缩放规则,使得最优超参数(尤其是 LR学习率)在宽度变化时保持稳定。
核心条件
- A1:初始化时激活值量级 $\Theta(1)$(与宽度无关)
- A2:单步更新后激活变化量级 $\Theta(1)$
缩放公式(线性层)
- 初始化标准差:$\Theta\left(\frac{1}{\sqrt{n_{l-1}}} \min\left(1, \sqrt{\frac{n_l}{n_{l-1}}}\right)\right)$
- 学习率(SGD):$\eta = \Theta\left(\frac{n_l}{n_{l-1}}\right)$;Adam 则为 $\Theta\left(\frac{1}{n_{l-1}}\right)$
相比“标准”参数化(初始化 $\frac{1}{\sqrt{n_{l-1}}}$,LR $\Theta(1)$),μP 在 $n_l < n_{l-1}$ 时调整初始化和 LR,避免激活爆炸或消失。
μP 的鲁棒性与失效场景
| 组件/修改 | 是否破坏 μP | 说明 |
|---|---|---|
| RMSNorm 可学习增益(向量/标量) | 是 | 最优 LR 无法跨宽度迁移,且损害最终性能 |
| Lion 优化器 | 是 | 基于符号的优化器破坏 μP 假设 |
| 强权重衰减(λ=0.1) | 是 | 唯一显著失效场景,最优 LR 在 2048 宽时偏移 |
| SwiGLU / 平方 ReLU | 否 | 实验表明 μP 仍稳定 |
| 零注意力 / 不同批大小 | 否 | 可安全使用 |
WSD (Warmup‑Stable‑Decay学习率调度器)
目的:以线性成本 $O(mC)$ 测量缩放定律,避免从头训练多个模型。
调度阶段
- Warmup:快速升至峰值 LR
- Stable:长时间保持高 LR,训练至目标 token 数的 $k$ 倍
- Decay:约占总 token 的 10%,LR 快速降至接近 0
优势
- 从 Stable 阶段任意步数的检查点开始 Decay,均可达到与 Cosine 调度相同的最终 loss
- 因此可一次训练,在不同 token 量处 Decay,同时获得多个 $(D, L)$ 点 → 拟合 Chinchilla 曲线无需 $n^2$ 成本
模型缩放策略总结
| 模型 | 核心缩放技术 | 关键结论 |
|---|---|---|
| 面壁智能-MiniCPM | μP + WSD + 小规模拟合(Chinchilla 方法 1&3) | 最优 data‑to‑model 比例远高于 Chinchilla(更重数据) |
| DeepSeek | 无 μP,网格搜索 + 幂律外推 LR/Batch + 多步衰减调度 | 7B/67B 性能被小规模缩放律精确预测(图 5) |
| Qwen 2.5/3 | 类似 DeepSeek 的 LR/Batch 缩放,另加 MoE 对比 | 为 MoE 和 Dense 模型分别推导超参数缩放律 |
| LLaMA 3 | 仅 IsoFLOP 曲线($6\times10^{18}$–$10^{22}$ FLOPs) | 未公开 LR/Batch 细节 |
| Kimi K2 | MoE 稀疏度缩放 + Muon 优化器 + 固定激活 8/总 384 | 稀疏度 48 为性能‑成本平衡点 |
Data
Evaluation
困惑度(Perplexity, PPL):衡量模型预测的随机性,越小越好
| Benchmark | 类别 |
|---|---|
| LAMBADA, HellaSwag | 困惑度 / 完形填空 |
| MMLU, MMLU-Pro, GPQA, HLE | 考试型 |
| Chatbot Arena, AlpacaEval, WildBench | 聊天型 |
| SWE-Bench, TerminalBench, CyBench, MLEBench | 智能体型 |
| ARC-AGI | 纯推理 |
| HarmBench, AIR-Bench | 安全型 |
原始数据源
- Common Crawl:非营利网络爬虫,每月新增30-50亿页面,提供WARC/WET格式。
- Wikipedia:免费在线百科全书,多语言,定期dump。
- GitHub / Software Heritage:代码仓库与源码存档。
- arXiv:学术预印本,覆盖物理、数学、CS等。
- Project Gutenberg:公有领域电子书(版权过期)。
- Shadow Libraries:LibGen、Sci-Hub(版权争议,常被用于Books3等数据集)。
按模型/数据集归类
| 模型/数据集 | 原材料来源(数据从哪来) |
|---|---|
| BERT | Wikipedia + BookCorpus(Smashwords 自出版书籍) |
| GPT-2 (WebText) | Reddit外链(Karma ≥ 3的高质量帖子) |
| T5 (C4) | Common Crawl(规则过滤:标点、禁用词、去代码) |
| CCNet | Common Crawl(以Wikipedia为参考进行质量过滤) |
| GPT-3 | Common Crawl + WebText2 + Books1/2 + Wikipedia |
| The Pile | Pile-CC, PubMed Central, arXiv, Enron邮件, Project Gutenberg, Books3(Bibliotik), StackExchange |
| Gopher (MassiveText) | MassiveWeb, C4, Books, News, GitHub, Wikipedia |
| LLaMA | CommonCrawl(CCNet), C4, GitHub(许可过滤), Wikipedia, Gutenberg, Books3, arXiv, StackExchange |
| RefinedWeb | Common Crawl(使用WARC+trafilatura提取,Gopher规则过滤) |
| Dolma | Reddit(Pushshift), PeS2o(Semantic Scholar), C4, Gutenberg, Wikipedia, Common Crawl |
| DCLM | Common Crawl(基于模型的质量分类器筛选) |
| Nemotron-CC | Common Crawl(分类器集成 + 合成数据重写增强) |
| The Stack v2 | GitHub仓库(克隆), Issues/PRs, Software Heritage, 技术文档网站 |
| CommonPile | 仅使用许可协议数据(MIT、Apache等) |
数据处理流程 (Data Pipeline)
数据转换 (Transformation)
原始数据不是纯文本,需要转成模型可读的格式。
HTML (Common Crawl): 使用 trafilatura, resiliparse, jusText, lynx 等工具提取正文,去除导航、广告等
PDF (arXiv): 使用 OCR (RolmOCR) 或 Docling 提取, FinePDFs
数据过滤 (Filtering)
核心逻辑:给定目标数据 T 和原始数据 R,从 R 中筛选出与 T 相似的数据子集。
应用场景:
- 语言识别 (Language ID): 使用 fastText 分类器
- 质量过滤 (Quality Filtering)
- 毒性过滤 (Toxicity Filtering)
数据去重 (Deduplication)
- 精确重复:镜像站、GitHub forks。 每个 Item(粒度一般为:句子 / 段落 / 文档) 计算哈希值(如 MurmurHash),相同哈希保留一个。可并行(MapReduce 风格)。
- 近似重复:MIT 许可证文本、模板化生成的内容。参考书籍:Mining of Massive Datasets Ch.3
Jaccard 相似度, MinHash, LSH(Locality Sensitive Hashing)
数据混合 (Data Mixing)
核心问题:多个数据源(Wikipedia、CC、GitHub等)应该按什么比例混合?
常见基线方法
- Vibe-based:人工直觉设置
- Uniform:各源均等采样 (p(s) ∝ 1)
- Proportional:按源的总 token 数比例采样 (p(s) ∝ tokens_in_source(s))
高质量但稀疏的数据源(如 Wikipedia)如果权重过高,会反复迭代(epoch)导致过拟合。
- UniMax: 均匀采样数据源,但对训练epoch设置上限。
- Regression-based Mixing
- Simulated Epoching: 小规模实验模拟大规模训练
后训练数据 (Post-Training Data)
通用流程:定义一组环境 -> 定义任务 / Prompt 集合 -> 从强模型(Teacher)收集回答
OpenThoughts, SWE-smith, SWE-Zero, SWE-rebench, SWE-ZERO-12M
Alignment
模型的输出与人类意图“对齐”,符合人类偏好
SFT
目标: 拟合参考分布
监督微调(SFT) data: FLAN, Self-instruct, Alpaca, ShareGPT/Vicuna, OpenAssistant, WizardLM, Tulu3, Nemotron
质量大于数量。
RLHF
目标: 最大期望奖励,同时不要偏离参考模型太远
风险:过度优化, 模式坍塌(校准性(calibration)丧失:模型输出的概率不再反映真实不确定性)
Learning to summarize from human feedback, Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
RLHF 的数据与标注挑战
- 标注者偏见:众包标注者系统性低估事实性错误,且对语气自信的输出更容易放过错误。
- 人口统计学影响:标注者的文化/宗教背景会直接影响模型对不同群体的“关联度”评分。
- 长度偏见 (Length Bias):人类天然认为“长 = 好”,导致模型学会堆砌废话而非提升信息密度(这是 RLHF 后回答变长的核心原因)。
- AI 作为标注者:GPT-4 的偏好标注与人类一致性接近。
PPO (Proximal Policy Optimization) (on-policy)
$$ \mathcal{J}(\phi)= \mathbb{E}_{(x,y)\sim D_{\pi_{\phi}^{\mathrm{RL}}}} \left[r_{\theta}(x,y)-\beta \log \left( \frac{\pi_{\phi}^{\mathrm{RL}}(y \mid x)} {\pi^{\mathrm{SFT}}(y \mid x)} \right)\right] + \gamma \,\mathbb{E}_{x\sim D_{\mathrm{pretrain}}} \left[\log \pi_{\phi}^{\mathrm{RL}}(x)\right] $$局限: 需要价值模型,显存占用大,调参困难
PPO演进路线
- 策略梯度 (Policy Gradient): 方差过大
- TRPO (Trust Region Policy Optimization): 带 KL 约束的线性化近似
- PPO (Proximal Policy Optimization): 用 clip 替代显式 KL 约束,裁剪概率比率,防止策略更新过大
DPO (off-policy)
$$ \mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}_{(x,y_w,y_l)\sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w \mid x)}{\pi_{\text{ref}}(y_w \mid x)} - \beta \log \frac{\pi_\theta(y_l \mid x)}{\pi_{\text{ref}}(y_l \mid x)} \right) \right] $$idea: 绕过奖励模型和在线采样,用监督学习的方式实现了 RLHF 的效果
局限: 数据必须是成对 (Pairwise) 的 Bradley-Terry 比较数据;本质离线
变体: SimPO, Length-normalized DPO
RLVR (RL from Verifiable Rewards 基于可验证奖励的 RL)
RLHF 无法干净地规模化(过度优化)。在数学、代码等具有客观正确性的领域,直接用规则/验证器提供奖励信号。
GRPO(Group Relative Policy Optimization)
$$ \mathcal{J}_{GRPO}(\theta) = \mathbb{E}_{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}(o|q)} \left[ \frac{1}{G} \sum_{i=1}^G \min \left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} A_i, \operatorname{clip}\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right) - \beta \cdot \mathbb{D}_{KL}(\pi_\theta \parallel \pi_{\text{ref}}) \right] $$idea: 移除价值网络,用组内相对奖励来计算优势
局限: 存在理论缺陷(无效基线)和长度偏差 (未显式归一化序列长度,正确回答倾向于被拉短,错误回答倾向于被拉长,需要引入长度惩罚项来缓解)
Lightweight Guide to understanding GRPO and RL principles, policy-gradient
- SFT 冷启动(Cold Start):收集少量长 CoT(思维链)数据进行微调,避免 R1-Zero 早期的不稳定。
- 推理 RL(Reasoning RL):类似 R1-Zero,但增加了语言一致性奖励(Language Consistency Reward),防止思维链出现多语言混杂。
- 拒绝采样与 SFT(Rejection Sampling & SFT):利用 RL 后的模型生成高质量推理数据(600k + 200k 非推理数据)进行微调。
- 最终 RLHF(Final RLHF):在推理数据上继续用 GRPO,在非推理任务上复用 V3 的 RLHF 流程。
Multimodality
图像编码器
将图像编码注入大型语言模型
| 模型 | vision encoder | text encoder | projector | Training |
|---|---|---|---|---|
| LLaVA | CLIP | Vicuna | 线性投影(Linear Projection W) | 1.(alignment)冻结视觉编码器和语言模型,仅训练 W;2.(fine-tuning)冻结视觉编码器,训练 W 和语言模型 |
| LLaVA OneVision | SigLIP | Qwen-2 72B | 2层MLP | 1.语言-图像对齐;2.高质量知识学习;3.视觉指令微调 |
| Qwen-VL | OpenCLIP’s ViT-bigC | QwenLM | 一层交叉注意力,融入 2D 位置编码,映射到固定长度 256 | 1.大规模低质量数据;冻结 LM,训练视觉编码器 + 适配器;2.更高质量的任务特定数据,提升分辨率;训练所有参数; 3.指令微调数据;冻结视觉编码器,训练适配器 + LM |
| Qwen2-VL | larger ViT | Qwen-2 | MLP | 1.仅训练视觉编码器;2.全参数;3.指令微调 |
| Qwen3-VL | SigLIP-2 | Qwen-3 | DeepStack | 1.训练适配器 2.全参数训练 3.后训练:SFT(长 CoT 数据)、知识蒸馏、RL |
原生多模态 Chameleon: 所有内容离散化为 Token
视觉编码器 VQ-VAE
拓展
- 部分 logits 变 NaN → 重复输出同一 token,形成死循环
- 工具调用失败 → 生成变长、死循环重复调用
- Off-by-one 错误读取 GPU 未初始化内存,输出随机中文token → 英文输入,输出中文
Megakernels(系统/推理引擎优化):将多个计算内核融合成一个“巨型内核”来降低延迟。
Parcae: Scaling Laws For Stable Looped Language Models: 核心思想是通过重复使用相同的网络层(增加“循环深度”)来提升模型性能,而不是单纯地增加参数量。