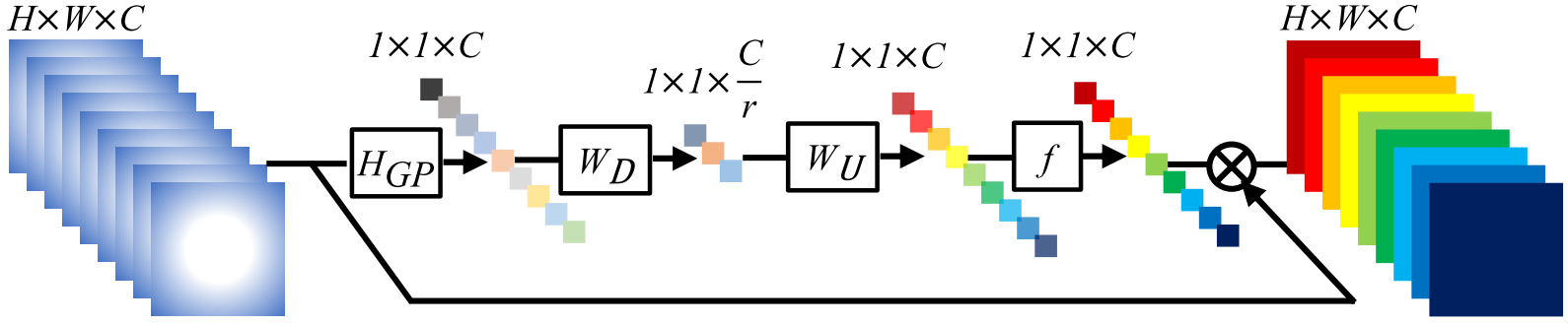SENet
文章标题:Squeeze-and-Excitation Networks
作者:Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu
发表时间:(CVPR 2018)
Official Code
External-Attention-pytorch senet.pytorch
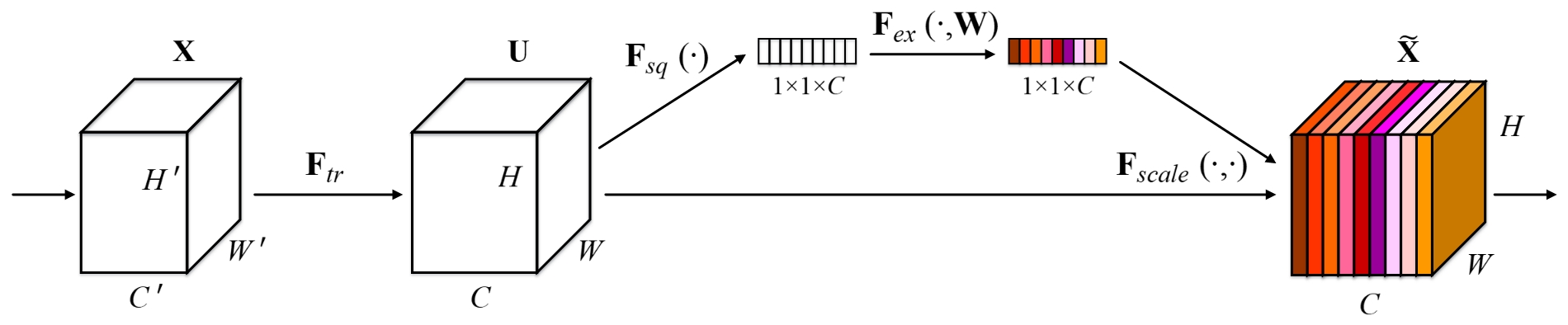
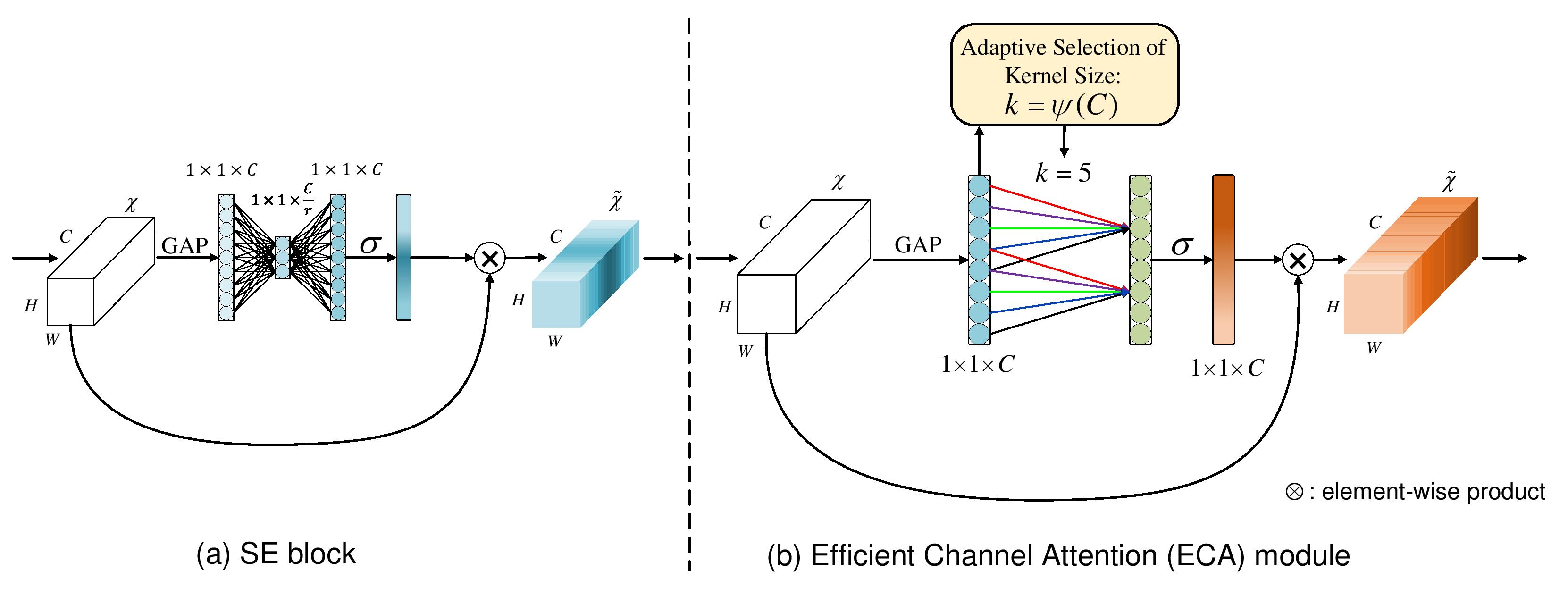
Diagram of a Squeeze-and-Excitation building block.
$$
u_c=v_c*X=\sum_{s=1}^{C'}v_c^s*x^s
$$输入:$X=[x^1,x^2,…,x^{C’}]$
输出:$U=[u_1,u_2,…,u_C]$
$v_c=[v_c^1,v_c^2,…,v_c^{C’}] $;$v_c^s$是一个二维空间内核,表示作用于 $X $的相应通道的 $v_c$的单个通道。
卷积核的集合:$V=[v_1,v_2,…,v_C]$
压缩(Squeeze) :经过(全局平均池化)压缩操作后特征图被压缩为1×1×C向量;也可以采用更复杂的策略**(收集全局空间信息)**
为什么用平均池化:卷积计算:参数量比较大;最大池化:可能用于检测等其他任务,输入的特征图是变化的,能量 无法保持
$$
z_c=F_{sq}(u_c)=\frac{1}{H\times W}\sum_{i=1}^H\sum_{j=1}^Wu_c(i,j)
$$
激励(Excitation) :将特征维度降低到输入的 1/16$(r)$,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度,然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重(捕获通道级关系并输出注意向量)
$$
s=F_{ex}(z,W)=\sigma(g(z,W)) =\sigma(W_2\delta(W_1z))
$$
$\delta$:ReLU;$\sigma$:sigmoid激活,$W_1\in R^{\frac{C}{r}\times C}$:降维层;$W_2\in R^{C \times\frac{C}{r}}$:升维层
比直接用一个 Fully Connected 层的好处在于
1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;
2)极大地减少了参数量和计算量
c可能很大,所以需要降维
scale操作 :最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上
$$
\tilde x_c = F_{scale}(u_c,s_c)=s_cu_c
$$$$
s = F_{se}(X,\theta) = \sigma(W_2\delta(W_1 GAP(X)))
\\ Y = sX
\\ global\ average\ pooling\rightarrow MLP\rightarrow sigmoid
$$
缺点:在挤压模块中,全局平均池(一阶统计信息)太过简单,无法捕获复杂的全局信息。在激励模块中,全连接层增加了模型的复杂性。
GAP(全局平均池化)在某些情况下会失效 ,如将SE模块部署在LN层之后,因为LN固定了每个通道的平均数,对于任意输入,GAP的输出都是恒定的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import torch
from torch import nn
class SEAttention ( nn . Module ):
def __init__ ( self , channel = 512 , reduction = 16 ):
super () . __init__ ()
self . avg_pool = nn . AdaptiveAvgPool2d ( 1 )
self . fc = nn . Sequential (
nn . Linear ( channel , channel // reduction , bias = False ),
nn . ReLU ( inplace = True ),
nn . Linear ( channel // reduction , channel , bias = False ),
nn . Sigmoid ()
)
def forward ( self , x ):
b , c , _ , _ = x . size ()
y = self . avg_pool ( x ) . view ( b , c )
y = self . fc ( y ) . view ( b , c , 1 , 1 )
return x * y . expand_as ( x )
CV27 Momenta研发总监 孙刚 Squeeze and Excitation Networks上
CV27 Momenta研发总监 孙刚 Squeeze and Excitation Networks下
改进挤压模块
EncNet
文章标题:Context Encoding for Semantic Segmentation
作者:Hang Zhang, Kristin Dana, Jianping Shi, Zhongyue Zhang, Xiaogang Wang, Ambrish Tyagi, Amit Agrawal
发表时间:(CVPR 2018)
Official Code (看不懂)
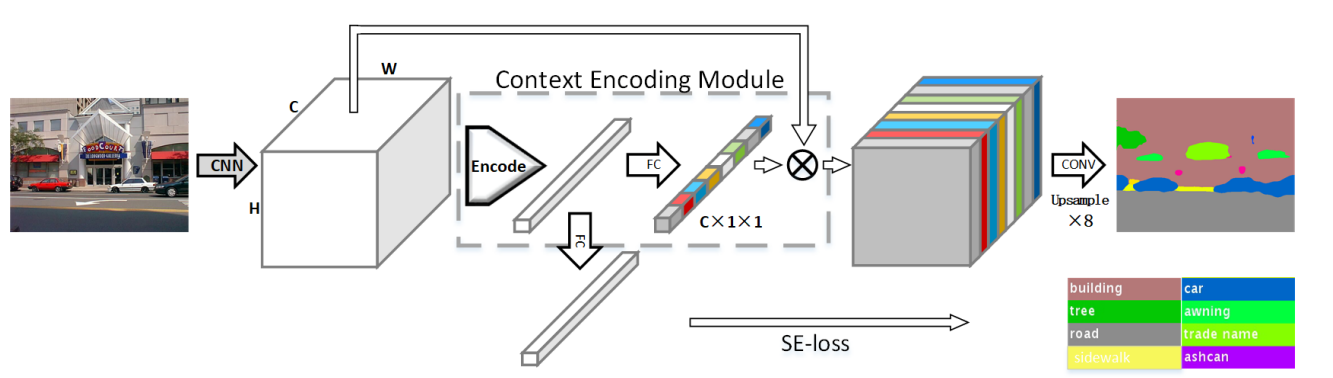
EncModule
$$
e_k = \frac{\sum_{i=1}^N e^{-s_k||X_i-d_k||^2}(X_i-d_k)}{\sum_{i=1}^K e^{-s_j||X_i-d_j||^2}}
\\ e = \sum_{k=1}^K \phi(e_k)
\\ s = \sigma(We)
\\ Y = sX
\\ encoder\rightarrow MLP\rightarrow sigmoid
$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class EncModule ( nn . Module ):
def __init__ ( self , in_channels , nclass , ncodes = 32 , se_loss = True , norm_layer = None ):
super ( EncModule , self ) . __init__ ()
self . se_loss = se_loss
self . encoding = nn . Sequential (
nn . Conv2d ( in_channels , in_channels , 1 , bias = False ),
norm_layer ( in_channels ),
nn . ReLU ( inplace = True ),
Encoding ( D = in_channels , K = ncodes ),
norm_layer ( ncodes ),
nn . ReLU ( inplace = True ),
Mean ( dim = 1 ))
self . fc = nn . Sequential (
nn . Linear ( in_channels , in_channels ),
nn . Sigmoid ())
if self . se_loss :
self . selayer = nn . Linear ( in_channels , nclass )
def forward ( self , x ):
en = self . encoding ( x )
b , c , _ , _ = x . size ()
gamma = self . fc ( en )
y = gamma . view ( b , c , 1 , 1 )
outputs = [ F . relu_ ( x + x * y )]
if self . se_loss :
outputs . append ( self . selayer ( en ))
return tuple ( outputs )
GSoP-Net
文章标题:Global Second-order Pooling Convolutional Networks
作者:Zilin Gao, Jiangtao Xie, Qilong Wang, Peihua Li
发表时间:(CVPR 2019)
Official Code
GSoP-block
压缩(Squeeze)
使用 1x1 卷积将输入特征通道降维(c’->c)
计算通道间的协方差矩阵($c\times c$)
由于二次运算涉及到改变数据的顺序,因此对协方差矩阵执行逐行归一化,保留固有的结构信息
激励(Excitation)
对协方差特征图进行非线性逐行卷积得到4c 的结构信息
用一个全连接层调整到输入的通道数c ′维度,
通过sigmoid 函数得到注意力向量与输入进行逐通道相乘,得到输出特征
$$
s = F_{gsop}(X,\theta) = \sigma(WRC(Cov(Conv(X))))
\\ Y=sX
\\ 2nd\ order\ pooling\rightarrow convolution\&MLP\rightarrow sigmoid
$$
在收集全局信息的同时,使用全局二阶池化(GSoP)块对高阶统计数据建模
1
2
3
4
5
6
7
8
9
10
11
12
13
self . isqrt_dim = 256
self . layer_reduce = nn . Conv2d ( 512 * block . expansion , self . isqrt_dim , kernel_size = 1 , stride = 1 , padding = 0 , bias = False )
self . layer_reduce_bn = nn . BatchNorm2d ( self . isqrt_dim )
self . layer_reduce_relu = nn . ReLU ( inplace = True )
self . fc = nn . Linear ( int ( self . isqrt_dim * ( self . isqrt_dim + 1 ) / 2 ), num_classes )
# forward
x = self . layer_reduce ( x )
x = self . layer_reduce_bn ( x )
x = self . layer_reduce_relu ( x )
x = MPNCOV . CovpoolLayer ( x )
x = MPNCOV . SqrtmLayer ( x , 3 )
x = MPNCOV . TriuvecLayer ( x )
FcaNet
文章标题:FcaNet: Frequency Channel Attention Networks
作者:Zequn Qin, Pengyi Zhang, Fei Wu, Xi Li
发表时间:(ICCV 2021)
official code
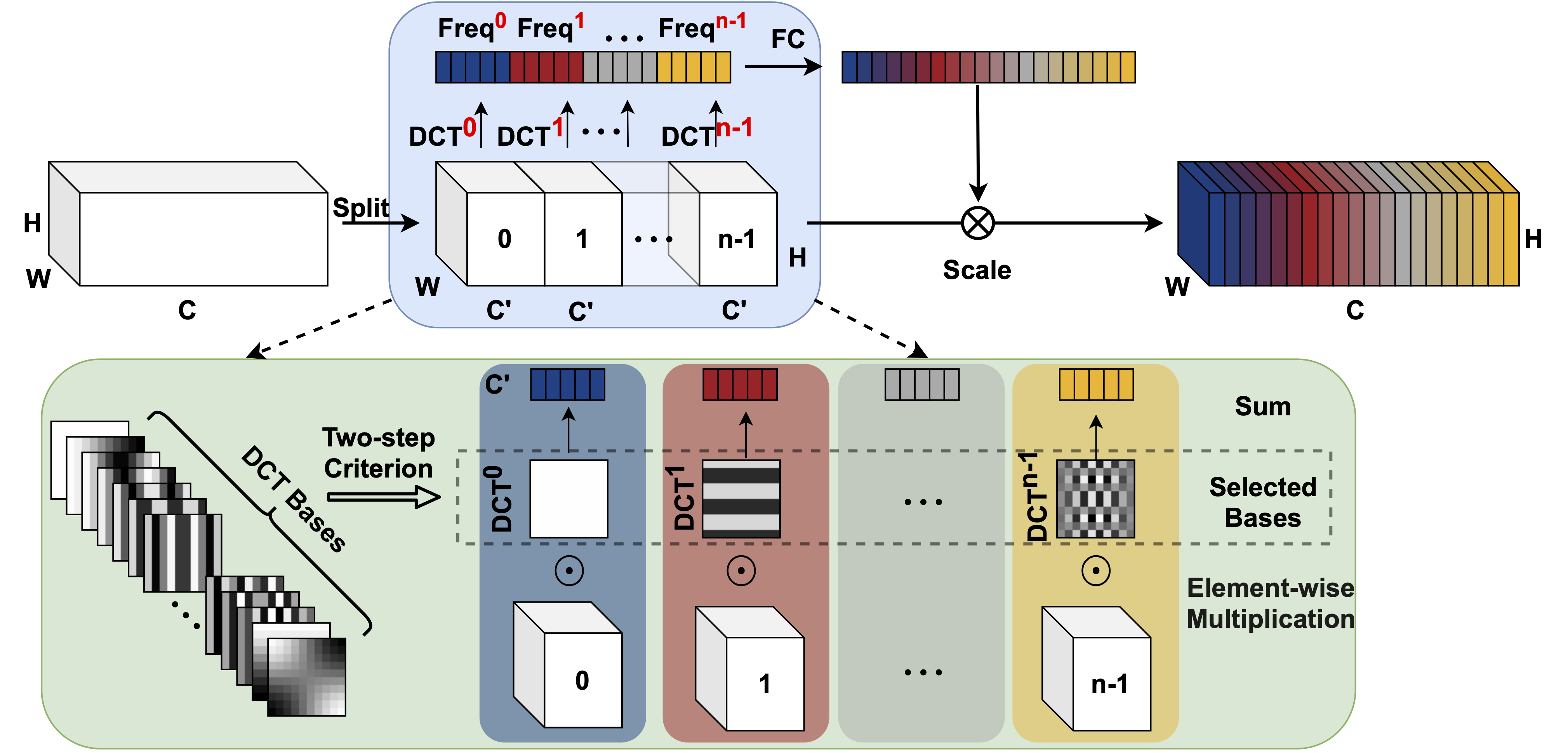
fca_module
GAP是DCT(二维离散余弦变换)的特例
将图像特征分解为不同频率分量的组合。GAP操作仅利用到了其中的一个频率分量。
首先,将输入 X 按通道维度划分为n部分,其中n必须能被通道数整除。
对于每个部分,分配相应的二维DCT频率分量,其结果可作为通道注意力的预处理结果(类似于GAP)
2D DCT可以使用预处理结果来减少计算
$$
s = F_{fca}(X,\theta) = \sigma(W_2\delta(W_1[(DCT(Group(X)))]))
\\ Y=sX
\\ discrete\ cosine\ transform\rightarrow MLP\rightarrow sigmoid
$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# https://github.com/cfzd/FcaNet/blob/aa5fb63505575bb4e4e094613565379c3f6ada33/model/layer.py#L29
class MultiSpectralAttentionLayer ( torch . nn . Module ):
def __init__ ( self , channel , dct_h , dct_w , reduction = 16 , freq_sel_method = 'top16' ):
super ( MultiSpectralAttentionLayer , self ) . __init__ ()
self . reduction = reduction
self . dct_h = dct_h
self . dct_w = dct_w
mapper_x , mapper_y = get_freq_indices ( freq_sel_method )
self . num_split = len ( mapper_x )
mapper_x = [ temp_x * ( dct_h // 7 ) for temp_x in mapper_x ]
mapper_y = [ temp_y * ( dct_w // 7 ) for temp_y in mapper_y ]
# make the frequencies in different sizes are identical to a 7x7 frequency space
# eg, (2,2) in 14x14 is identical to (1,1) in 7x7
self . dct_layer = MultiSpectralDCTLayer ( dct_h , dct_w , mapper_x , mapper_y , channel )
self . fc = nn . Sequential (
nn . Linear ( channel , channel // reduction , bias = False ),
nn . ReLU ( inplace = True ),
nn . Linear ( channel // reduction , channel , bias = False ),
nn . Sigmoid ()
)
def forward ( self , x ):
n , c , h , w = x . shape
x_pooled = x
if h != self . dct_h or w != self . dct_w :
x_pooled = torch . nn . functional . adaptive_avg_pool2d ( x , ( self . dct_h , self . dct_w ))
# If you have concerns about one-line-change, don't worry. :)
# In the ImageNet models, this line will never be triggered.
# This is for compatibility in instance segmentation and object detection.
y = self . dct_layer ( x_pooled )
y = self . fc ( y ) . view ( n , c , 1 , 1 )
return x * y . expand_as ( x )
Billinear attention
文章标题:Bilinear Attention Networks for Person Retrieval
作者:Pengfei Fang , Jieming Zhou , Soumava Kumar Roy , Lars Petersson , Mehrtash Harandi,
发表时间:(ICCV 2019)
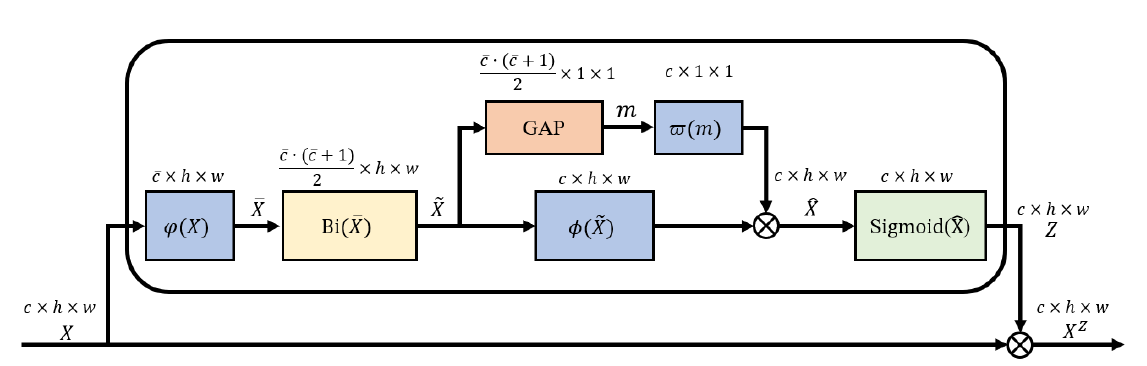
Billinear_attention
线性注意块(双注意),以捕获每个通道内的局部成对特征交互,同时保留空间信息。
双注意采用注意中注意(AiA)机制来捕获二阶统计信息:从内部通道注意的输出计算外部逐点通道注意向量。形式上,给定输入特征映射X,bi注意首先使用双线性池来捕获二阶信息
$$
\widetilde x = Bi(\phi(X))=Vec(Utri(\phi(X)\phi(X)^T))
\\ \hat x = \omega (GAP(\widetilde x))\varphi(\widetilde x)
\\ s = \sigma(\hat x)
\\ Y =sX
$$
改进激励模块
ECANet
文章标题:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
作者:Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wangmeng Zuo, Qinghua Hu
发表时间:(CVPR 2020)
official code
eca_module
$$
s=F_{eca}(X,\theta) = \sigma(Conv1D(GAP(X)))
\\ Y = sX
\\ global\ average\ pooling\rightarrow conv1d\rightarrow sigmoid
$$
使用1D卷积来确定通道之间的相互作用,而不是全连接降维。
只考虑每个通道与其k近邻之间的直接交互,而不是间接对应,以控制模型复杂度
使用交叉验证从通道维度C自适应确定内核大小k,而不是通过手动调整
$k = \psi(C)=|\frac{log_{2}(C)}{\gamma}+\frac{b}{\gamma}|_{odd}$
$\gamma, b$超参数;$|x|_{odd}$:最近的奇数
1
2
3
kernel_size = int ( abs (( math . log ( channel , 2 ) + b ) / gamma ))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
# 为啥源码ResNet固定kernel_size: https://github.com/BangguWu/ECANet/issues/24
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import torch
from torch import nn
from torch.nn.parameter import Parameter
class eca_layer ( nn . Module ):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__ ( self , channel , k_size = 3 ):
super ( eca_layer , self ) . __init__ ()
self . avg_pool = nn . AdaptiveAvgPool2d ( 1 )
self . conv = nn . Conv1d ( 1 , 1 , kernel_size = k_size , padding = ( k_size - 1 ) // 2 , bias = False )
self . sigmoid = nn . Sigmoid ()
def forward ( self , x ):
# feature descriptor on the global spatial information
y = self . avg_pool ( x )
# Two different branches of ECA module
y = self . conv ( y . squeeze ( - 1 ) . transpose ( - 1 , - 2 )) . transpose ( - 1 , - 2 ) . unsqueeze ( - 1 )
# Multi-scale information fusion
y = self . sigmoid ( y )
return x * y . expand_as ( x )
RCAN
文章标题:Image Super-Resolution Using Very Deep Residual Channel Attention Networks
作者:Yulun Zhang, Kunpeng Li
发表时间:(ECCV 2018)
official Code
CA
$$
s=F_{rca}(X,\theta) = \sigma(Conv_U(\delta(Conv_D(GAP(X))))
\\ Y = sX
\\ global\ average\ pooling\rightarrow conv2d\rightarrow Relu \rightarrow conv2d\rightarrow sigmoid
$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class CALayer ( nn . Module ):
def __init__ ( self , channel , reduction = 16 ):
super ( CALayer , self ) . __init__ ()
# global average pooling: feature --> point
self . avg_pool = nn . AdaptiveAvgPool2d ( 1 )
# feature channel downscale and upscale --> channel weight
self . conv_du = nn . Sequential (
nn . Conv2d ( channel , channel // reduction , 1 , padding = 0 , bias = True ),
nn . ReLU ( inplace = True ),
nn . Conv2d ( channel // reduction , channel , 1 , padding = 0 , bias = True ),
nn . Sigmoid ()
)
def forward ( self , x ):
y = self . avg_pool ( x )
y = self . conv_du ( y )
return x * y
DIANet
文章标题:DIANet: Dense-and-Implicit Attention Network
作者:Zhongzhan Huang, Senwei Liang, Mingfu Liang, Haizhao Yang
发表时间:(AAAI 2020)
official Code
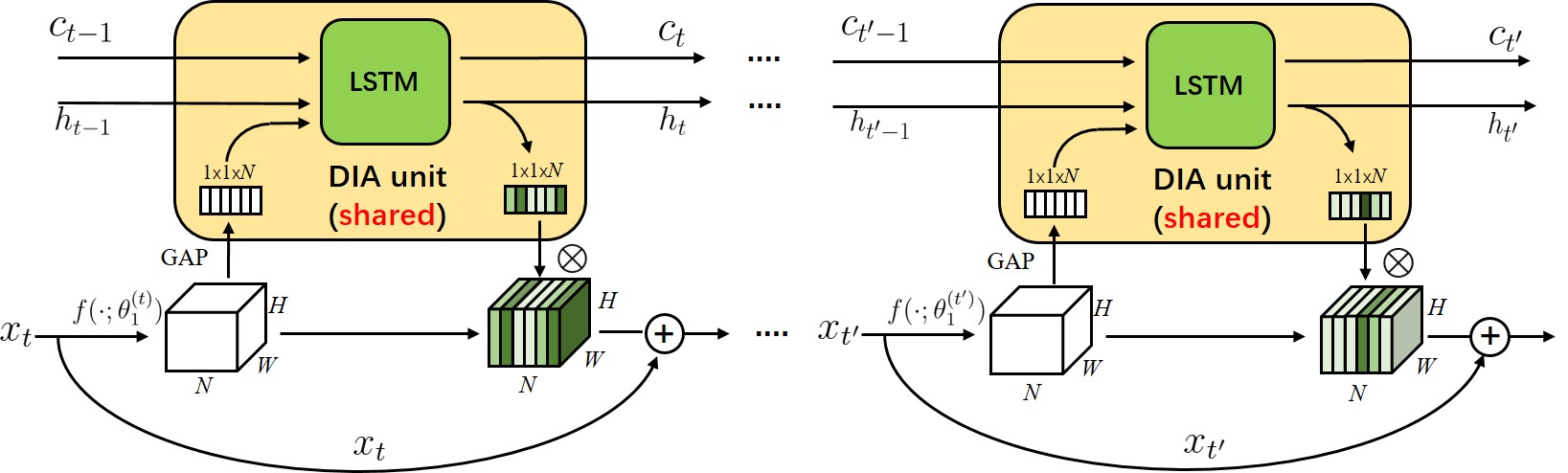
DIA_module
$$
s = F_{dia}(X,\theta) = \delta (LSTM(GAP(X)))
\\ Y = sX + X
\\ global\ average\ pooling\rightarrow LSTM\rightarrow Relu
$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class DIA_Attention ( nn . Module ):
def __init__ ( self , ModuleList , block_idx ):
super ( DIA_Attention , self ) . __init__ ()
self . ModuleList = ModuleList
if block_idx == 1 :
self . lstm = LSTMCell ( 64 , 64 , 1 )
elif block_idx == 2 :
self . lstm = LSTMCell ( 128 , 128 , 1 )
elif block_idx == 3 :
self . lstm = LSTMCell ( 256 , 256 , 1 )
self . GlobalAvg = nn . AdaptiveAvgPool2d (( 1 , 1 ))
self . relu = nn . ReLU ( inplace = True )
self . block_idx = block_idx
def forward ( self , x ):
for idx , layer in enumerate ( self . ModuleList ):
x , org = layer ( x ) # 64 128 256 BatchSize * NumberOfChannels * 1 * 1
# BatchSize * NumberOfChannels
if idx == 0 :
seq = self . GlobalAvg ( x )
# list = seq.view(seq.size(0), 1, seq.size(1))
seq = seq . view ( seq . size ( 0 ), seq . size ( 1 ))
ht = torch . zeros ( 1 , seq . size ( 0 ), seq . size ( 1 )) . cuda () # 1 mean number of layers
ct = torch . zeros ( 1 , seq . size ( 0 ), seq . size ( 1 )) . cuda ()
ht , ct = self . lstm ( seq , ( ht , ct )) # 1 * batch size * length
# ht = self.sigmoid(ht)
x = x * ( ht [ - 1 ] . view ( ht . size ( 1 ), ht . size ( 2 ), 1 , 1 ))
x += org
# x = selrelu(x)
else :
seq = self . GlobalAvg ( x )
# list = torch.cat((list, seq.view(seq.size(0), 1, seq.size(1))), 1)
seq = seq . view ( seq . size ( 0 ), seq . size ( 1 ))
ht , ct = self . lstm ( seq , ( ht , ct ))
# ht = self.sigmoid(ht)
x = x * ( ht [ - 1 ] . view ( ht . size ( 1 ), ht . size ( 2 ), 1 , 1 ))
x += org
# x = self.relu(x)
# print(self.block_idx, idx, ht)
return x #, list
同时改进挤压、激励模块
SRM
文章标题:SRM : A Style-based Recalibration Module for Convolutional Neural Networks
作者:HyunJae Lee, Hyo-Eun Kim, Hyeonseob Nam
发表时间:(ICCV 2019)
Code
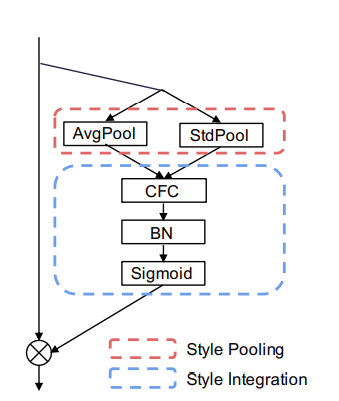
SRM
$$
s = F_{srm}(X,\theta) = \sigma(BN(CFC(SP(X))))
\\ Y = sX
\\ style\ pooling\rightarrow convolution\& MLP\rightarrow sigmoid
$$
利用输入特征的平均值和标准偏差来提高捕获全局信息的能力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class SRMLayer ( nn . Module ):
def __init__ ( self , channel , reduction = None ):
# Reduction for compatibility with layer_block interface
super ( SRMLayer , self ) . __init__ ()
# CFC: channel-wise fully connected layer
self . cfc = nn . Conv1d ( channel , channel , kernel_size = 2 , bias = False ,
groups = channel )
self . bn = nn . BatchNorm1d ( channel )
def forward ( self , x ):
b , c , _ , _ = x . size ()
# Style pooling
mean = x . view ( b , c , - 1 ) . mean ( - 1 ) . unsqueeze ( - 1 )
std = x . view ( b , c , - 1 ) . std ( - 1 ) . unsqueeze ( - 1 )
u = torch . cat (( mean , std ), - 1 ) # (b, c, 2)
# Style integration
z = self . cfc ( u ) # (b, c, 1)
z = self . bn ( z )
g = torch . sigmoid ( z )
g = g . view ( b , c , 1 , 1 )
return x * g . expand_as ( x )
GCT
文章标题:Gated Channel Transformation for Visual Recognition
作者:Zongxin Yang, Linchao Zhu, Yu Wu, Yi Yang
发表时间:(CVPR 2020)
official Code
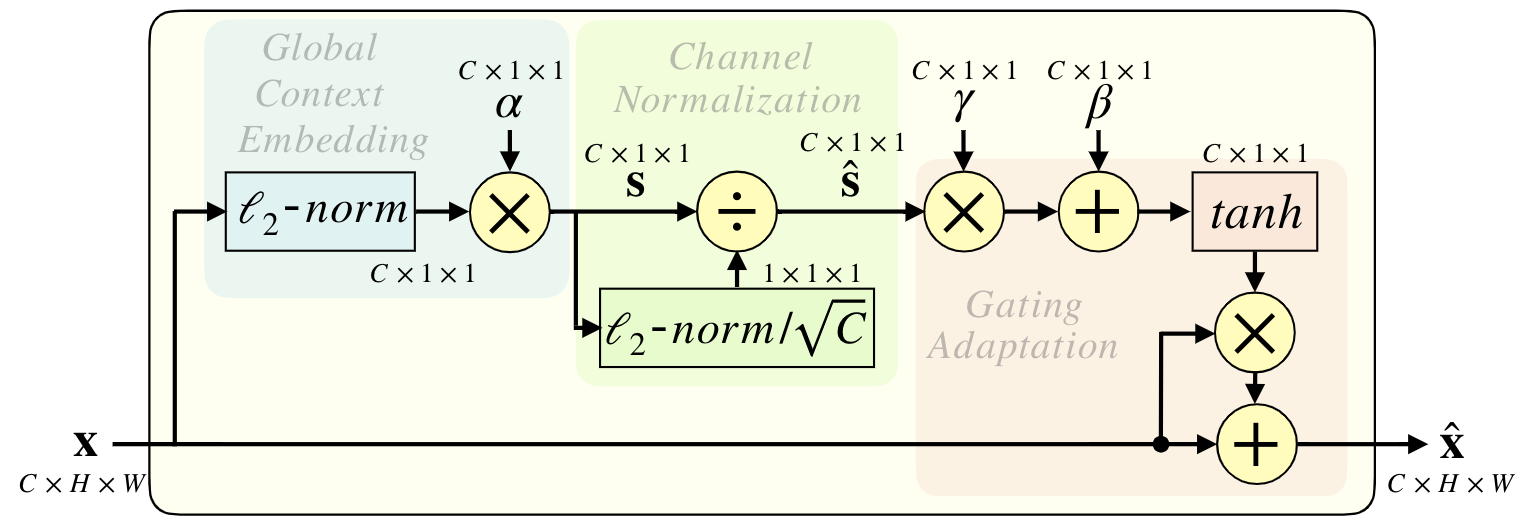
GCT
GCT模块可以促进 shallow layer 特征间的合作,同时,促进 deep layer 特征间的竞争。这样,浅层特征可以更好的获取通用的属性,深层特征可以更好的获取与任务相关的 discriminative 特征
通过计算每个通道的l2范数 来收集全局信息。
利用可学习向量$\alpha$对特征进行缩放。然后通过通道归一化,采用竞争机制来实现信道间的交互。
$$
s = F_{gct}(X,\theta)=tanh(\gamma CN(\alpha Norm(X))+\beta)
\\ Y = sX+X
\\ computer\ L2norm\ on \ spatial\rightarrow channel\ normalization\rightarrow tanh
$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class GCT ( nn . Module ):
def __init__ ( self , num_channels , epsilon = 1e-5 , mode = 'l2' , after_relu = False ):
super ( GCT , self ) . __init__ ()
self . alpha = nn . Parameter ( torch . ones ( 1 , num_channels , 1 , 1 ))
self . gamma = nn . Parameter ( torch . zeros ( 1 , num_channels , 1 , 1 ))
self . beta = nn . Parameter ( torch . zeros ( 1 , num_channels , 1 , 1 ))
self . epsilon = epsilon
self . mode = mode
self . after_relu = after_relu
def forward ( self , x ):
if self . mode == 'l2' :
embedding = ( x . pow ( 2 ) . sum (( 2 , 3 ), keepdim = True ) + self . epsilon ) . pow ( 0.5 ) * self . alpha
norm = self . gamma / ( embedding . pow ( 2 ) . mean ( dim = 1 , keepdim = True ) + self . epsilon ) . pow ( 0.5 )
elif self . mode == 'l1' :
if not self . after_relu :
_x = torch . abs ( x )
else :
_x = x
embedding = _x . sum (( 2 , 3 ), keepdim = True ) * self . alpha
norm = self . gamma / ( torch . abs ( embedding ) . mean ( dim = 1 , keepdim = True ) + self . epsilon )
else :
print ( 'Unknown mode!' )
sys . exit ()
gate = 1. + torch . tanh ( embedding * norm + self . beta )
return x * gate
SoCA
文章标题:Second-order Attention Network for Single Image Super-Resolution
作者:Tao Dai1,2, Jianrui Cai , Yongbing Zhang
发表时间:(CVPR 2019) 基于RCAN
official code
SoCA
$$
s=F_{soca}(X,\theta) = \sigma(Conv_U(\delta(Conv_D(GCP(X))))
\\ Y = sX
\\ global\ covariance\ pooling\rightarrow conv2d\rightarrow Relu \rightarrow conv2d\rightarrow sigmoid
$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
class SOCA ( nn . Module ):
def __init__ ( self , channel , reduction = 8 ):
super ( SOCA , self ) . __init__ ()
# global average pooling: feature --> point
# self.avg_pool = nn.AdaptiveAvgPool2d(1)
# self.max_pool = nn.AdaptiveMaxPool2d(1)
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
# feature channel downscale and upscale --> channel weight
self . conv_du = nn . Sequential (
nn . Conv2d ( channel , channel // reduction , 1 , padding = 0 , bias = True ),
nn . ReLU ( inplace = True ),
nn . Conv2d ( channel // reduction , channel , 1 , padding = 0 , bias = True ),
nn . Sigmoid ()
)
def forward ( self , x ):
batch_size , C , h , w = x . shape # x: NxCxHxW
N = int ( h * w )
min_h = min ( h , w )
h1 = 1000
w1 = 1000
if h < h1 and w < w1 :
x_sub = x
elif h < h1 and w > w1 :
# H = (h - h1) // 2
W = ( w - w1 ) // 2
x_sub = x [:, :, :, W :( W + w1 )]
elif w < w1 and h > h1 :
H = ( h - h1 ) // 2
# W = (w - w1) // 2
x_sub = x [:, :, H : H + h1 , :]
else :
H = ( h - h1 ) // 2
W = ( w - w1 ) // 2
x_sub = x [:, :, H :( H + h1 ), W :( W + w1 )]
## MPN-COV
cov_mat = MPNCOV . CovpoolLayer ( x_sub )
cov_mat_sqrt = MPNCOV . SqrtmLayer ( cov_mat , 5 )
##
cov_mat_sum = torch . mean ( cov_mat_sqrt , 1 )
cov_mat_sum = cov_mat_sum . view ( batch_size , C , 1 , 1 )
y_cov = self . conv_du ( cov_mat_sum )
return y_cov * x