Directly estimate 3D attention map
Residual Attention
文章标题:Residual Attention Network for Image Classification
作者:Fei Wang, Mengqing Jiang, Chen Qian, Shuo Yang, Cheng Li, Honggang Zhang, Xiaogang Wang, Xiaoou Tang
发表时间:(CVPR 2017)
pytorch code
ICCV2021-Residual Attention另一篇不同的记得看
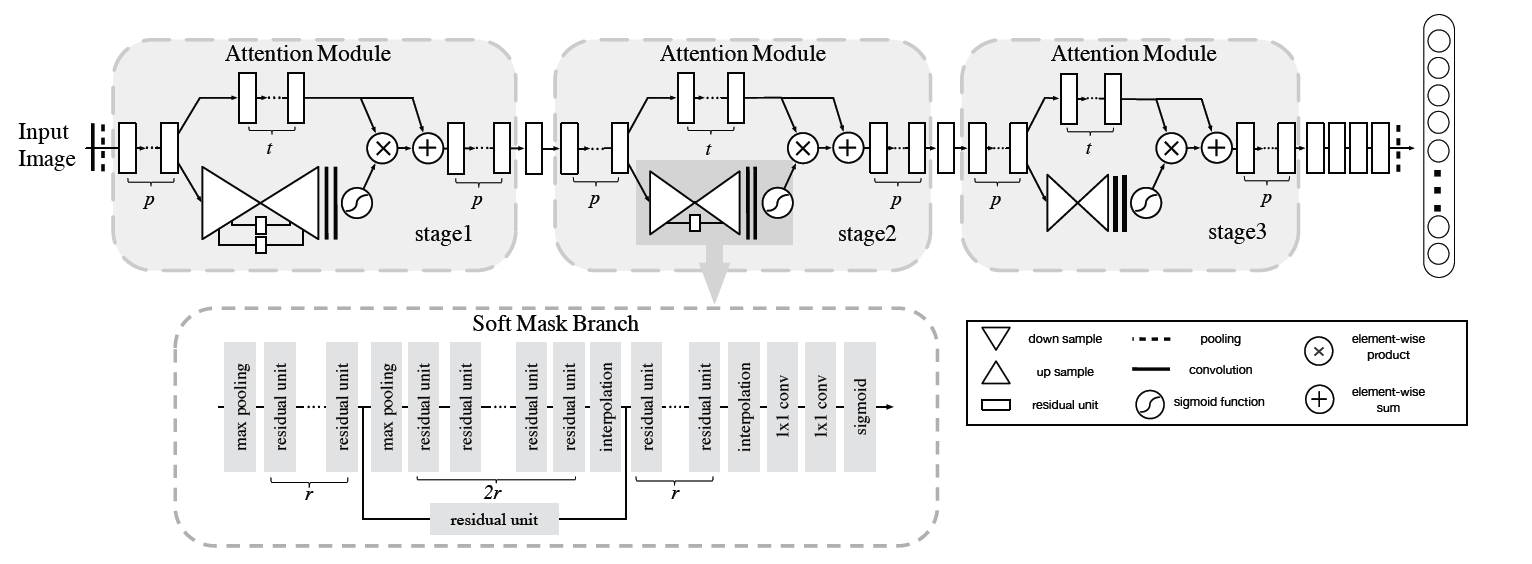
Residual_Attention
每个注意力模块可以分为掩码分支和主干分支。
主干分支处理特征,可以换其他先进模块用f表示。
掩码分支使用bottom-up top-down的结构来学习相同大小的掩码,该掩码对来自主干分支的输出特征进行软加权。
bottom-up结构,在残差单元之后使用几次 maxpooling 来增加感受野,
top-down部分,使用线性插值来保持输出大小与输入特征图相同。两部分之间也有跳跃连接
在两个 1 × 1 卷积层之后,一个 sigmoid 层将输出归一化为 [0, 1]。
采用由多个卷积组成的bottom-up top-down的结构来生成 3D(高度、宽度、通道)注意力图。
$$
s = \sigma(Conv_2^{1\times1}(Conv_1^{1\times1}(h_{up}(h_{down}(X)))))
\\ X_{out} = sf(X)+f(X)
\\ top\_down\ network\rightarrow bottom\_down\ network\rightarrow 1\times1Conv\rightarrow Sigmoid
$$
SimAM
文章标题:Simam: A simple, parameter-free attention module for convolutional neural networks
作者:Lingxiao Yang, Ru-Yuan Zhang, Lida Li, Xiaohua Xie ,
发表时间:(ICML 2021)
pytorch code
simam
无参模型,基于数学与神经科学
1
2
3
4
5
6
7
8
9
10
11
12
| class simam_module(torch.nn.Module):
def __init__(self, channels = None, e_lambda = 1e-4):
super(simam_module, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2,3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2,3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
|
Strip Pooling
文章标题:Strip Pooling: Rethinking spatial pooling for scene parsing
作者:Qibin Hou, Li Zhang, Ming-Ming Cheng, Jiashi Feng (一作Coordinate Attention)
发表时间:(CVPR 2020)
official code
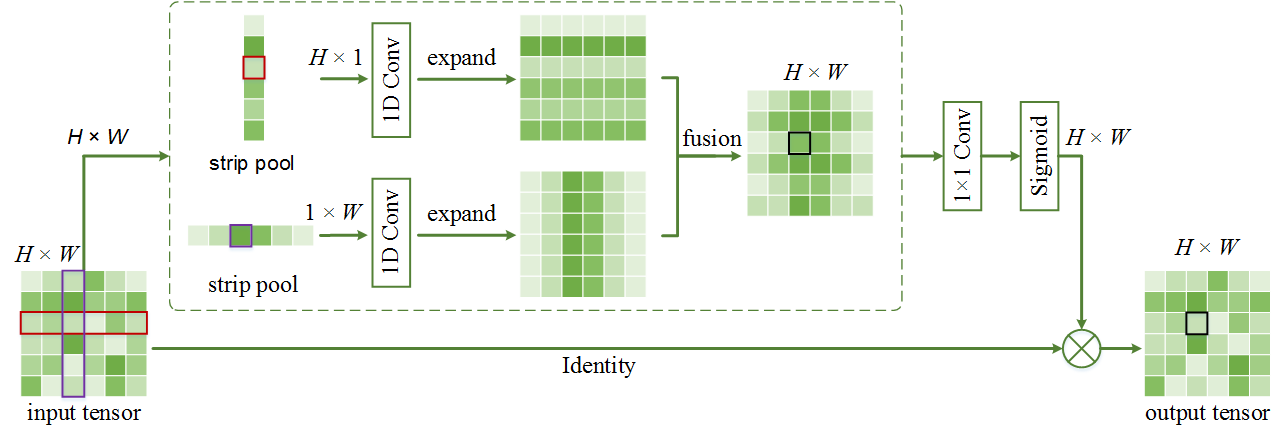
Strip_Pooling
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| #即对应文中的MPM模块
class StripPooling(nn.Module):
"""
Reference:
"""
def __init__(self, in_channels, pool_size, norm_layer, up_kwargs):
super(StripPooling, self).__init__()
#空间池化
self.pool1 = nn.AdaptiveAvgPool2d(pool_size[0])
self.pool2 = nn.AdaptiveAvgPool2d(pool_size[1])
#strip pooling
self.pool3 = nn.AdaptiveAvgPool2d((1, None))
self.pool4 = nn.AdaptiveAvgPool2d((None, 1))
inter_channels = int(in_channels/4)
self.conv1_1 = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 1, bias=False),
norm_layer(inter_channels),
nn.ReLU(True))
self.conv1_2 = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 1, bias=False),
norm_layer(inter_channels),
nn.ReLU(True))
self.conv2_0 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels))
self.conv2_1 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels))
self.conv2_2 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels))
self.conv2_3 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, (1, 3), 1, (0, 1), bias=False),
norm_layer(inter_channels))
self.conv2_4 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, (3, 1), 1, (1, 0), bias=False),
norm_layer(inter_channels))
self.conv2_5 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels),
nn.ReLU(True))
self.conv2_6 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels),
nn.ReLU(True))
self.conv3 = nn.Sequential(nn.Conv2d(inter_channels*2, in_channels, 1, bias=False),
norm_layer(in_channels))
# bilinear interpolate options
self._up_kwargs = up_kwargs
def forward(self, x):
_, _, h, w = x.size()
x1 = self.conv1_1(x)
x2 = self.conv1_2(x)
x2_1 = self.conv2_0(x1)
x2_2 = F.interpolate(self.conv2_1(self.pool1(x1)), (h, w), **self._up_kwargs)
x2_3 = F.interpolate(self.conv2_2(self.pool2(x1)), (h, w), **self._up_kwargs)
x2_4 = F.interpolate(self.conv2_3(self.pool3(x2)), (h, w), **self._up_kwargs)
x2_5 = F.interpolate(self.conv2_4(self.pool4(x2)), (h, w), **self._up_kwargs)
#PPM分支的输出结果
x1 = self.conv2_5(F.relu_(x2_1 + x2_2 + x2_3))
#strip pooling的输出结果
x2 = self.conv2_6(F.relu_(x2_5 + x2_4))
#拼接+1x1卷积
out = self.conv3(torch.cat([x1, x2], dim=1))
return F.relu_(x + out)
|
SCNet
文章标题:Improving convolutional networks with self-calibrated convolutions
作者:Jiang-Jiang Liu, Qibin Hou, Ming-Ming Cheng, Changhu Wang, Jiashi Feng
发表时间:(CVPR 2020)
official code
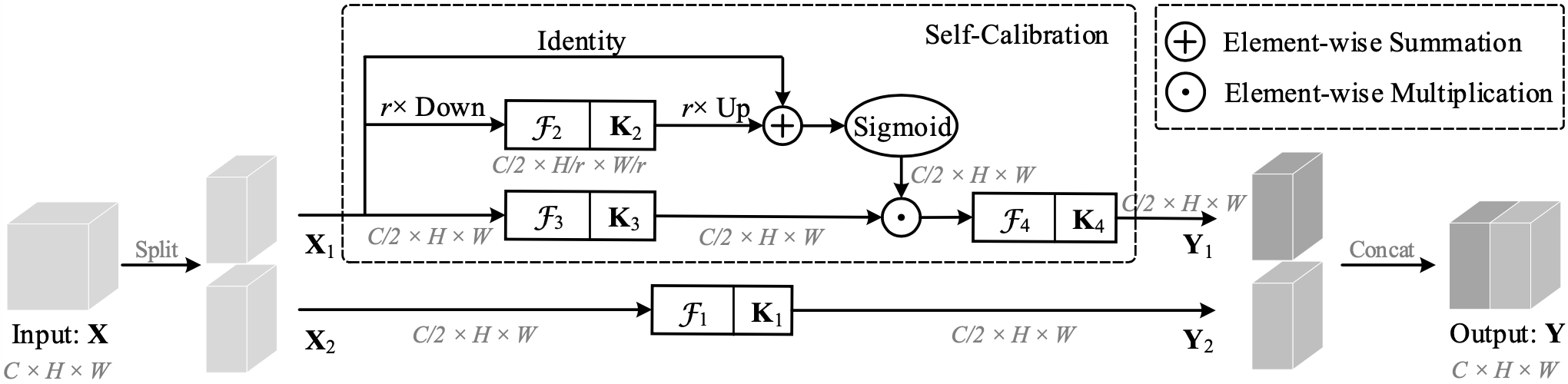
SC_conv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| class SCConv(nn.Module):
def __init__(self, inplanes, planes, stride, padding, dilation, groups, pooling_r, norm_layer):
super(SCConv, self).__init__()
self.k2 = nn.Sequential(
nn.AvgPool2d(kernel_size=pooling_r, stride=pooling_r),
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias=False),
norm_layer(planes),
)
self.k3 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias=False),
norm_layer(planes),
)
self.k4 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride,
padding=padding, dilation=dilation,
groups=groups, bias=False),
norm_layer(planes),
)
def forward(self, x):
identity = x
out = torch.sigmoid(torch.add(identity, F.interpolate(self.k2(x), identity.size()[2:]))) # sigmoid(identity + k2)
out = torch.mul(self.k3(x), out) # k3 * sigmoid(identity + k2)
out = self.k4(out) # k4
return out
|
VAN
文章标题:Visual Attention Network
作者:Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu
发表时间:2022
official code
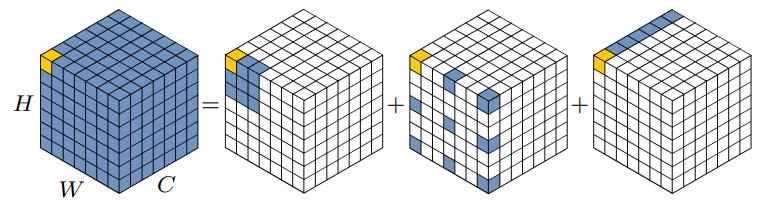
LKA
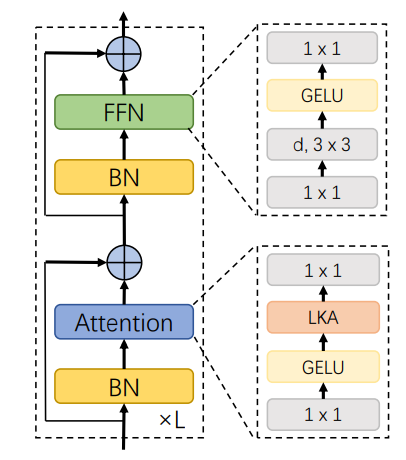
VAN_stage
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| class LKA(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn
class Attention(nn.Module):
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
self.activation = nn.GELU()
self.spatial_gating_unit = LKA(d_model)
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
shorcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x + shorcut
return
|
split channel and spitial attention
CBAM
文章标题:CBAM: Convolutional Block Attention Modul
作者:Sanghyun Woo, Jongchan Park, Joon-Young Lee, In So Kweon
发表时间:(ECCV 2018)
pytorch code
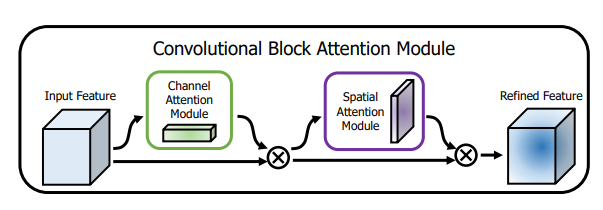
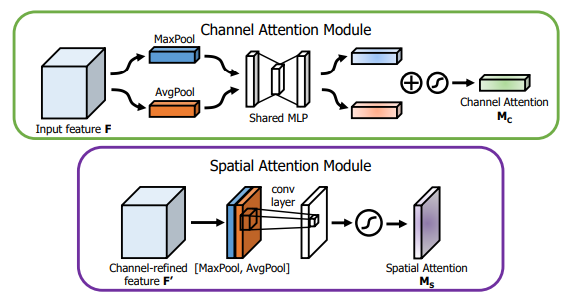
CBAM
空间域中的池化操作
$$
F_{avg}^c=GAP^s(F) \\
F_{max}^c=GMP^s(F)\\
s_c(X)=\sigma(W_1\delta(W_0(F_{avg}^c))+W_1\delta(W_0(F_{max}^c)))\\
M_c(F)=s_cF
$$
通道域中的池化操作
$$
F_{avg}^s=GAP^c(F)\\
F_{max}^s=GMP^c(F)\\
s_s =\sigma(f^{7\times7}([F_{avg}^s;F_{max}^s]))\\
M_s(F)=s_sF
$$$$
F' = M_c(F)\\
Y=M_s(F')
$$
它将通道注意力图和空间注意力图解耦以提高计算效率,并通过引入全局池化来利用空间全局信息
缺点:CBAM 采用卷积来生成空间注意力图,因此空间子模块可能会受到有限的感受野的影响
BAM
文章标题:BAM: Bottleneck Attention Module
作者:Jongchan Park, Sanghyun Woo, Joon-Young Lee, In So Kweon (同CBAM作者)
发表时间:(BMCV 2018)
pytorch code
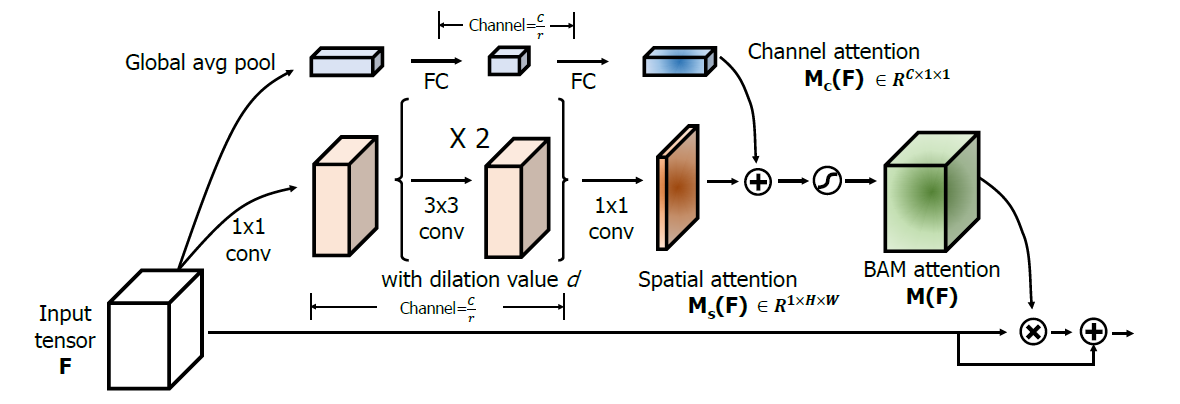
BAM
$$
M_c(F)=BN(W_1(W_0AvgPool(F)+b_0)+b_1)\\
M_s(F)=BN(f_3^{1\times1}(f_2^{3\times3}(f_1^{3\times3}(f_0^{1\times1}(F)))))\\
M(F)=\sigma(M_c(F)+M_s(F))
$$
它使用扩张卷积来扩大空间注意力子模块的感受野,并按照 ResNet 的建议构建瓶颈结构以节省计算成本
为了有效地利用上下文信息,空间注意力分支结合了瓶颈结构和扩张卷积
缺点:尽管扩张卷积有效地扩大了感受野,但它仍然无法捕获远程上下文信息以及编码跨域关系
scSE
文章标题:Recalibrating Fully Convolutional Networks with Spatial and Channel ‘Squeeze & Excitation’ Blocks
Concurrent Spatial and Channel Squeeze & Excitation in Fully Convolutional Networks (MICCAI 2018)
作者:Abhijit Guha Roy, Nassir Navab, Christian Wachinger
发表时间:(TMI 2018)
pytorch code
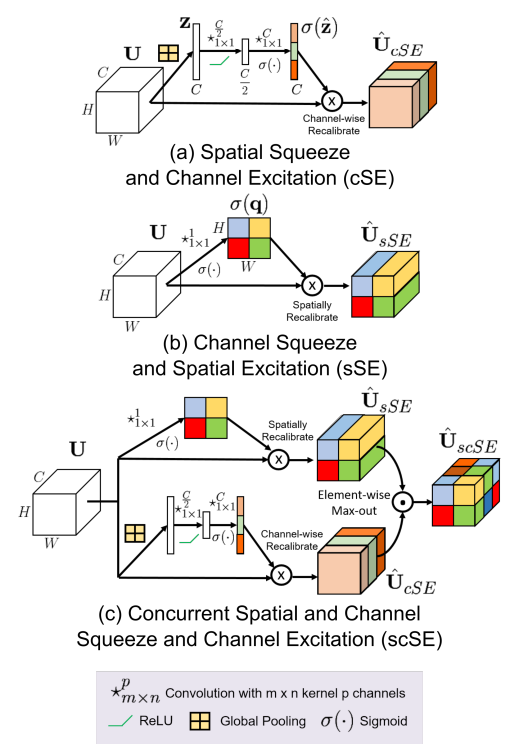
scSE
$$
\hat U_{cSE} = U *\sigma((W_s\delta(W_1GAP(U))))
\\ \hat U_{sSE} = U *\sigma((Conv^{1\times1}(U))
\\ \hat U_{scSE} = f(\hat U_{cSE},\hat U_{sSE})
$$
f 表示融合函数,可以是最大值、加法、乘法或串联
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| '''
https://github.com/qubvel/segmentation_models.pytorch/blob/a6e1123983548be55d4d1320e0a2f5fd9174d4ac/segmentation_models_pytorch/base/modules.py
'''
class SCSEModule(nn.Module):
def __init__(self, in_channels, reduction=16):
super().__init__()
self.cSE = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // reduction, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction, in_channels, 1),
nn.Sigmoid(),
)
self.sSE = nn.Sequential(nn.Conv2d(in_channels, 1, 1), nn.Sigmoid())
def forward(self, x):
return x * self.cSE(x) + x * self.sSE(x)
|
PSA
Polarized Self-Attention: Towards High-quality Pixel-wise Regression
Cross-dimension interaction
Triplet Attention
文章标题:Rotate to attend: Convolutional triplet attention module
作者:Diganta Misra, Trikay Nalamada, Ajay Uppili Arasanipalai, Qibin Hou
发表时间: (WACV 2021)
official code
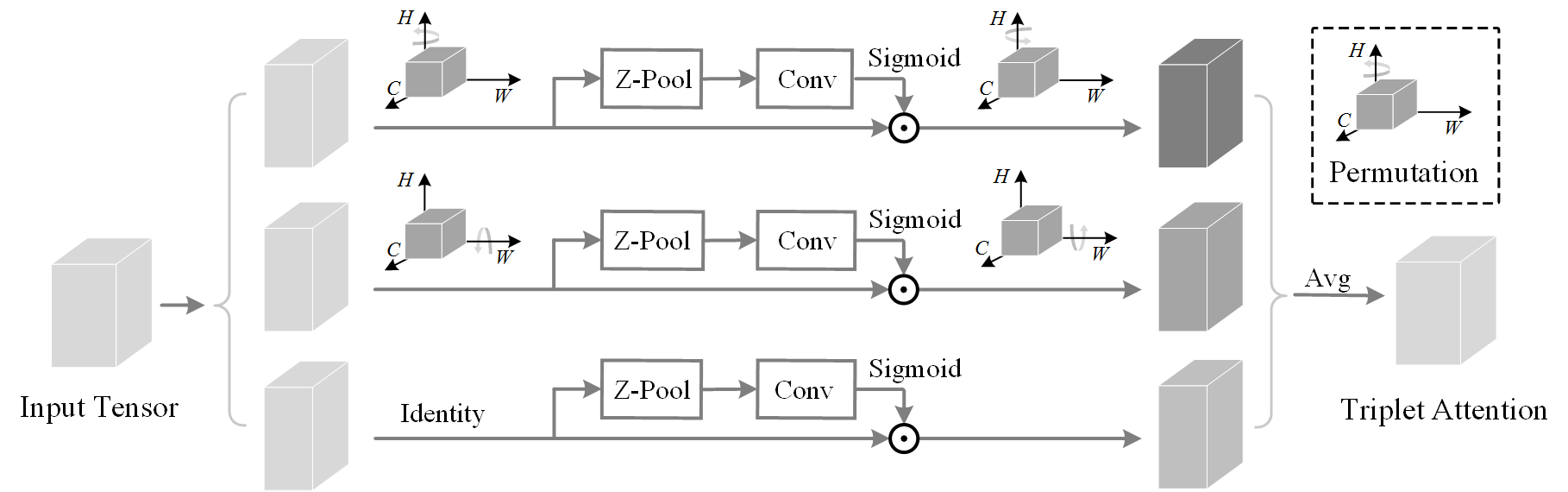
Structural Design of Triplet Attention Module.
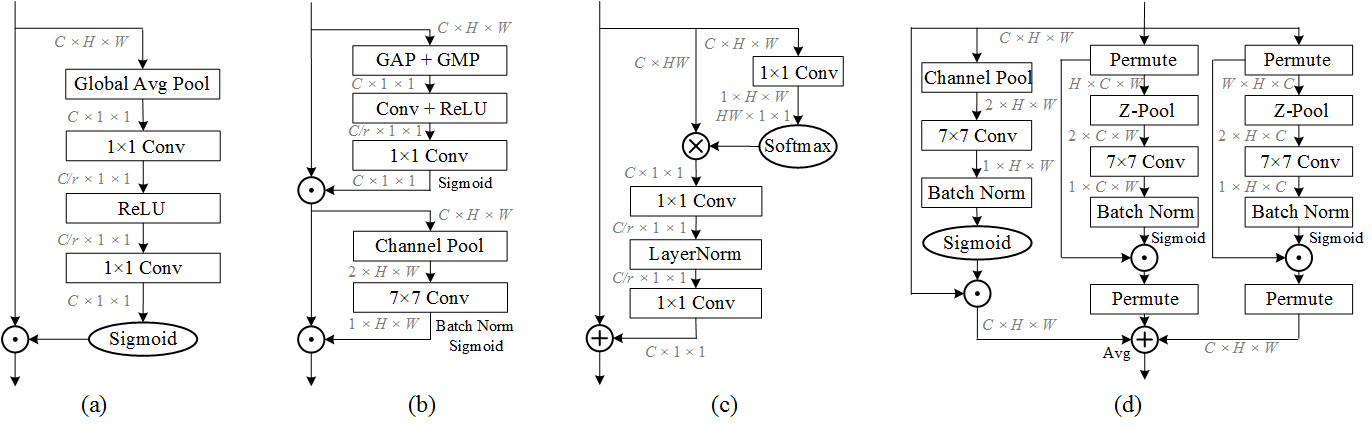
(a). Squeeze Excitation Block. (b). Convolution Block Attention Module (CBAM) . (c). Global Context (GC) block. (d). Triplet Attention
使用三个分支,每个分支都在捕获来自 H、W 和 C 的任意两个域之间的跨域交互。
在每个分支中,沿不同轴的旋转操作应用于输入,然后一个 Z-pool 层负责聚合第零维的信息。
最后,内核大小为 k × k 的标准卷积层对最后两个域之间的关系进行建模。
$$
X_1=Pm_1(X)
\\X_2=Pm_2(X)
\\s_0=\sigma(Conv_0(ZPool(X)))
\\s_1=\sigma(Conv_1(ZPool(X_1)))
\\s_2=\sigma(Conv_2(ZPool(X_2)))
\\ Y=\frac{1}{3}(s_0X+Pm_1^{-1}(s_1X_1)+Pm_2^{-1}(s_2X_2))
$$
其中 $P_{m1},P_{m2}$ 分别表示绕 H 轴和 W 轴逆时针旋转 90°,而$P_{mi}^{-1}$ 表示逆时针旋转。 Z-Pool 沿第零维连接最大池化和平均池化
triplet attention 强调捕获跨域交互的重要性,而不是独立计算空间注意力和通道注意力。这有助于捕获丰富的判别特征表示。
GCBlock = SEBlock + Simplified selfattention
Long-range dependencies
Coordinate Attention
文章标题:Coordinate attention for efficient mobile network design
作者:Qibin Hou, Daquan Zhou, Jiashi Feng
发表时间: (CVPR 2021)
official code
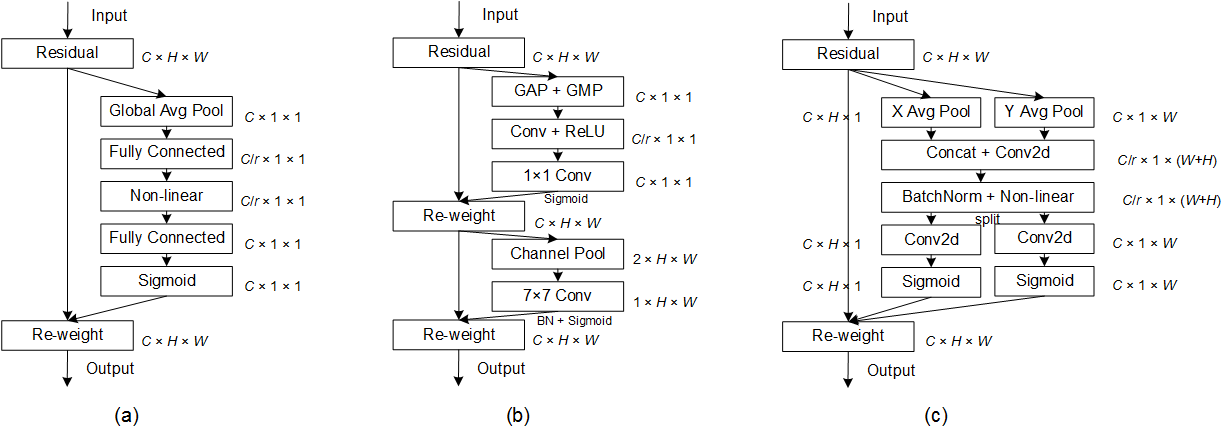
(a) Squeeze-and-Excitation block (b) CBAM (C) Coordinate attention block
将位置信息嵌入到通道注意中,使网络以很少的计算成本关注重要区域
coordinate information embedding
池化内核的两个空间范围$(H,1),(1,W)$对每个通道进行水平和垂直编码。
$z_c^h = GAP^h(X)=\frac{1}{W}\sum_{0\leq i<W}x_c(h,i)$
$z_c^w = GAP^w(X)=\frac{1}{H}\sum_{0\leq j<H}x_c(j,w)$
coordinate attention generation
$$
f=\sigma(BN(Conv_1^{1\times1}([z_c^h;z_c^w])))
\\ f^h,f^w=Split(f)
\\s^h=\sigma(Conv_h^{1\times1}(f^h))
\\s^w=\sigma(Conv_w^{1\times1}(f^w))
\\Y=Xs^hs^w
$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
|
DANet
文章标题:Dual Attention Network for Scene Segmentation
作者:Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang,and Hanqing Lu
发表时间: (CVPR 2019)
official code
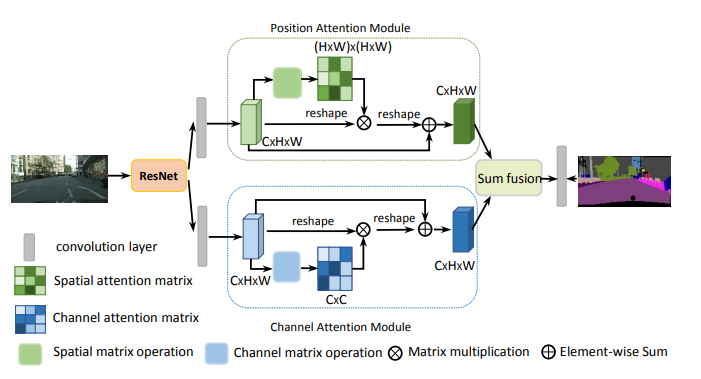
danet
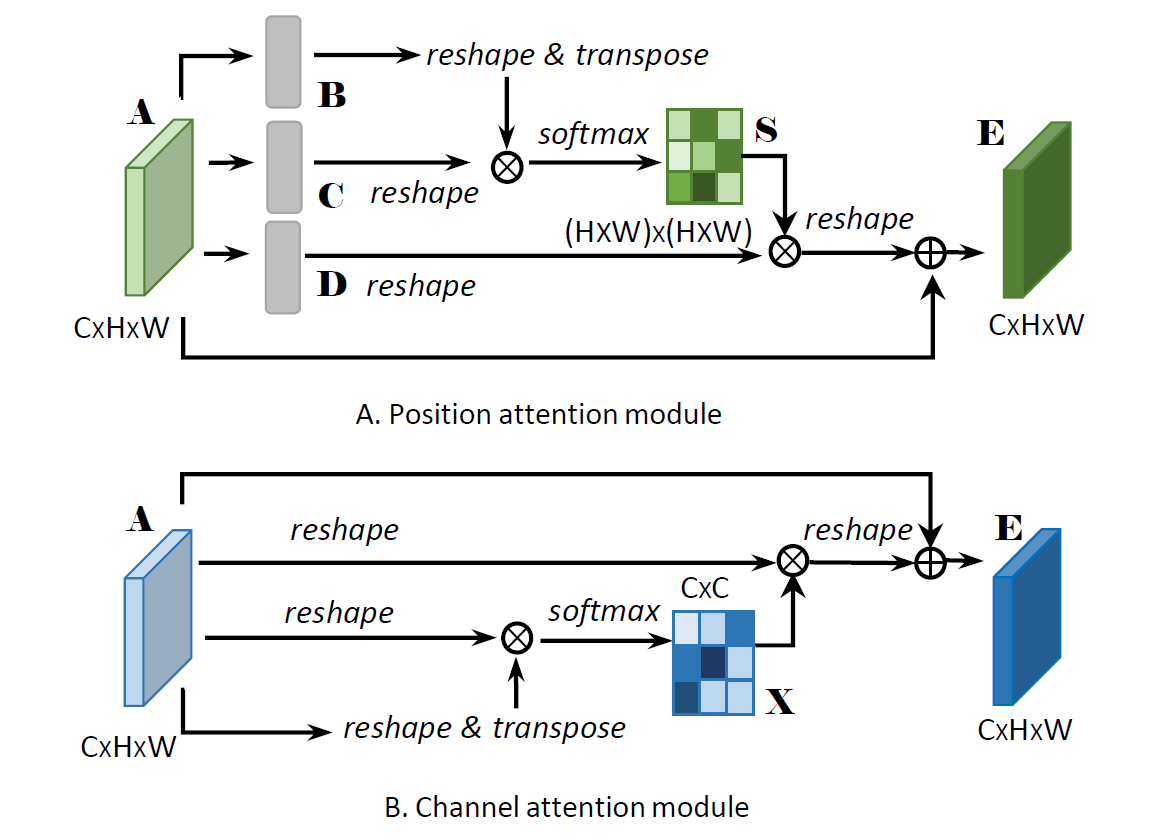
danet
Position attention–> selfattention
$$
Q,K,V=W_qX,W_kX,W_vX
\\Y^{pos} = X+V*Softmax(Q^TK)
\\ Y^{chn} = X + X * Softmax(X^TX)
\\ Y = Y^{pos}+Y^{chn}
$$
Relation-aware attention
RGA
文章标题:Relation-Aware Global Attention for Person Re-identification
作者:Zhizheng Zhang, Cuiling Lan, Wenjun Zeng, Xin Jin, Zhibo Chen
发表时间: (CVPR 2020)
official code
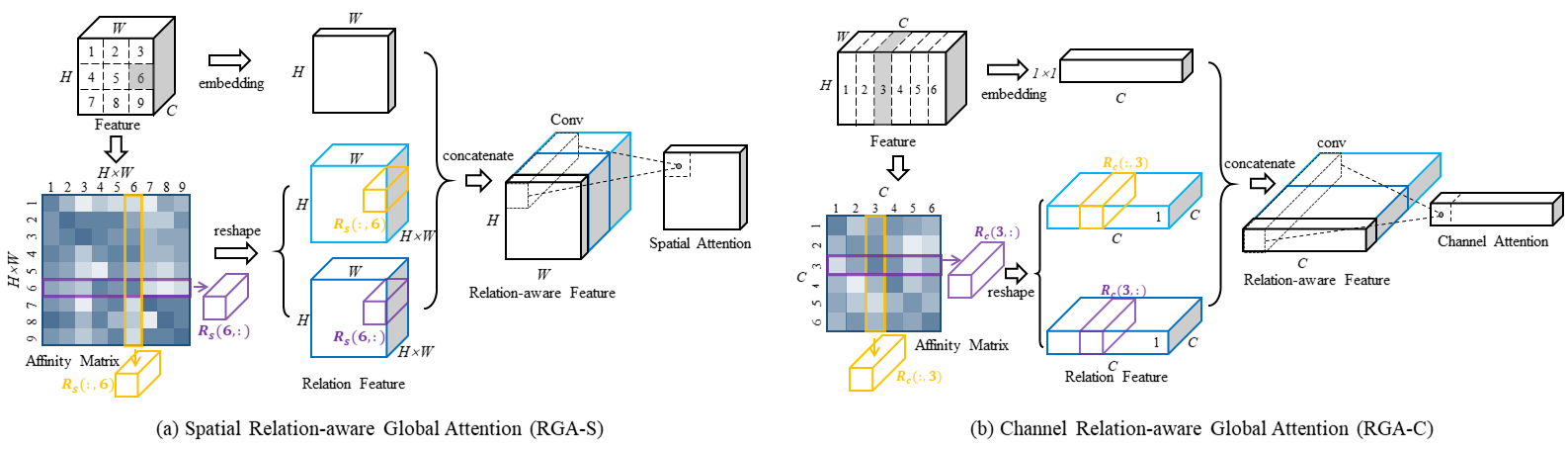
RGA
$$
Q =\delta(W^Q X)\\
K =\delta(W^K X)\\
R=Q^TK\\
r_i=[R(i,:);R(:,i)]\\
Y_i=[g_{avg}^c(\delta(W^{\varphi}x_i));\delta(W^{\phi}r_i)]\\
a_i=\sigma(W_2\delta(W_1y_i))
$$
channel和spital形式一样。位置上的空间注意力得分$a_i$
建议按顺序联合使用它们以更好地捕捉空间和跨通道关系。