BYOL
SwAV
文章标题:Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
作者:Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, Armand Joulin
发表时间:(NIPS 2020)
对比学习和聚类结合
methods
给定同样一张图片,如果生成不同的视角,不同的 views 的话,希望可以用一个视角得到的特征去预测另外一个视角得到的特征
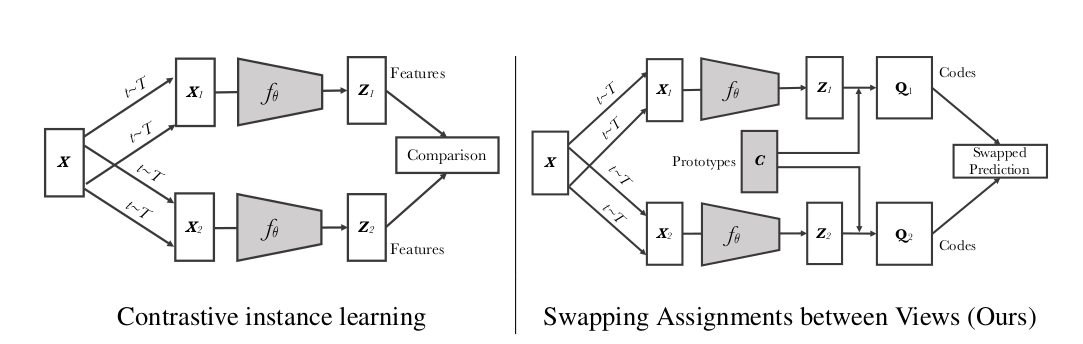
左边:一个图片 $ X$,做两次数据增强得到了$X_1、X_2$,然后所有的样本通过一个编码器 $f_{\theta}$,输出一个特征$Z_1、Z_2$,用这些特征做一个对比学习的 loss
MoCo从memory bank取负样本6万个:这是一种近似做法
直接拿所有图片的特征跟特征做对比有点原始而且有点费资源
SwAV:跟聚类的中心 $C$ (prototype) 比
C 的维度是$d\times k$,d是特征的维度,k是聚类中心个数3,000
一个图片 $ X$,做两次数据增强得到了$X_1、X_2$,然后所有的样本通过一个编码器 $f_{\theta}$,输出一个特征$Z_1、Z_2$,先通过clustering让特征 $Z$ 和prototype $C$ 生成目标$Q_1、Q_2$;C点乘$Z_1$去预测$Q_2$,换位预测
multi crop
思想:全局的和这个局部的特征都要关注
过去的方法:用的两个crop,一个正样本对$X_1、X_2$两个图片
一个图片$X$,先把它resize 到$256\times 256$,然后随机crop两个$224\times 224$的图片当成 $X_1、X_2$
SwAV:大的crop抓住的是整个场景的特征,如果更想学习这些局部物体的特征,最好能多个 crop,去图片里crop一些区域,这样就能关注到一些局部的物体
但是增加crop,会增加模型的计算复杂度,因为相当于使用了更多的正样本
进行取舍:把这个crop变得小一点,变成160 ,取2个160的crop去学全局的特征;然后为了增加正样本的数量,为了学一些局部的特征,再去随机选4个小一点crop,大小为$96\times96$
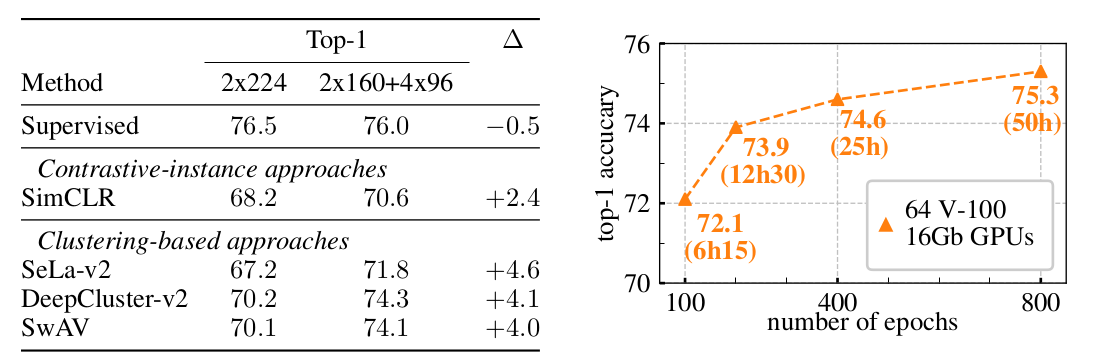
基线模型 2 个$224\times224$,multi crop 2个$160\times160$+4个$96\times96$
SimCLR+ multi crop 涨了2.4个点,如果把 multi crop这个技术用到 BYOL 上有可能BYOL会比SwAV的效果高
如果没有这个multi crop的这个技术其实SwAV的性能也就跟MoCo v2是差不多的
BYOL
文章标题:Bootstrap your own latent: A new approach to self-supervised Learning
作者:Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec
发表时间:(2020)
没有负样本
标题
Bootstrap your own latent: A new approach to self-supervised Learning
Bootstrap: If you bootstrap an organization or an activity, you set it up or achieve it alone, using very few resources.
latent: 特征 hidden、feature、embedding
只有正样本;目的:让所有相似的物体,特征也尽可能的相似
缺陷:有一个躺平解
如果一个模型不论什么输入,都返回同样的输出,那所有的特征都是一模一样的,loss就都是 0
而只有加上负样本的约束,不光相似的物体要有相似的特征;不相似的物体也要有不相似的特征;模型才有动力去继续学(防止模型学到这个躺平解)
如果输出的所有特征都一样,那在负样本的 loss 无穷大;模型更新让正样本和负样本的 loss 都往下降,达到一个最优解
methods
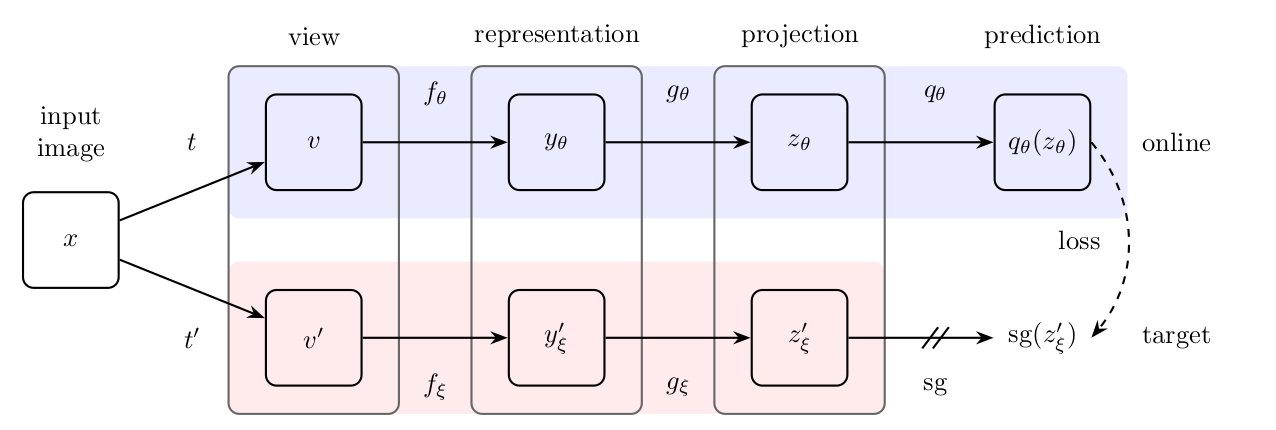
前向过程
一个mini-batch 式的图片 $x$,做两次数据增强得到了$v、v’$;
$v$ 通过编码器 $f_\theta$ 得到特征$y_\theta$;$v’$ 通过编码器 $f_\xi$ 得到特征$y’_\xi$;输出2048维(ResNet50)
$f_\theta$ 和 $f_\xi$ 使用同样的网络架构(ResNet50);参数不同。$f_\theta$ 随着梯度更新而更新;$f_\xi$ 跟 MoCo 一样,使用动量编码器,以 moving average 形式更新
$y_\theta$通过 $g_\theta$ 得到特征$z_\theta$; $y’\xi$ 通过 $g\xi$ 得到特征$z’_\xi$;输出256维
$g_\theta$ 和 $g_\xi$ 使用同样的网络架构 (fc + BN+ ReLU + fc );参数不同
SimCLR 使用projection head 输出是128维 BYOL使用projector 输出是256维 (两者都是MLP层)
$z_\theta$ 通过 $q_\theta$ 得到新的特征 $q_\theta (z_\theta)$; $q_\theta (z_\theta)$ 和 $sg(z’_\xi)$ 尽可能一致
sg:stop gradient
$g_\theta$ 和 $q_\theta$ 使用同样的网络架构
用自己一个视角的特征去预测另外一个视角的特征
2048维的 $y_\theta$ 做下游任务;损失函数:mean square error loss
推荐阅读
Understanding self-supervised and contrastive learning with “Bootstrap Your Own Latent”(BYOL)
跟BN后的平均图片mode 做对比
使用 BN 会产生样本信息泄漏
原作解释:BYOL works even without batch statistics
BYOL 不需要 batch norm 提供的那些 batch 的这个统计量照样能工作,回应之前博客里提出来假设
SimSiam
文章标题:Exploring Simple Siamese Representation Learning
作者: Xinlei Chen, Kaiming He
发表时间:(2020)
没有负样本,不需要大的batch size, 不需要动量编码器
可以看成是一种 EM 算法,通过这种逐步更新的方式避免模型坍塌
methods
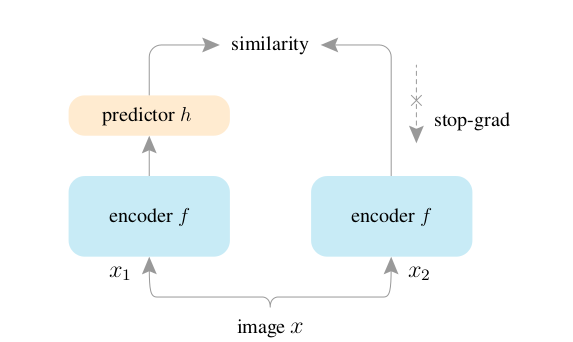 |  |
| simsiam 网络 | 算法 |
前向过程
一个mini-batch 式的图片 $x$,做两次数据增强得到了$x_1、x_2’$;
$x_1, x_2$ 通过编码器 $f$ 得到特征 $z_1, z_2$ ;
$z_1,z_2$ 通过predictor $h$ 得到 $p_1,p_2$;
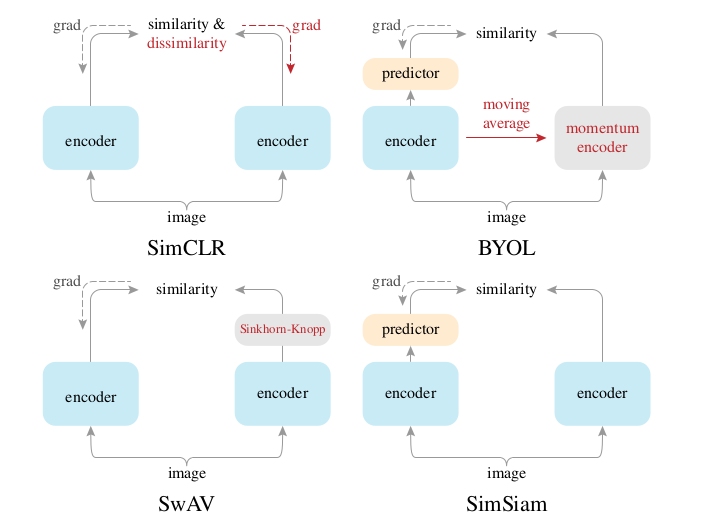
SimCLR :两编码器都有梯度回传;对比任务 SwAV :没有跟负样本;跟聚类中心去比;对比任务 BYOL :用左边呢去预测右边;同时使用了动量编码器;预测任务 SimSiam :没有负样本,不需要大的batch size, 不需要动量编码器;预测任务

batch size
只有 MoCo v2 和 SimSiam 是可以用256的;其它工作都是要用更大的 batch size
负样本
SimCLR 和 MoCo v2 要用负样本
动量编码器
SimCLR 没有用;SimCLR v2用了 SwAV 没有用
epoch越大,Simsiam就不行了。
Barlow Twins
文章标题: Barlow Twins: Self-Supervised Learning via Redundancy Reduction
作者: Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, Stéphane Deny
发表时间: (ICML 2021)
methods
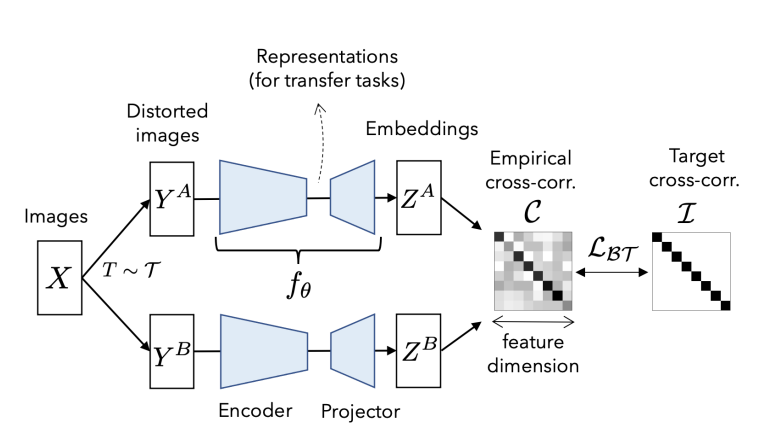 |  |
| Barlow Twins 网络 | 算法 |
损失函数
生成了一个关联矩阵cross correlation matrix;希望这个矩阵能跟一个单位矩阵 identity matrix尽量的相似
希望正样本的相似性尽量都逼近于1;跟别的样本相似性尽可能是0
DINO
文章标题:Emerging Properties in Self-Supervised Vision Transformers
作者: Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, Armand Joulin
发表时间: (2021)
transformer加自监督
一个完全不用任何标签信息训练出的 Vision Transformer ;如果把它的自注意力图进行可视化;发现它能非常准确的抓住每个物体的轮廓 (媲美图像分割)
methods
MoCo:左边的网络叫做 query 编码器;右边叫做 key 编码器 BYOL :左边的网络叫做 online network;右边叫做 target network DINO :左边的网络叫做 student network;右边叫做 teacher network
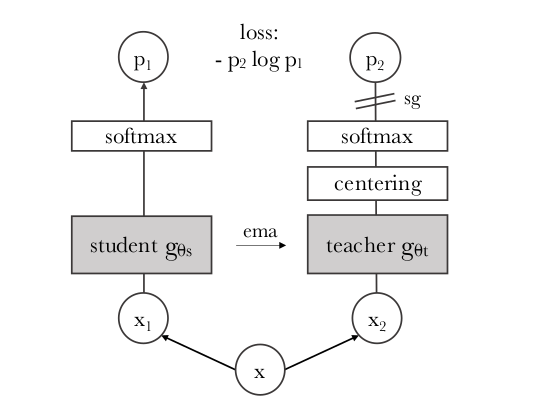 |  |
| DINO 网络 | 算法 |
避免模型坍塌:centering 操作
把整个 batch 里的样本都算一个均值然后减掉这个均值
MoCoV3:随机初始化了一个 patch projection 层;然后冻结使得整个训练过程中都不变