InstDisc
InstDisc
文章标题:Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination
作者:Zhirong Wu, Yuanjun Xiong, Stella Yu, Dahua Lin
发表时间:(CVPR 2018)
这篇论文提出了个体判别任务以及memory bank
把每一个 instance都看成是一个类别,也就是每一张图片都看作是一个类别,目标是能学一种特征能把每一个图片都区分开来
Approach
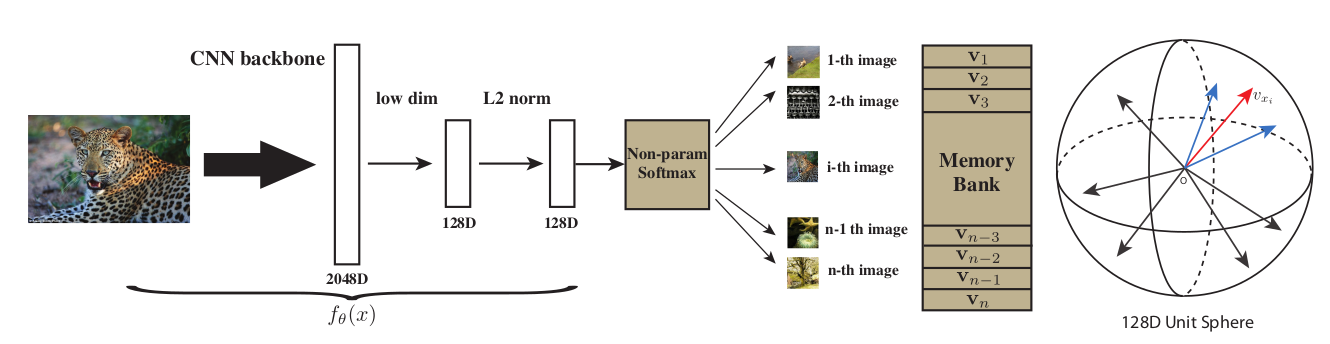
通过一个卷积神经网络把所有的图片都编码成一个特征,这些特征在最后的特征空间里能够尽可能的分开
训练这个卷积神经网络使用的是对比学习
需要有正样本和负样本,根据个体判别这个任务,正样本就是这个图片本身(可能经过一些数据增强),负样本就是数据集里所有其它的图片
把所有图片的特征全都存到memory bank 里,也就是一个字典(ImageNet数据集有128万的图片,memory bank里要存128万行,也就意味着每个特征的维度不能太高,否则存储代价太大了,本文用的是128维)
前向过程:
- 假如batch size是256,有256个图片进入到编码器中,通过一个 ResNet50,最后的特征维度是2048维,然后把它降维降到128维,这就是每个图片的特征大小
- batch size 是 256 的话意味着有256个正样本,负样本从 memory bank 里随机地抽一些负样本出来。本文负样本个数4096
- 用NCE loss 计算对比学习的目标函数
- 更新网络后,把 mini batch里的数据样本所对应的那些特征,在 memory bank 里进行更新;不停更新,最后学到这个特征尽可能的有区分性
CPC
文章标题:Representation Learning with Contrastive Predictive Coding)
作者:Aaron van den Oord, Yazhe Li, Oriol Vinyals
发表时间:(2018)

CPC不仅可以处理音频,还可以处理图片、文字以及在强化学习里使用
输入 $x$(一个持续的序列),$t$ 表示当前时刻,$t-i$ 表示过去的时刻,$t+i$ 表示未来的时刻
把之前时刻的输入通过编码器$g_{enc}$,这个编码器返回一些特征,然后把这些特征放进一个自回归的模型$g_{ar}$,每一步最后的输出,就会得到图中红色的方块$c_t$(context representation,代表上下文的一个特征表示),如果这个上下文的特征表示足够好(它真的包含了当前和之前所有的这些信息),那它应该可以做出一些合理的预测,所以就可以用$c_t$预测未来时刻的这个$z_{t +1}、z_{t + 2}$(未来时刻的特征输出)
一般常见的自回归模型,就是 RNN 或者 LSTM的模型
对比学习的体现
- 正样本:未来的输入通过编码器以后得到的未来时刻的特征输出,这相当于做的预测是 query,而真正未来时刻的输出是由输入决定的,相对于预测来说是正样本;
- 负样本:比较广泛,比如可以任意选取输入通过这个编码器得到输出,它都应该跟预测是不相似的。
CPC V2用了更大的模型、用了更大的图像块、做了更多方向上的预测任务,把batch norm 换成了 layer norm,而使用了更多的数据增强。
InvaSpread
文章标题:Unsupervised Embedding Learning via Invariant and Spreading Instance Feature
作者:Mang Ye, Xu Zhang, Pong C. Yuen, Shih-Fu Chang
发表时间:(CVPR 2019)
一个编码器的端到端对比学习
可以被理解成是 SimCLR 的一个前身,它没有使用额外的数据结构去存储大量的负样本,它的正负样本就是来自于同一个 mini bach,只用一个编码器进行端到端的学习。
为什么它没有取得 SimCLR 那么好的结果呢?字典必须足够大,也就是说在做对比学习的时候,负样本最好是足够多,而本文的的 batch size 就是256,也就意味着它的负样本只有500多个,再加上它还缺少像 SimCLR 那样那么强大的数据增广以及最后提出的那个 mlp projector。
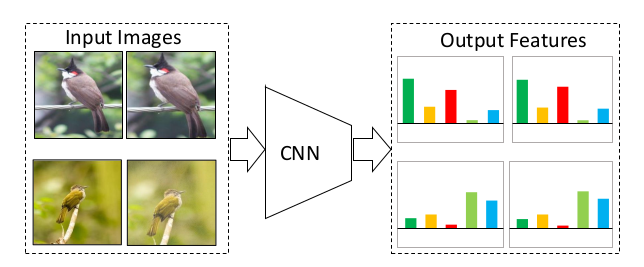
同样的图片通过编码器以后,它的特征应该很类似,不同的图片,它的特征出来就应该不类似,这就是题目中说的invariant和 spreading
对于相似的图片、相似的物体,特征应该保持不变性,但是对于不相似的物体或者完全不沾边的物体,特征应该尽可能的分散开
Method
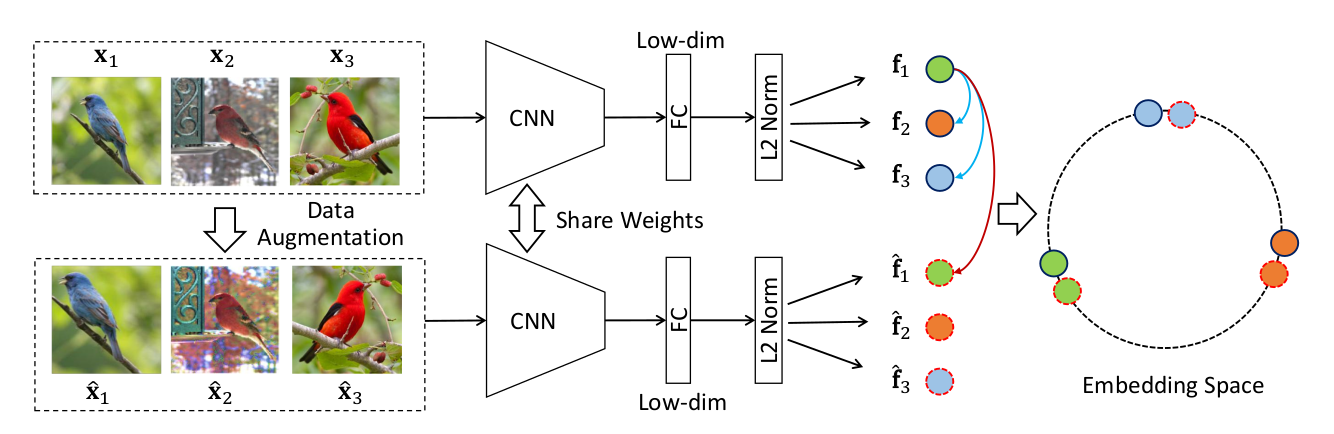
前向过程:
如果 batch size 是256,一共有256个图片,经过数据增强,又得到了256张图片
对于 $x_1 $这张图片来说, $\hat x_1$就是它的正样本,它的负样本是所有剩下的这些图片(包括原始的图片以及经过数据增强后的图片),
正样本是256,负样本是$(256 - 1) \times 2$,就是除去样本本身之外 mini-batch 剩下的所有样本以及它经过数据增强后的样本。
和 InstDisc 的区别:InstDisc中,正样本虽然是256,负样本却是从一个 memory bank 里抽出来的,用的负样本是4096甚至还可以更大
通过编码器以后,再过一层全连接层进行降维至128维;图中绿色的球在最后的特征空间上应该尽可能的接近,但是这个绿色的球跟别的颜色的特征应该尽可能的拉远
所用的目标函数也是 NCE loss 的一个变体
CMC
文章标题:Contrastive Multiview Coding
作者:Yonglong Tian, Dilip Krishnan, Phillip Isola
发表时间:(2019)
多视角下的对比学习
CMC正样本:一个物体的很多个视角
工作目的就是去增大互信息(所有的视角之间的互信息)
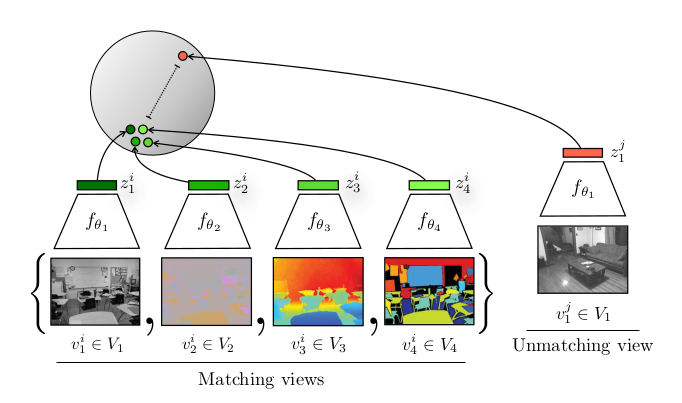
选取的是 NYU RGBD 这个数据集(这个数据集有同时4个view,也就是有四个视角:原始的图像$V_1$、这个图像对应的深度信息$V_2$(每个物体离观察者到底有多远)、SwAV ace normal $V_3$、这个物体的分割图像$V_4$)
CMC是第一个或者说比较早的工作去做这种多视角的对比学习,它不仅证明了对比学习的灵活性,而且证明了这种多视角、多模态的这种可行性。
open AI的clip模型:有一个图片,还有一个描述这个图片的文本,那这个图像和文本就可以当成是一个正样本对,就可以拿来做多模态的对比学习
局限性:当处理不同的视角或者说不同的模态时候,可能需要不同的编码器,因为不同的输入可能长得很不一样,这就有可能会导致使用几个视角,有可能就得配几个编码器,在训练的时候这个计算代价就有点高
Transformer有可能能同时处理不同模态的数据