DALL·E·2
目录
DALL·E·2
文章标题:Hierarchical Text-Conditional Image Generation with CLIP Latents |
作者:Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen发表时间:(2022)
CLIP + Diffusion models
title
使用CLIP训练好的特征做层级式的依托于文本的图像生成
层级式:先生成一个小分辨率的图片再多次上采样成高清大图
Methods
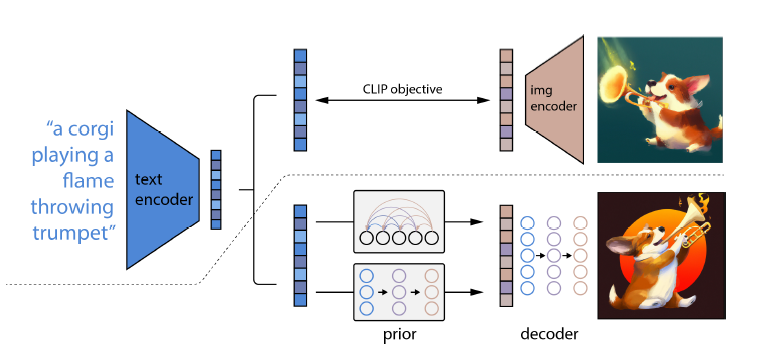
DALL_E2 or unclip
先训练好一个CLIP模型,然后找到图片和文本对$(x,y)$之间的关系之后;给定一个文本,CLIP的文本编码器就可以把这个文本变成一个文本特征$z_t$;
训练一个prior模型$ P(z_i|y)$,输入文本特征,输出类似于CLIP的图像特征
CLIP生成的对应的图像特征$z_i$是用来训练prior做ground truth用的
方法:auto regressive自回归模型和扩散模型(选择了扩散模型)
decoder解码器 $P(x|z_i,y)$ 输入图像特征生成一个完整的图像
扩散模型生成图像;扩散模型大部分时候是U-Net
通过将 CLIP 输出编码和添加 timestep embedding,并将 CLIP编码投影到四个额外的文本token中,token连接到 GLIDE 文本编码器的输出序列
使用classifier-free guidance
guidance信号有10%的时间内把这个CLIP的特征呢设成0,在训练的时候有50%的时间内随机删除文本特征。