AlexNet
AlexNet
文章标题:ImageNet Classification with Deep Convolutional Neural Networks
作者:Alex Krizhevsky, Ilya Sutskever, Hinton
发表时间:(NIPS 2012)
AlexNet是2012年ImageNet图像分类竞赛冠军,首次将深度学习和卷积神经网络用于大规模图像数据集分类,比之前的模型有巨大的性能飞跃,在ILSVRC-2012图像分类竞赛中获得了top-5误差15.3%的冠军成绩,远远优于第二名(top-5错误率为26.2%),在学术界和工业界引起巨大轰动,自此之后,计算机视觉开始广泛采用深度卷积神经网络,模型性能日新月异,并迁移泛化到目标检测、语义分割等其它计算机视觉任务。
AlexNet的作者之一Hinton因为在神经网络和计算机视觉的贡献,获得2019年图灵奖。
AlexNet采用了ReLU激活函数、双GPU模型并行、LRN局部响应归一化、重叠最大池化、数据增强、Dropout正则化等技巧。
AlexNet包含五个卷积层,池化层,Dropout层和三个全连接层,最终通过1000个输出神经元进行softmax分类。
The Dataset
ImageNet
网络对每张图片给出五个预测l类别结果概率从高到低
Top1:概率最高的预测类别为正确标签 Top5:五个预测类别里包含正确标莶
The Architecture
ReLu激活函数
在AlexNet中用的非线性非饱和函数是$f=max(0,x)$,即ReLU。实验结果表明,要将深度网络训练至training error rate达到25%的话,ReLU只需5个epochs的迭代,但tanh单元需要35个epochs的迭代,用ReLU比tanh快6倍。
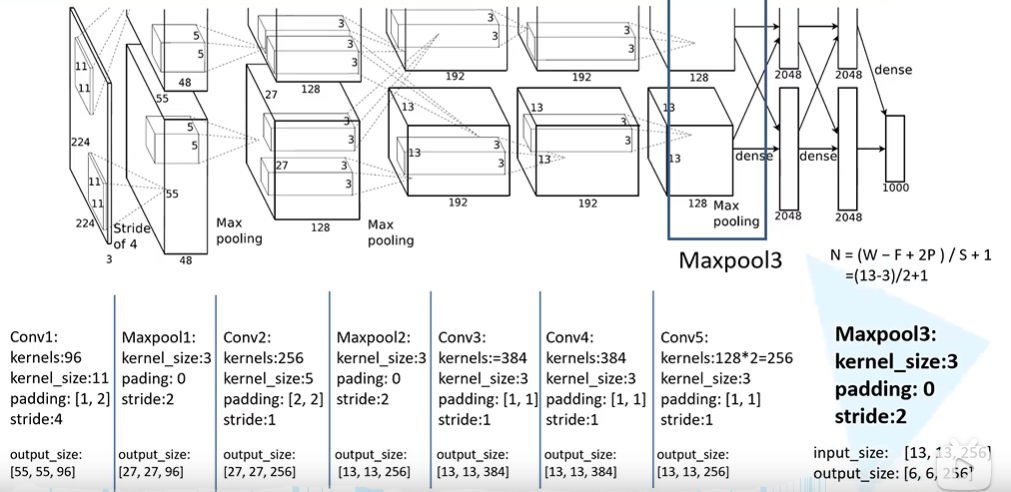
多GPU模型并行
为提高运行速度和提高网络运行规模,作者采用双GPU的设计模式。并且规定GPU只能在特定的层进行通信交流。其实就是每一个GPU负责一半的运算处理。作者的实验数据表示,two-GPU方案会比只用one-GPU跑半个上面大小网络的方案,在准确度上提高了1.7%的top-1和1.2%的top-5。值得注意的是,虽然one-GPU网络规模只有two-GPU的一半,但其实这两个网络其实并非等价的。
由反向传播原理,显存中不仅存储模型参数还需存储正向传播时每一层batch的中间结果。batch size越大,占显存越大。
双GPU(全参数)的训练时间比单GPU(半参数)更短;单GPU(半参数)模型中最后一个卷积层和全连接层数量和双GPU(全参数)模型相同,因此“半参数”并非真的只有一半的参数。
LRN局部响应归一化
$$ b_{x,y}^i=a_{x,y}^i/(k+\alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^j)^2)^\beta $$$a_{x,y}^i$:代表在feature map中第$i$个通道上$(x,y)$位置上的值;k常数防止分母为0;
N:feature map 通道数(本层卷积核个数)n:表示相邻的几个卷积核。
$(k,\alpha,\beta,n)=(0,1,1,N)$代表普通沿所有通道归一化;
$(k,\alpha,\beta,n)=(2,10^{-4},0.75,5)$AlexNet所用参数他们的值是在验证集上实验得到的。
这种归一化操作实现了某种形式的横向抑制(兴奋的神经元对周围神经元有抑制作用)。
卷积核矩阵的排序是随机任意,并且在训练之前就已经决定好顺序。这种LRN形成了一种侧向抑制机制。
Overlapping Pooling
池层是相同卷积核领域周围神经元的输出。池层被认为是由空间距离s个像素的池单元网格的组成。也可以理解成以大小为步长对前面卷积层的结果进行分块,对块大小为的卷积映射结果做总结。Pooling单元在总结提取特征的时候,其输入会受到相邻pooling单元的输入影响,也就是提取出来的结果可能是有重复的(对max pooling而言)。而且,实验表示使用带交叠的Pooling的效果比的传统要好,在top-1和top-5上分别提高了0.4%和0.3%,在训练阶段有避免过拟合的作用。
后来的paper不采用这种方法
总体结构
conv1–>ReLu–>Pool–>LRN;conv2–>ReLu–>Pool–>LRN;conv3–>ReLu;conv4–>ReLu;conv5–>ReLu–>Pool
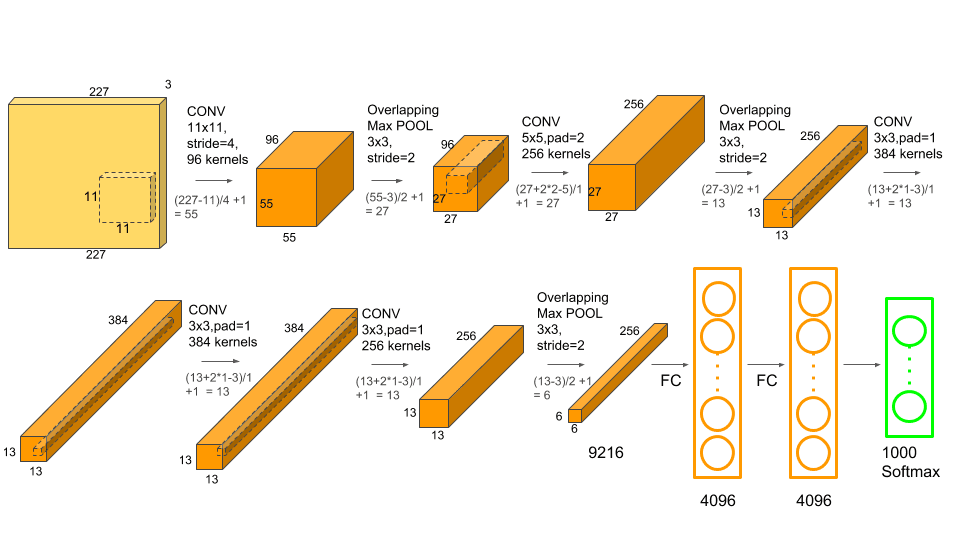
输入数据为$227\times227\times3$图像,通过Conv1,卷积核为,$11\times11$,卷积核个数为96个,步长为4,Padding为2,输出特征图$55\times55\times96$。$N=(W-F+2P)/s+1=[227-11+(2\times2)]/4+1=55$
输入数据为$224\times224\times3$图像,通过Conv1,卷积核为$11\times11$,卷积核个数为96个,步长为4,Padding为[1:2](左上各补1个0,右下各补2个0);输出特征图$55\times55\times96$。$N=(W-F+2P)/s+1=[224-11+(1+2)]/4+1=55$
1 2 3 4 5 6tuple:(1,2) # 1代表上下方各补一行零 # 2代表左右两侧各补两列零 nn.ZeroPad2d((1,2,1,2)) # 左侧补一列,右侧补两列((z)) # 上方补一行,下方补两行Maxpooling1滑动窗口$3\times3\times96$,步长为2,padding:0 ;输出特征图$27\times27\times96$。$N=(W-F+2P)/s+1=[55-3+0)]/2+1=27$
池化操作只改变特征图大小,不改变深度。
通过Conv2,卷积核为$5\times5$,卷积核个数为256个,步长为1,Padding为2,输出特征图$27\times27\times256。$$N=(W-F+2P)/s+1=[27-5+(2\times2)]/1+1=27$
Maxpooling2滑动窗口$3\times3\times256$,步长为2,padding:0 ;输出特征图$13\times13\times256$。$N=(W-F+2P)/s+1=[27-3+0)]/2+1=13$
通过Conv3,卷积核为$3\times3$,卷积核个数为384个,步长为1,Padding为1,输出特征图$13\times13\times384$ 。 $N=(W-F+2P)/s+1=[13-3+(2\times1)]/1+1=13$
通过Conv4,卷积核为$3\times3$,卷积核个数为384个,步长为1,Padding为1,输出特征图$13\times13\times384$ 。 $N=(W-F+2P)/s+1=[13-3+(2\times1)]/1+1=13$
通过Conv5,卷积核为$3\times3$,卷积核个数为256个,步长为1,Padding为1,输出特征图$13\times13\times256$ 。 $N=(W-F+2P)/s+1=[13-3+(2\times1)]/1+1=13$
Maxpooling3滑动窗口$3\times3\times256$,步长为2,padding:0 ;输出特征图$6\times6\times256$。$N=(W-F+2P)/s+1=[13-3+0)]/2+1=6$
FC6:$6\times6\times256$进行扁平化处理成为$1\times 9216$,用一个维度为$9216\times4096$矩阵完成输入输出的全连接,输出$1\times 4096$
FC7:用一个维度为$4096\times4096$矩阵完成输入输出的全连接,输出$1\times 4096$
FC8:用一个维度为$4096\times1000$矩阵完成输入输出的全连接,输出$1\times 1000$
Reducing Overfiting
Data Augmentation数据增强
针对==位置==:
训练阶段:随机地从$256\times256$的原始图像中截取$224\times224$大小的区域(水平翻转及镜像),相当于增加了$2*(256-224)^2=2048$倍的数据量。
如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。
测试阶段:取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值
针对==颜色==:
- 对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加些噪声,(修改RGB通道像素值)这个 Trick可以让错误率再下降1%。
Dropout 随机失活
随机:dropout probability (eg: p=0.5)
失活:weight = 0
- 训练阶段:每一个batch随机失活一半的神经元(将神经元输出设置为0)阻断该神经元的前向-反向传播。
- 预测阶段:保留所有神经元,预测结果乘以0.5 。
Dropout减少过拟合的理由
- 模型集成 p=0.5意味着$2^n$个共享权重的潜在网络
- 记忆随即抹去
- 减少神经元之间的联合依赖性
- 有性繁殖 每个基因片段都要与来自另一个随即个体的基因片段协同工作
- 数据增强 总可以找到一个图片使神经网络中间层结果与Dropout后相同 相当于增加了这张图片到数据集里
- 稀疏性
- 等价于正则项
拓展阅读
AlexNet – ImageNet Classification with Deep Convolutional Neural Networks
ZFNet
文章标题:Visualizing and Understanding Convolutional Networks 作者:Matthew D Zeiler,Rob Fergus 发表时间:(CVPR 2013)
纽约大学ZFNet,2013年ImageNet图像分类竞赛冠军模型。提出了一系列可视化卷积神经网络中间层特征的方法,并巧妙设置了对照消融实验,从各个角度分析卷积神经网络各层提取的特征及对变换的敏感性。
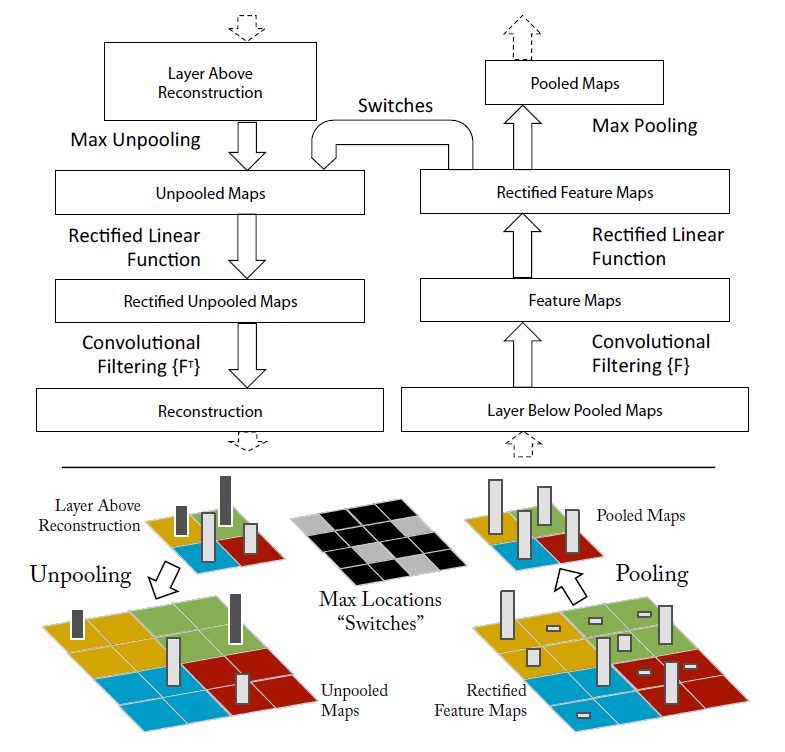
使用反卷积deconvnet,将中间层feature map投射重构回原始输入像素空间,便于可视化每个feature map捕获的特征。
改进AlexNet模型,减小卷积核尺寸,减小步长,增加卷积核,提出ZFNet。
训练过程中不同层特征演化可视化。
图像平移、缩放、旋转敏感性分析。
图像局部遮挡敏感性分析(遮挡同一张狗脸图像的不同部位,分析结果变化)。
图像局部遮挡相关性敏感性分析(遮挡不同狗脸的同一部位,分析相关性)。
ZFNet在ImageNet2012图像分类竞赛结果。
模型迁移学习泛化到其它数据集的性能分析:Caltech-101、Caltech-256、PASCAL VOC2012。
去除全连接层和卷积层后模型性能分析。
模型各层特征对分类任务的有效性分析。

拓展阅读
原作者讲解视频(视频中有几页ppt播放顺序错误)