ConvNeXt
ConvNeXt
文章标题:A ConvNet for the 2020s 作者:Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie
发表时间:2022
ResNet的Transformer版
Modernizing a ConvNet: a Roadmap路线图

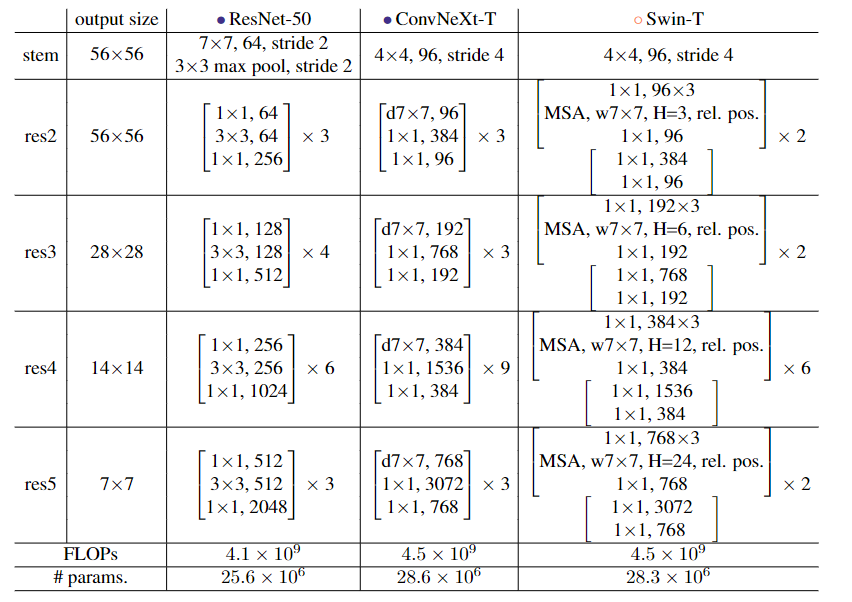
Detailed Architectures
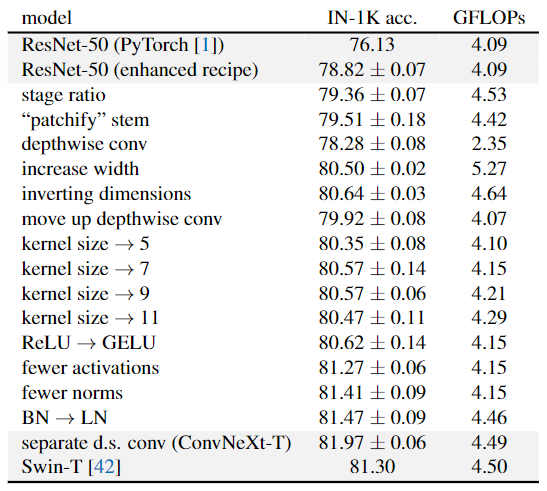 | 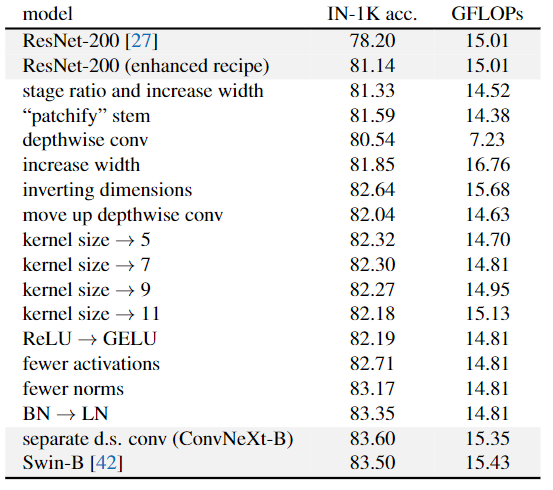 |
| Detailed results for modernizing a ResNet-50 | Detailed results for modernizing a ResNet-200 |
macro design 宏观设计
Changing stage compute ratio (78.8%—>79.4%)
每个stage的block数量:(3,4,6,3)->(3,3,9,3) 和为Swin-T的stage(1,1,3,1)一致。
Changing stem to “Patchify” (79.4%—>79.5%)
输入224;经历stem,导致$4\times$下采样成56;卷积计算: $ (W-F+2P)/s+1$
传统:stride=2的$7\times7$卷积(padding为3)—>stride=2的$3\times3$max pooling(padding为1) $(224-7+2\cdot3)/2+1=112–>(112-3+2)/2=56$(pytorch向下取整)
Swin-T:stride=4的$4\times4$卷积 $(224-4)/4+1=56$
ConvNeXt :stride=4的$4\times4$卷积
1 2 3 4 5 6 7 8 9 10# 标准ResNet stem = nn.Sequential( nn.Conv2d(in_chans, dims[0], kernel_size=7, stride=2,padding=3), nn.MaxPool2d(kernel_size=3, stride=2, padding=1) ) # ConvNeXt stem = nn.Sequential( nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4), LayerNorm(dims[0], eps=1e-6, data_format="channels_first") )
ResNeXt (79.4%—>80.5%)
Use more groups, expand width 使用更多的组,扩大宽度
bottleneck的$3\times3$卷积—>depthwise conv(组数等于通道数)
将网络宽度增加到与Swin-T的通道数量相同(从64到96)
Inverted bottleneck (80.5%—>80.6%)

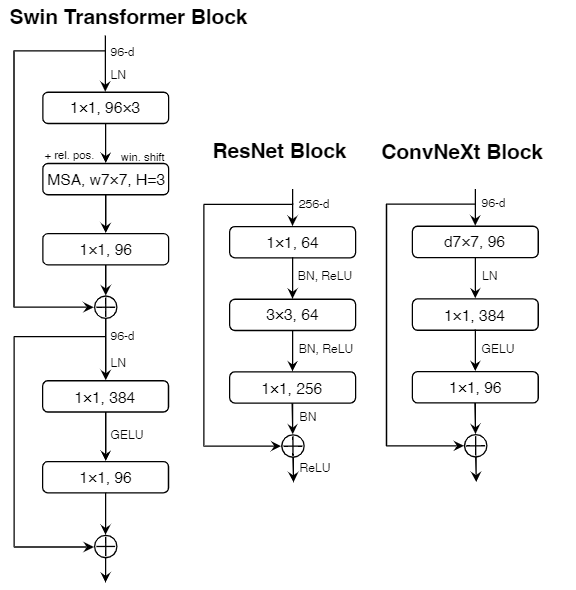
(a) ResNeXt block; (b) inverted bottleneck block ; (c) b的深度卷积位置上移
d=4(维度系数)
large kernel size
- 使用[c图](###Inverted bottleneck (80.5%—>80.6%))深度卷积位置上移后的倒残差结构 (退化到79.9%)
- 使用$7\times7$卷积 (79.9% (3×3) —> 80.6%) (7×7)
various layer-wise micro designs各种层级的微观设计
| |
用GELU代替RELU (80.6%不变)
和Swin-T一样只用一个GELU (80.6%—>81.3%)
只留下一个BN层(比Swin-T还少:在Block开始添加一个额外的BN层并不能提高性能)(81.3%—>81.4%)
用LN代替BN (81.4%—>81.5%)
直接在ResNet基础上替换成LN,效果并不好。
单独的下采样层 (81.5%—>82%)
ResNet:stride=2的$3\times3$卷积,有残差结构的block则在短路连接中使用stride=2的$1\times1$卷积
Swin-T:单独采样层
ConvNeXt :stride=2的$2\times2$卷积
1 2 3 4 5 6 7 8 9 10 11 12 13#https://github.com/facebookresearch/ConvNeXt/blob/e4e7eb2fbd22d58feae617a8c989408824aa9eda/models/convnext.py#L72 self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers stem = nn.Sequential( nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4), LayerNorm(dims[0], eps=1e-6, data_format="channels_first") ) self.downsample_layers.append(stem) for i in range(3): downsample_layer = nn.Sequential( LayerNorm(dims[i], eps=1e-6, data_format="channels_first"), nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2), ) self.downsample_layers.append(downsample_layer)
Empirical Evaluations on ImageNet
ConvNeXt 变体配置
ConvNeXt 系列 C_channels B_stage_blocks IN-1K top-1 acc_input_224 ConvNeXt-T (96,192,384,768) (3,3,9,3) 82.1 ConvNeXt-S (96,192,384,768) (3,3,27,3) 83.1 ConvNeXt-B (128,256,512,1024) (3,3,27,3) 83.8 ConvNeXt-L (192,384,768,1536) (3,3,27,3) 84.3 ConvNeXt-XL (256,512,1024,2048) (3,3,27,3) IN-22K pre-trained-87.0
Training Techniques
ImageNet-1K
| (Pre)-training config | ResNet50(standard) | ResNet50(timm) | ResNet50(torchvision) | ConvNeXt-T |
|---|---|---|---|---|
| optimizer | SGD | LAMB | SGD | AdamW |
| base learning rate | 0.1 | 5e-3 | 0.5 | 4e-3 |
| weight decay | 1e-4 | 0.01 | 2e-5 | 0.05 |
| optimizer momentum | 0.9 | - | 0.9 | $\beta_1,\beta_2=0.9,0.999$ |
| batch size | $8\times32=256$ | $4\times512=2048$ | $8\times128=1024$ | $4\times8\times128=4096$ |
| training epochs | 90 | 600 | 600 | 300 |
| learning rate schedule | StepLR (step=30,gamma=0.1) | cosine decay | cosine decay | cosine decay |
| warmup epochs | - | 5 | 5 | 20 |
| warmup schedule | - | linear | linear | linear |
The effective batch size =
--nodes*--ngpus*--batch_size*--update_freq. In the example above, the effective batch size is4*8*128*1 = 4096
数据增强
| (Pre)-training config | ResNet50(standard) | ResNet50(timm) | ResNet50(torchvision) | ConvNeXt-T |
|---|---|---|---|---|
| Mixup | - | 0.2 | 0.2 | 0.8 |
| Cutmix | - | 1.0 | 1.0 | 1.0 |
| RandAugment | - | (7,0.5) | auto_augment=‘ta_wide’ | (9,0.5) |
正则化
| (Pre)-training config | ResNet50(standard) | ResNet50(timm) | ResNet50(torchvision) | ConvNeXt-T |
|---|---|---|---|---|
| Stochastic Depth | - | 0.05 | - | 0.1 |
| Label Smoothing | - | 0.1 | 0.1 | 0.1 |
| Layer Scale | - | - | - | 1e-6 |
| EMA | - | - | 0.99998 | 0.9999 |
Top-1 acc
| (Pre)-training config | ResNet50(standard) | ResNet50(timm) | ResNet50(torchvision) | ConvNeXt-T |
|---|---|---|---|---|
| Top-1 acc | 75.3 | 80.4 | 80.674 | 82.1 |
拓展阅读
ResNet strikes back: An improved training procedure in timm
How to Train State-Of-The-Art Models Using TorchVision’s Latest Primitives