EfficientNet
EfficientNet
文章标题:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 作者:Mingxing Tan, Quoc V. Le 发表时间:(ICML 2019)
EfficientNet 是一组针对FLOPs和参数效率进行优化的模型。它利用NAS搜索基线EfficientNet-B0,它在准确性和FLOPs方面有更好的权衡。然后使用复合缩放策略对基线模型进行缩放,以获得一系列模型B1-B7。
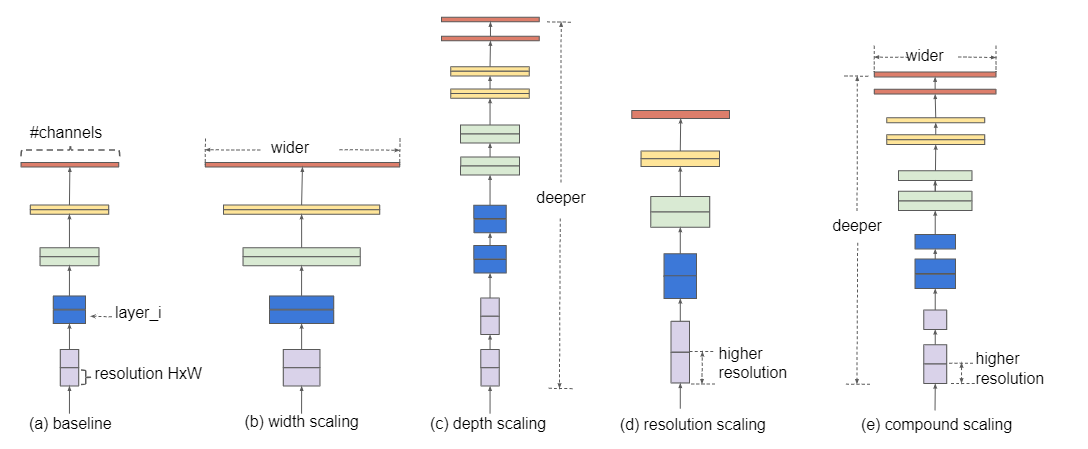
增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。(ResNet)
增加网络的width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。(Inception)
增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小,并且大分辨率图像会增加计算量。
Scaling Dimensions

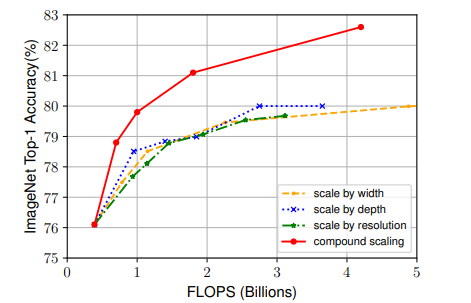
扩大网络中深度、宽度或者分辨率的任一维度能提高模型的准确率,但随着模型的扩大,这种准确率的增益效果会逐步消失;
Scaling up any dimension of network width, depth, or resolution improves accuracy, but the accuracy gain diminishes for bigger models.
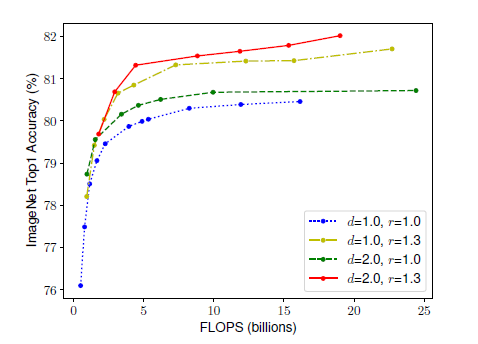
$(d=1.0,r=1.0)$:18个卷积层,分辨率为$224\times224$
$(d=2.0,r=1.3)$:36个卷积层,分辨率为$299\times299$
为了更好的准确率和效率,很有必要去平衡提升网络中深度、宽度和分辨率的所有维度。
In order to pursue better accuracy and efficiency, it is critical to balance all dimensions of network width, depth, and resolution during ConvNet scaling.
Problem Formulation
$N = \bigodot_{i=1…s} F_i^{L_i}(X_{<H_i,W_i,C_i>})$
$ \bigodot_{i=1…s}$:连乘运算
$F_i$表示一个运算操作;$F_i^{L_i}$表示在第i个stage中$F_i$运算被重复执行了$L_i$次
$X$表示第i个stage的特征矩阵(输入张量)
$<H_i,W_i,C_i>$表示$X$的高宽和通道数
$max_{d,w,r} \ \ Accuracy(N(d,w,r))$ 其中
$$ depth:d=\alpha^\phi\\ width:w=\beta^\phi\\ resolution:r=\gamma^\phi\\ s.t. \ \alpha \cdot \beta^2\cdot\gamma^2 \approx2\\ \alpha\geq1,\beta\geq1,\gamma\geq1 $$$N(d,w,r)=\bigodot_{i=1…s} \hat F_i^{\hat L_i}(X_{<r\dot {\hat H_i},r\dot {\hat W_i},w\dot {\hat C_i}>})$
$Memory(N)\leq target_memory$
$ FLOPS(N)\leq target_flops$
$d$用来缩放深度$\hat {L_i}$
$r$用来缩放分辨率即影响$\hat{H_i},\hat{W_i}$
$w$用来缩放特征矩阵的通道数$\hat{C_i}$
FLOPs(理论计算量)与depth的关系:当depth翻倍,FLOPs也翻倍。
FLOPs与width的关系:当width翻倍(即channal翻倍),FLOPs会翻4倍
当width翻倍,输入特征矩阵的channels和输出特征矩阵的channels或卷积核的个数都会翻倍,所以FLOPs会翻4倍
FLOPs与resolution的关系:当resolution翻倍,FLOPs会翻4倍
总的FLOPs倍率可以用近似用$(\alpha \cdot \beta^{2} \cdot \gamma^{2})^{\phi}$表示 :$\beta^2:c_i,c_o;\gamma^2:h,w$
- 固定$\phi=1$,基于上述约束条件进行搜索,EfficientNet_B0的最佳参数为$\alpha=1.2,\beta=1.1.\gamma=1.15$。
- 固定$\alpha=1.2,\beta=1.1.\gamma=1.15$,在EfficientNetB-0的基础上使用不同的$ \phi$分别得到EfficientNetB1-B7。
EfficientNet Architecture
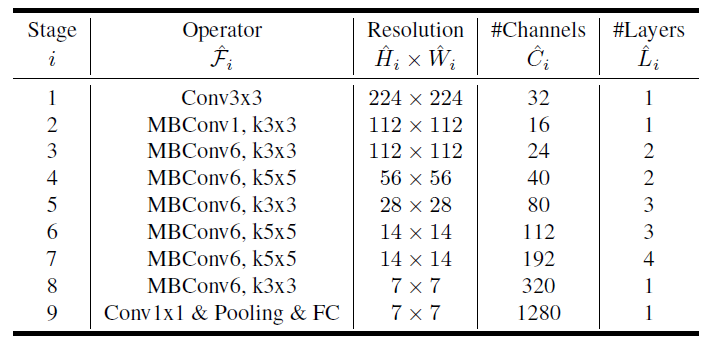
其中卷积层后默认都有BN以及Swish激活函数
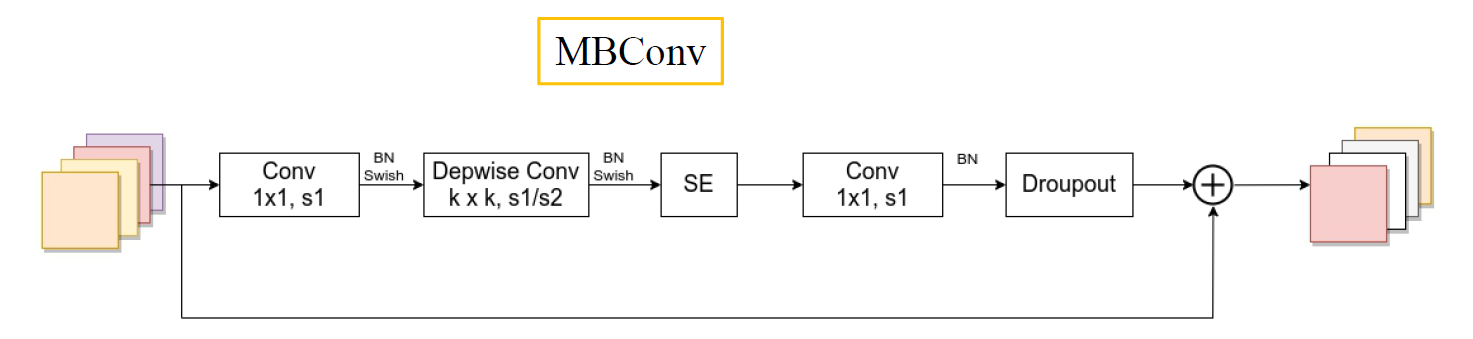
- 第一个升维的$1\times1$卷积层,它的卷积核个数是输入特征矩阵channel的n倍(这里的n对应Operator里的MBConvn)
- 当n=1时,不要第一个升维的$1\times1$卷积层,即Stage2中的MBConv结构都没有第一个升维的1x1卷积层(这和MobileNetV3网络类似)
- 关于shortcut连接,仅当输入MBConv结构的特征矩阵与输出的特征矩阵shape相同时才存在
注意:在源码中只有使用到shortcut的MBConv模块才有Dropout层;Dropout层的
drop_rate是从0递增到0.2的,是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。
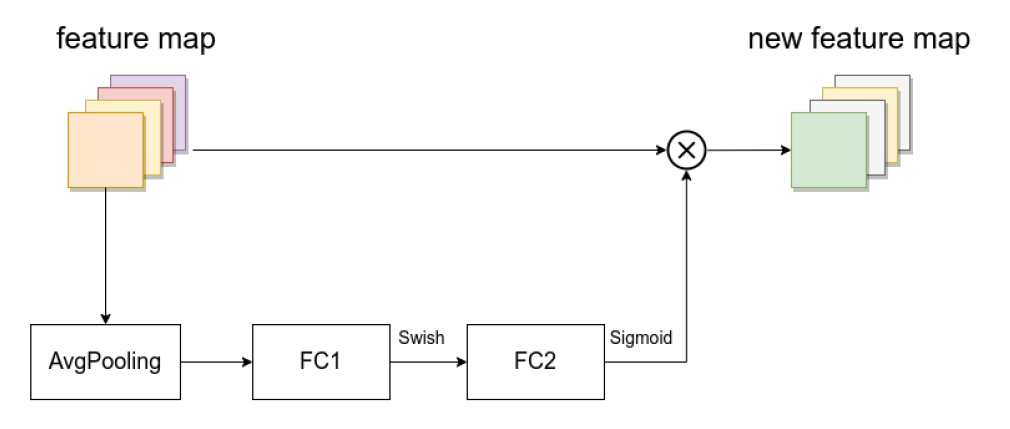
由一个全局平均池化,两个全连接层组成。
第一个全连接层的节点个数是输入该MBConv模块的特征矩阵channels的1/4(MobileNetV3是feature map的channels的1/4),且使用Swish激活函数。
第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数。
| model | width_coefficient | depth_coefficient | resolution | dropout_rate |
|---|---|---|---|---|
| efficientnet-b0 | 1.0 | 1.0 | 224 | 0.2 |
| efficientnet-b1 | 1.0 | 1.1 | 240 | 0.2 |
| efficientnet-b2 | 1.1 | 1.2 | 260 | 0.3 |
| efficientnet-b3 | 1.2 | 1.4 | 300 | 0.3 |
| efficientnet-b4 | 1.4 | 1.8 | 380 | 0.4 |
| efficientnet-b5 | 1.6 | 2.2 | 456 | 0.4 |
| efficientnet-b6 | 1.8 | 2.6 | 528 | 0.5 |
| efficientnet-b7 | 2.0 | 3.1 | 600 | 0.5 |
| efficientnet-b8 | 2.2 | 3.6 | 672 | 0.5 |
| efficientnet-12 | 4.3 | 5.3 | 800 | 0.5 |
width_coefficient代表channel维度上的倍率因子
比如在 EfficientNetB0中Stage1的$3\times3$卷积层所使用的卷积核个数是32,那么在B6中就是$32 \times 1.8=57.6$,接着取整到离它最近的8的整数倍即56,其它Stage同理。
depth_coefficient代表depth维度上的倍率因子(仅针对
Stage2到Stage8)比如在EfficientNetB0中Stage7的$ {\widehat L}_i=4 $那么在B6中就是$4 \times 2.6=10.4$,接着向上取整即11。
- dropout_rate是最后一个全连接层前的
dropout层(在stage9的Pooling与FC之间)的dropout_rate。
拓展阅读
EfficientNetV2
文章标题:EfficientNetV2: Smaller Models and Faster Training 作者:Mingxing Tan, Quoc V. Le 发表时间:(ICML 2021)
EfficientNetV1的训练瓶颈
大图像尺寸导致了大量的内存使用,训练速度非常慢。
解决方法:降低训练图像的尺寸
深度卷积在网络浅层(前期)中速度缓慢,但在后期阶段有效。(无法充分利用现有的一些加速器)
解决方法:引入Fused-MBConv结构
同等的扩大每个stage是次优的。在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同
解决方法:非均匀的缩放策略来缩放模型
Fused-MBConv
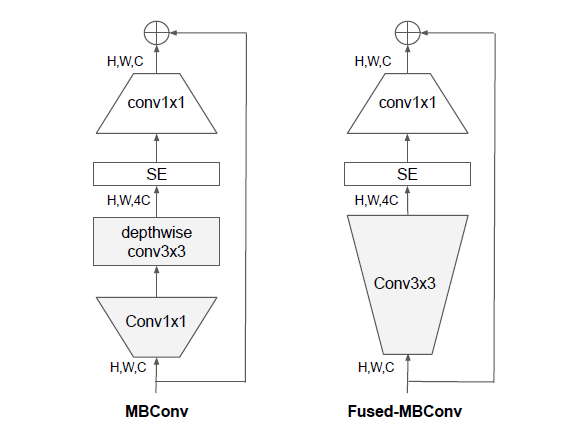
源码没有使用SE模块
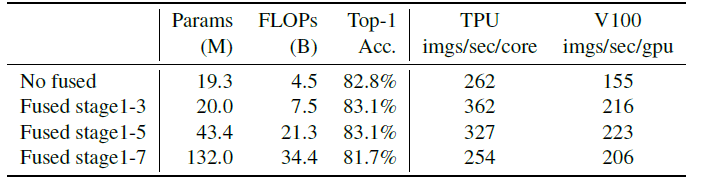
只替换stage1-3,用NAS搜索出来的结果
EfficientNetV2 Architecture
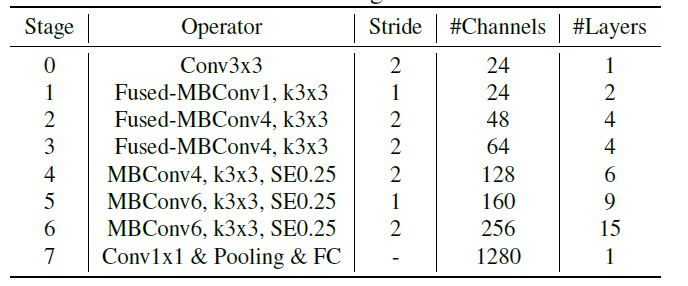
与EfficientNetV1的不同点
- 除了使用MBConv模块,还使用Fused-MBConv模块
- 会使用较小的expansion ratio
- 偏向使用更小的kernel_size($3\times3$)
- 移除了EfficientNetV1中最后一个步距为1的stage(V1中的stage8)
| |
progressive learning渐进式学习
在训练早期,先对图像尺寸小且正则化程度较弱的网络进行训练(如dropout、data augmentation),然后逐渐增大图像尺寸并加入更强的正则化。
建立在渐进调整大小的基础上,但通过动态(自适应)调整正则化(Dropout, Rand Augment, Mixup)
