Inception
策略:split-transform-merge
InceptionV1(GoogLeNet)
文章标题:Going Deeper with Convolutions
作者:Christian Szegedy,Wei Liu,Yangqing Jia,Pierre Sermanet,Scott Reed,Dragomir Anguelov,Dumitru Erhan,Vincent Vanhoucke,Andrew Rabinovich
发表时间:(CVPR 2015)
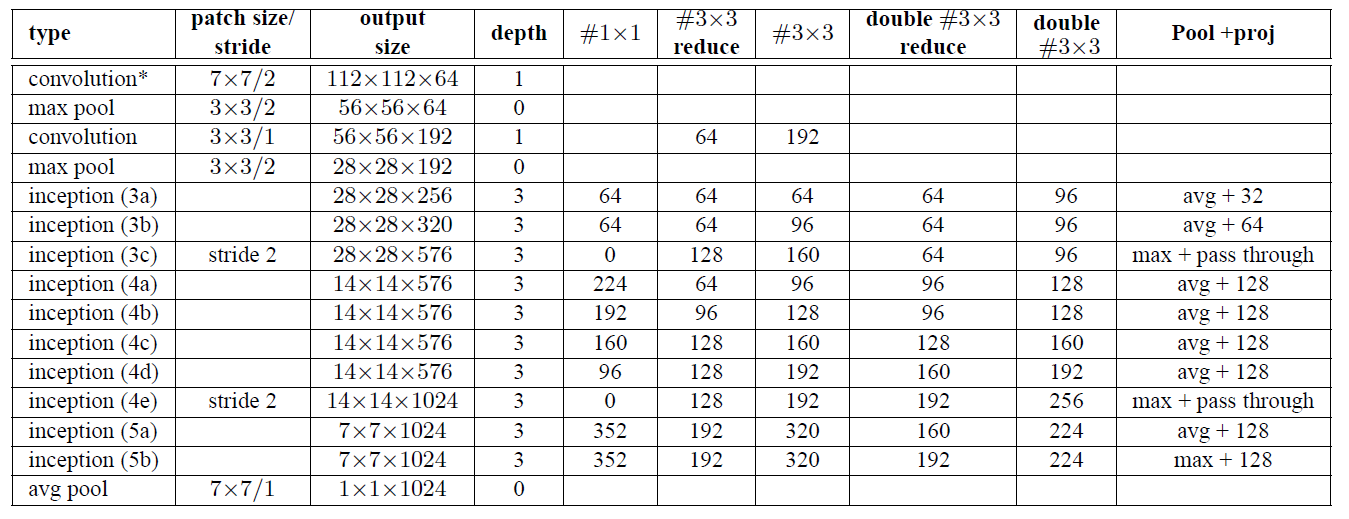
GoogLeNet深度卷积神经网络结构,及其后续变种Inception-V1、Inception-V2-Inception-V3、Inception-V4。
使用Inception模块,引入并行结构和不同尺寸的卷积核,提取不同尺度的特征,将稀疏矩阵聚合为较为密集的子矩阵,大大提高计算效率,降低参数数量。加入辅助分类器,实现了模型整合、反向传播信号放大。
GoogLeNet在ILSVRC-2014图像分类竞赛中获得了top-5误差6.7%的冠军成绩。
Introduction
启发文献
$1\times1$卷积降维-升维
Global Average pooling层取代全连接层
Provable Bounds for Learning Some Deep Representations
用稀疏、分散的网络取代以前庞大密集臃肿的网络
Related work
LeNet,AlexNet,ZFNet,NiN,overfeat
Motivation and High Level Considerations
提高模型性能的传统方法:
- 增加深度(层数)
- 增加宽度(卷积核个数)适用于大规模标注好的数据集
产生的问题:
标注成本高
计算效率问题
两个相连卷积层,两层同步增加卷积核个数,计算量将平方增加 如果很多权重训练后接近0,这部分计算就被浪费掉了
GoogLeNet
原始Inception模块通道数越来越多,计算量爆炸。
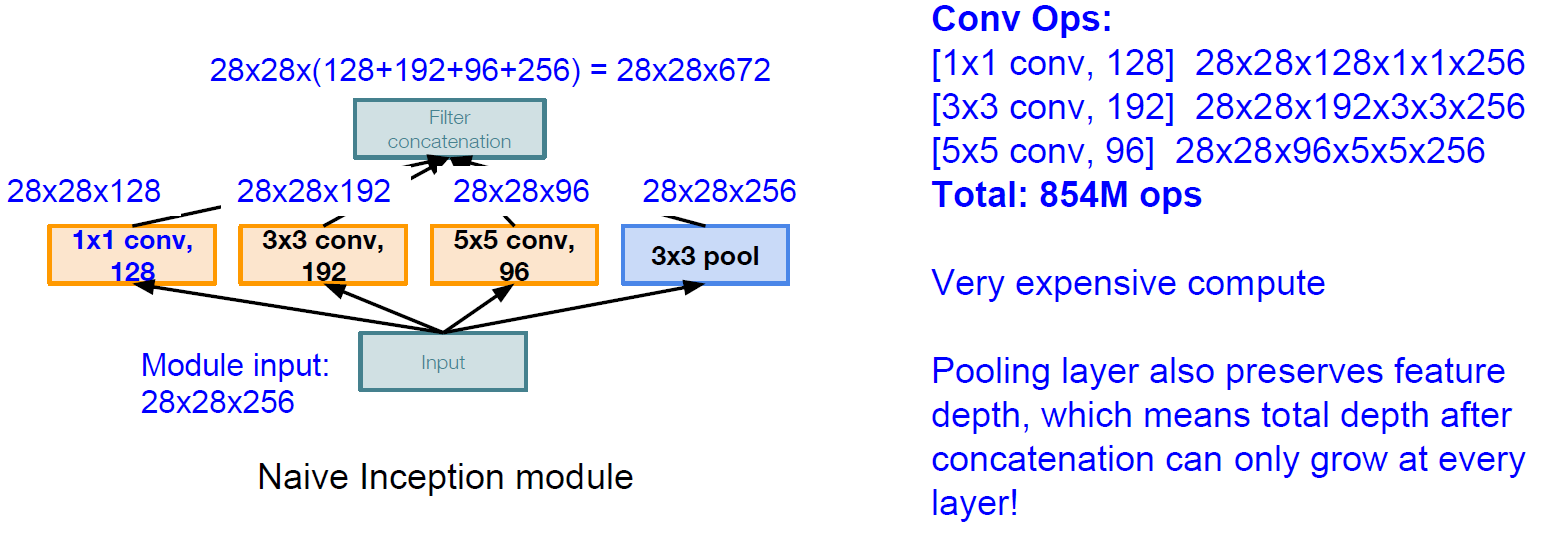
每个 Inception 结构有 4 个分支,主要包含 1x1, 3x3, 5x5 卷积核和 max pooling 操作的步长为1,以保持输出特征层的尺寸与卷积核输出尺寸一致。1x1 卷积核的作用是降维,以避免 cancatenation 操作导致特征层过深,并减少网络参数.

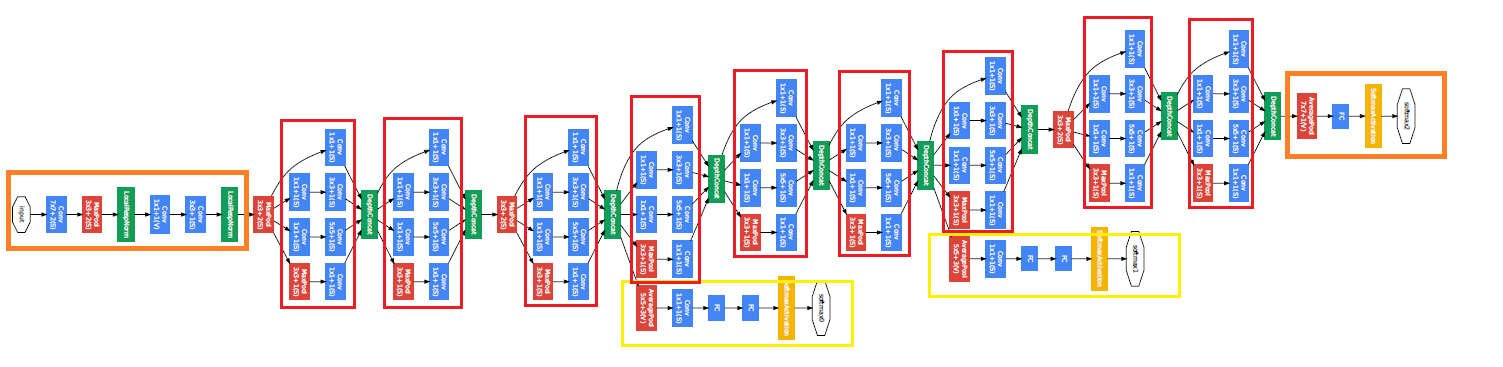
#$3\times3$reduce:$3\times3$卷积之前的$1\times1$卷积,其他reduce同理
pool proj:池化后的$1\times1$卷积
所有卷积使用relu激活函数
GAP:全局平均池化 一个channel用一个平均值代表取代全连接层,减少参数量。
便于fine-tune迁移学习
提升了0.6%的TOP1准确率
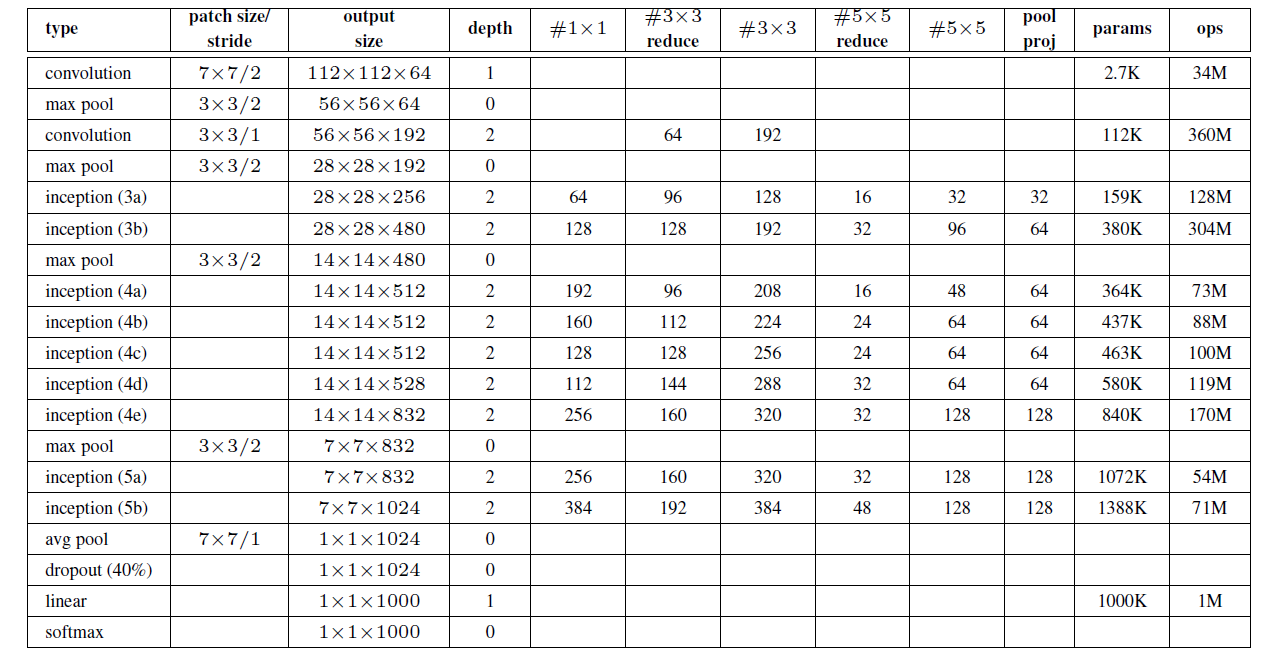
原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
Stem Network:Conv-Pool-2x Conv-Pool(底层先用普通卷积层,后面用9个Inception模块叠加)
Classifier output(removed expensive FC layers!)
Auxiliary classification outputs to inject additional gradient at lower layers
(AvgPool-1x1Conv-FC-FC-Softmax)
在4a和4d后面加辅助分类层
改善梯度消失
正则化
让浅层也能学习到区分特征
其实没太大用处,在v2/v3版本去掉
训练时损失函数:$L=L_{最后}+0.3\times L_{辅1}+0.3\times L_{辅2}$
测试阶段:去掉辅助分类器
Training Methodlogy
数据并行:一个batch均分k份,让不同节点前向和反向传播,再由中央param sever优化更新权重
asynchronous stochastic gradient descent:异步随机梯度下降
图像增强
裁剪为原图8%-100%之间,宽高比3/4和4/3之间;
等概率使用不同插值方法(双线性,区域,最近邻,三次函数)
裁剪:
将原图缩放为短边长度256,288,320,352的四个尺度
每个尺度裁剪出左中右(或上中下)三张小图
每张小图取四个角和中央的五张$224\times224$的patch以及每张小图缩放为$224\times224$,共6个patch同时取镜像
$4\times3\times6\times2=144$个patch
拓展阅读
Hebbian原则理解
1、网络更容易过拟合,当数据集不全的时候,过拟合更容易发生,于是我们需要为网络feed大量的数据,但是制作样本集本身就是一件复杂的事情。 2、大量需要更新的参数就会导致需要大量的计算资源,而当下即使硬件快速发展,这样庞大的计算也是很昂贵的
解决以上问题的根本方法就是把全连接的网络变为稀疏连接(卷积层其实就是一个稀疏连接),当某个数据集的分布可以用一个稀疏网络表达的时候就可以通过分析某些激活值的相关性,将相关度高的神经元聚合,来获得一个稀疏的表示。 这种方法也呼应了Hebbian principle,一个很通俗的现象,先摇铃铛,之后给一只狗喂食,久而久之,狗听到铃铛就会口水连连。这也就是狗的“听到”铃铛的神经元与“控制”流口水的神经元之间的链接被加强了,而Hebbian principle的精确表达就是如果两个神经元常常同时产生动作电位,或者说同时激动(fire),这两个神经元之间的连接就会变强,反之则变弱(neurons that fire together, wire together)
InceptionV2(BN-Inception)
文章标题:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
作者:Sergey Ioffe, Christian Szegedy
发表时间:(ICML 2015)
Abstract
训练慢和困难:internal covariate shift (ICS)
低学习率;参数初始化
Batch Normalization
加快模型训练速度;加速收敛
可以使用更高的学习率;参数初始化
和当前最好的分类网络相比训练步骤降低14倍
具有一定正则化作用
在某些情况,减少Dropout的使用
使模型效果更好(并不是所有模型用了BN 就会更好)
top-5:4.9%;
test error:4.8%
超过了人工评分的准确性。
Introduction
使用mini-batch
小批量的损失梯度是对训练集上梯度的估计,其质量随着批量大小的增加而提高。
现代计算平台提供的并行性,批处理的计算比单个示例的m次计算效率要高得多。
internal covariate shift:在深度学习网络的训练过程中网络内部结点的分布变化称为内部协变量偏移
每一层数据的微小变化都会随着网络一层一层的传递而被逐渐放大。
Normalization via Mini-Batch Statistics
白化(Whitening):对输入数据分布进行变换
- 使得输入特征分布具有相同的均值与方差。其中PCA白化保证了所有特征分布均值为0,方差为1;而ZCA白化则保证了所有特征分布均值为0,方差相同;
- 去除特征之间的相关性。
白化过程计算成本太高
白化过程由于改变了网络每一层的分布,因而改变了网络层中本身数据的表达能力
Batch Normalization:简化白化
单独对每个特征标准化参数,使其具有零均值和单位方差。
引入了两个可学习的参数$\gamma$与$\beta$,这两个参数的引入是为了恢复数据本身的表达能力,对规范化后的数据进行线性变换。
对全连接层,作用在特征维
对卷积层,作用在通道维
如果batch size为$m$,则在前向传播过程中,网络中每个节点都有$m$个输出,Batch Normalization就是对该层每个节点的这$m$个输出进行归一化再输出,具体计算方式如下:

$$ y_i^{(b)}=BN_{(x_i)^{(b)}}=\gamma \cdot (\frac{x_i^{(b)}-\mu(x_i)}{\sqrt {\sigma(x_i)^2+\epsilon}})+\beta $$
- Standardization:首先对$m$个$x$进行 Standardization,得到 zero mean unit variance的分布$\hat x$。
- scale and shift:然后再$ \hat x$对进行scale and shift,缩放并平移到新的分布$y$,具有新的均值$\beta$方差$\gamma$。
$\mu$和$\sigma$为该行的均值和标准差,$\epsilon$为防止除零引入的极小量(可忽略)
$\gamma$和$\beta$为scale和shift参数,以提高表现力
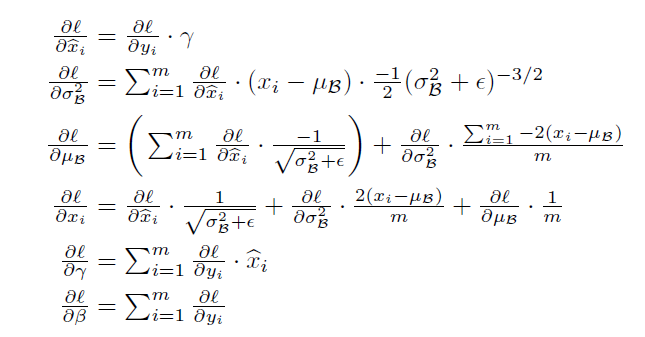
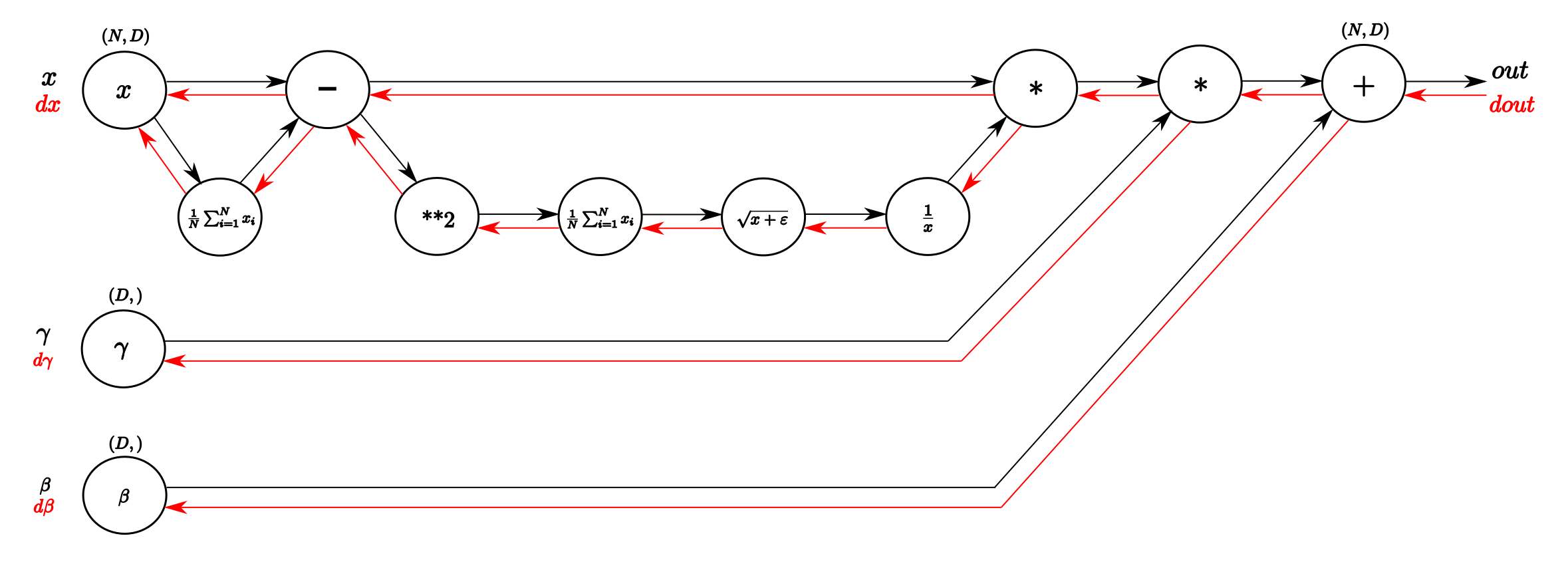
Understanding the backward pass through Batch Normalization Layer
训练阶段计算的是每一个batch的均值和方差,但是测试时用的是训练后的(指数加权平均)的均值和方差(吴恩达)
Inception V2 Architecture
与Inception V1对比
Inception V1的$5\times 5$卷积被替换成两个$3\times 3$
使网络的最大深度增加9层。增加了25%的参数,计算成本增加了约30%。
Inception(3X)(特征图为$28\times28$)模块从2个变成3个。(Inception3a,b——>Inception3a,b,c)
模块内部有时使用平均池化,有时使用最大池化
模块3c, 4e的过滤器连接之前使用了stride-2卷积/池化层。
在第一层卷积层上采用深度乘子8的可分离卷积。
减少了计算成本,同时增加了训练时的内存消耗。
拓展阅读
Batch Normalization详解以及pytorch实验
Understanding the backward pass through Batch Normalization Layer
深入解读Inception V2之Batch Normalization(附源码)
理解Batch Normalization系列3——为什么有效及11个问题
Batch-normalized 应该放在非线性激活层的前面还是后面?
How Does Batch Normalization Help Optimization?
BN层让损失函数更平滑。通过分析训练过程中每步梯度方向上步长变化引起的损失变化范围、梯度幅值的变化范围、光滑度的变化,认为添加BN层后,损失函数的landscape(loss surface)变得更平滑,相比高低不平上下起伏的loss surface,平滑loss surface的梯度预测性更好,可以选取较大的步长。
对比了标准VGG以及加了BN层的VGG每层分布随训练过程的变化,发现两者并无明显差异,认为BatchNorm并没有改善 Internal Covariate Shift。
How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)
An empirical analysis of the optimization of deep network loss surfaces
BN更有利于梯度下降。绘制了VGG和NIN网络在有无BN层的情况下,loss surface的差异,包含初始点位置以及不同优化算法最终收敛到的local minima位置。没有BN层的,其loss surface存在较大的高原,有BN层的则没有高原,而是山峰,因此更容易下降。
InceptionV3
文章标题:Rethinking the Inception Architecture for Computer Vision
作者:Szegedy, Christian, et al
发表时间:(CVPR 2016)
本论文在GoogLeNet和BN-Inception的基础上,对Inception模块的结构、性能、参数量和计算效率进行了重新思考和重新设计。提出了Inception V2和Inception V3模型,取得了3.5%左右的Top-5错误率。
Inception V3具有强大的图像特征抽取和分类性能,是常用的迁移学习主干网络基模型。
General Design Principles通用设计原则(建议)
避免过度降维或收缩特征Bottleneck(避免过度的1 x 1卷积,特别是在网络浅层)
feature map的长宽大小应该随网络加深缓慢减小
降维会造成各通道间的相关性信息丢失,仅反应了致密的嵌入信息
独立的特征越多收敛越快(尽可能在分类层之前增加通道数)
相互独立特征越多,输入的信息分解的越彻底
Hebbin原理
大卷积核卷积之前可用1x1卷积降维(3x3或5x5卷积之前可先用1x1卷积降维,可保留相邻单元的强相关性)
大尺度卷积:聚合空间信息大感受野
相邻感受野的卷积结果
邻近单元的强相关性在降维过程中信息损失很少
均衡网络的宽度和深度
两者同时提升,既可以提升性能,也能提升计算效率
Factorizing Convolutions with Large Filter Size卷积分解
$5\times5$卷积分解成2个$3\times3$卷积;减少参数数量
分解卷积是否会影响模型表达能力?
是否需保留第一层的非线性激活函数?
增加非线性可学习空间增强了
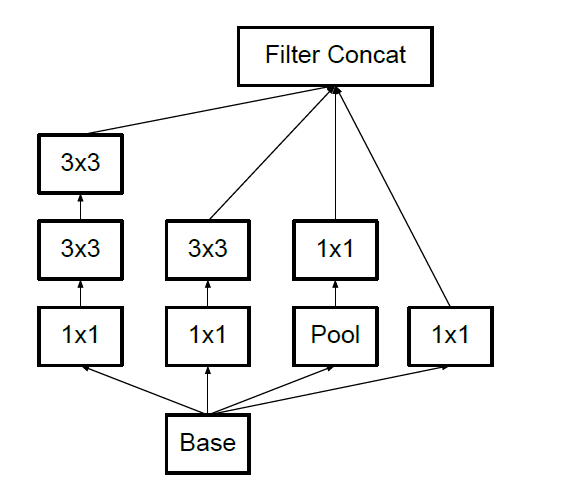
$3\times3$卷积分解成$3\times1$卷积和$1\times3$卷积非对称(空间可分离卷积)
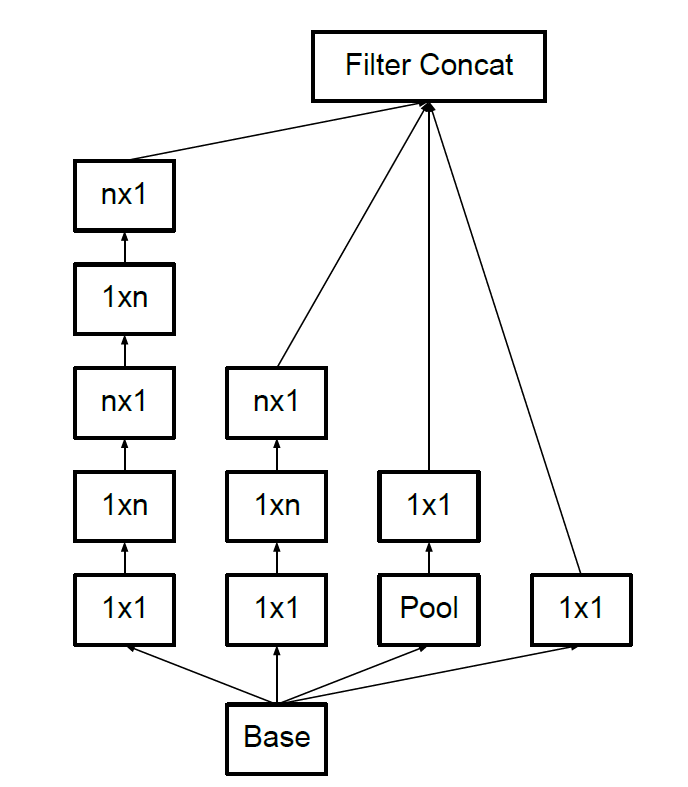
$n\times n$卷积分解成$n \times1$卷积和$1\times n$卷积
n越大,节省的运算量越大
不对称卷积分解在靠前的层效果不好,适用于feature map尺寸在12-20之间
拓展滤波器组(加宽网络,升维)在最后分类层之前,用该模块拓展特征维度,生成高维稀疏特征。
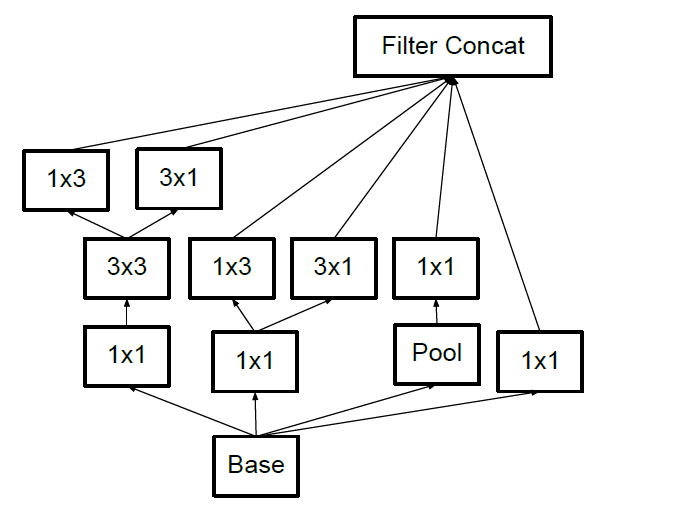
Utility of Auxiliary Classifiers辅助分类器
提出辅助分类器并不能帮助模型更快收敛和更快的特征演化。
增加了BN层和Dropout层的辅助分类器可以起到正则化作用。
Efficient Grid Size Reduction高效下采样技巧
先卷积再池化(计算量大)
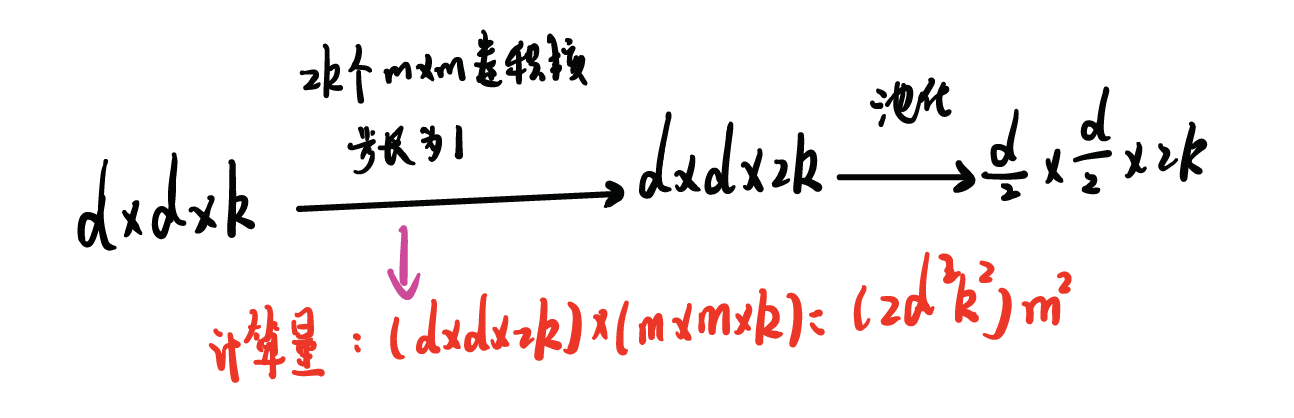 先卷积再池化
先卷积再池化步长为2的卷积(大量信息丢失,违反原则1)
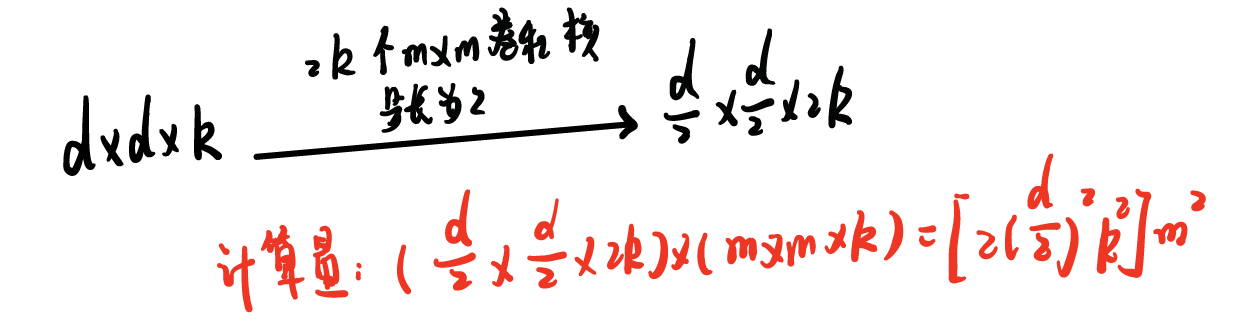 步长为2的卷积化
步长为2的卷积化
Inception V3
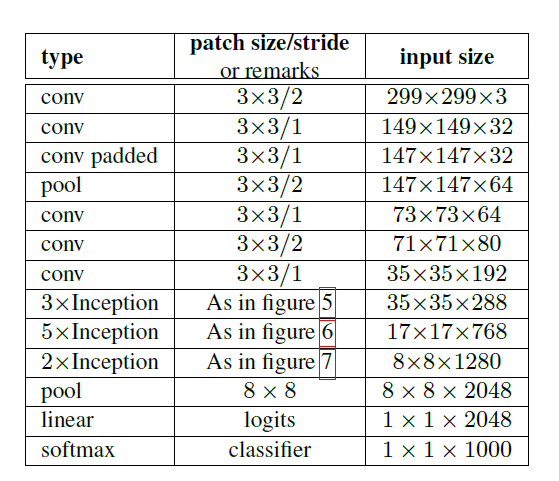
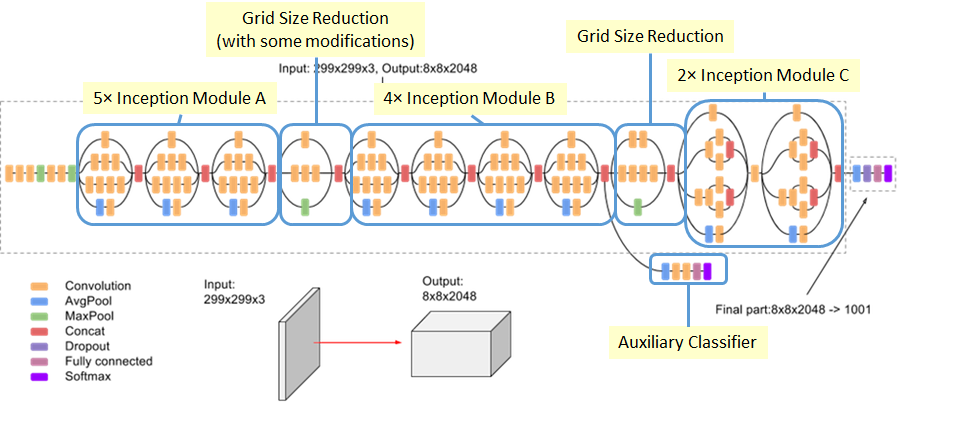
figure5:$5\times5$卷积分解成2个$3\times3$卷积
figure6:空间卷积可分离卷积
figure7:拓展滤波器组
Label Smoothing标签平滑
When Does Label Smoothing Help?
标签平滑的目的是防止最大的 logit 变得比所有其他 logit 大得多
| |
其中 ε 是 0.1,这是一个超参数,K 是 1000,这是类的数量。在分类器层观察到的一种dropout效应。
标签用one-hot独热编码
$$ L=-\sum_{i=1}^{k}q_ilog{p_i}=-log{p_y}=-z_y+log{(\sum_{i=1}^k e^{z_i})} $$可能导致过拟合
它鼓励最大的逻辑单元与所有其它逻辑单元之间的差距变大,与有界限的梯度∂ℓ/∂zk相结合,这会降低模型的适应能力。
$$ z^* = \begin{cases} \log{\frac{(k-1)(1-\varepsilon)}{\varepsilon}} + \alpha & \text{if } i = y \\ \alpha & \text{if } i \neq y \end{cases} $$
拓展阅读
在 Cloud TPU 上运行 Inception v3 的高级指南
InceptionV4
文章标题:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
作者:Szegedy C , Ioffe S , Vanhoucke V , et al.
发表时间:(AAAI 2017)
提出了Inception-V4、Inception-ResNet-V1、Inception-ResNet-V2三个模型。
Inception-V4在Inception-V3的基础上进一步改进了Inception模块,提升了模型性能和计算效率。
Inception-V4没有使用残差模块,
Inception-ResNet将Inception模块和深度残差网络ResNet结合,提出了三种包含残差连接的Inception模块,残差连接显著加快了训练收敛速度。
Inception-ResNet-V2和Inception-V4的早期stem网络结构相同。
Inception-ResNet-V1和Inception-V3准确率相近,Inception-ResNet-V2和Inception-V4准确率相近。
经过模型集成和图像多尺度裁剪处理后,模型Top-5错误率降低至3.1%。
针对卷积核个数大于1000时残差模块早期训练不稳定的问题,提出了对残差分支幅度缩小的解决方案。
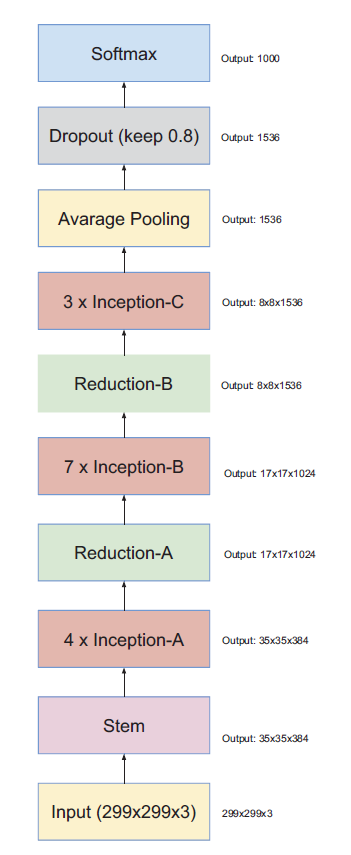
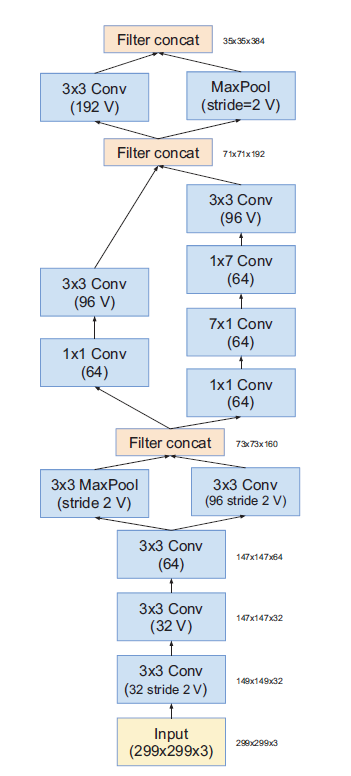
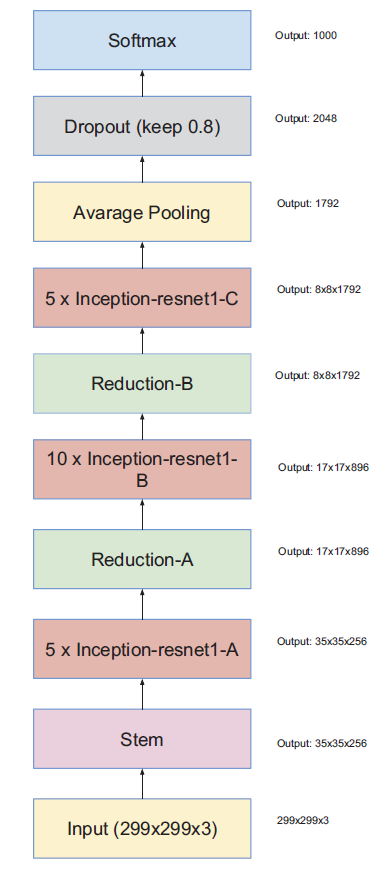
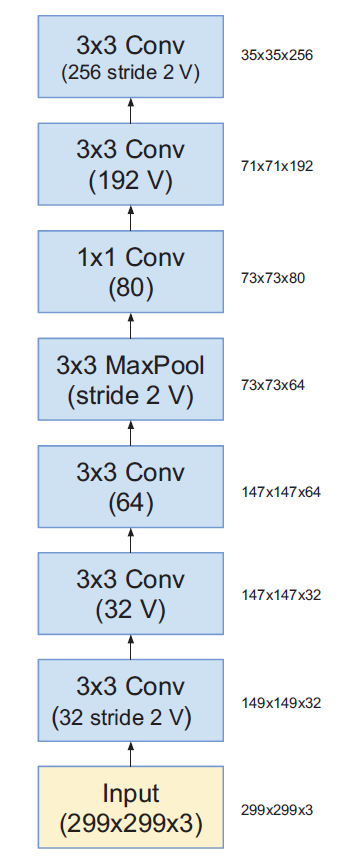
Inception-V4
V:不使用padding
不加V:same padding
如果padding设置为SAME,则说明输入图片大小和输出图片大小是一致的
 |  |
| InceptionV4 | Stem主干网络 |
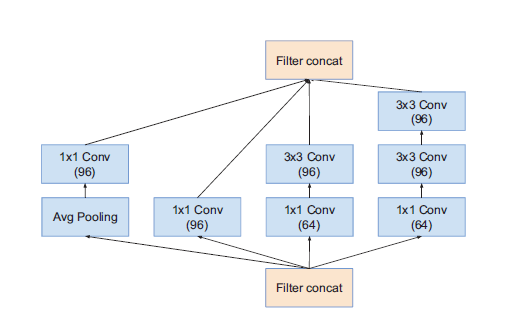 |  |  |
| InceptionV4_Module_A | InceptionV4_Module_B | InceptionV4_Module_C |
模块A输出Grid Size:$35\times35$
模块B输出Grid Size:$17\times17$
模块C输出Grid Size:$8\times8$
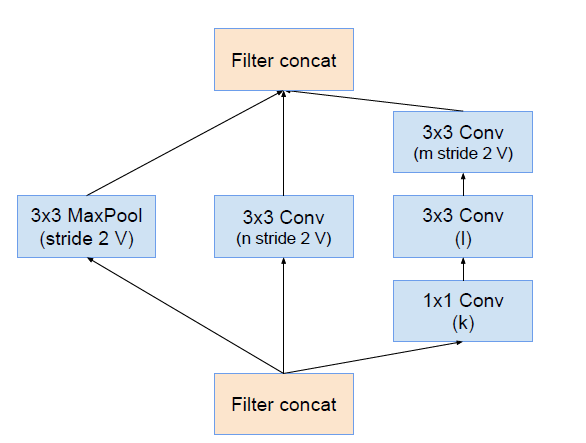 |  |
| ReductionA | ReductionB |
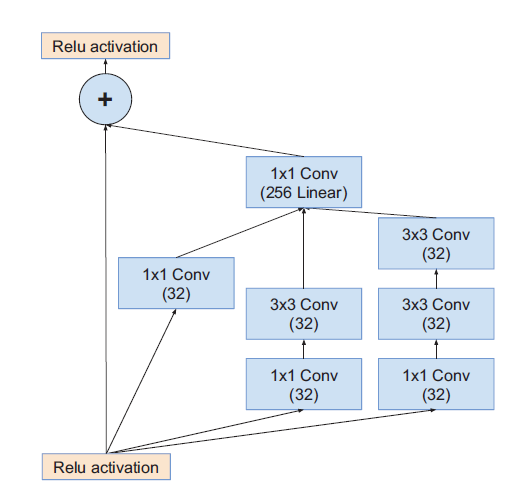
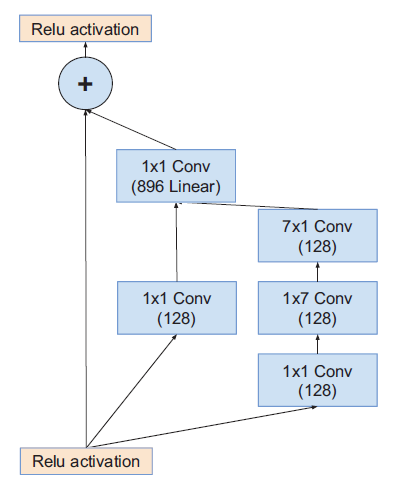
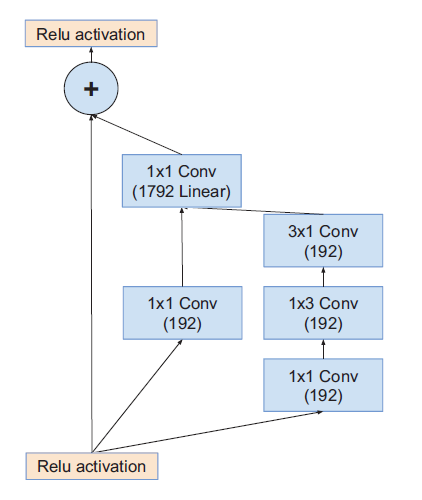
Inception-ResNet-V1
性能和InceptionV3相近
带残差模块的Inception
Inception之后使用不带激活函数的$1\times1$卷积:升维拓展filter bank ,匹配输入维度
在相加层之后不做BN,减少计算量。
 |  |
| Inception-ResNet-v1 | Stem主干网络 |
 |  |  |
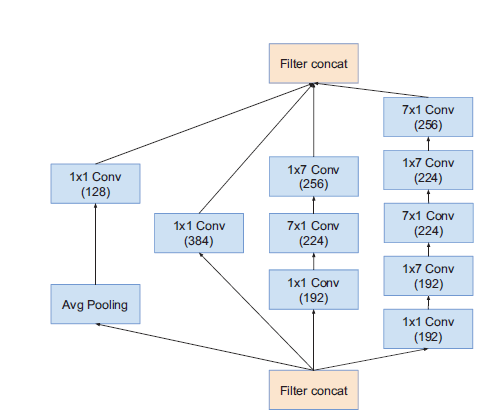
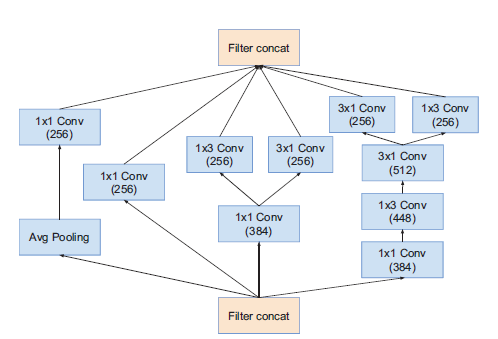
| Inception-ResNet-v1_Module_A | Inception-ResNet-v1_Module_B | Inception-ResNet-v1_Module_C |
模块A输出Grid Size:$35\times35$
模块B输出Grid Size:$17\times17$
模块C输出Grid Size:$8\times8$
Inception-ResNet-V2
Inception-ResNet-V1和Inception-ResNet-V2网络总体结构一样
Inception-ResNet-V2和InceptinV4主干网络一样
性能和InceptionV4相近
| |
| Inception-ResNet-V2 | Stem主干网络 |
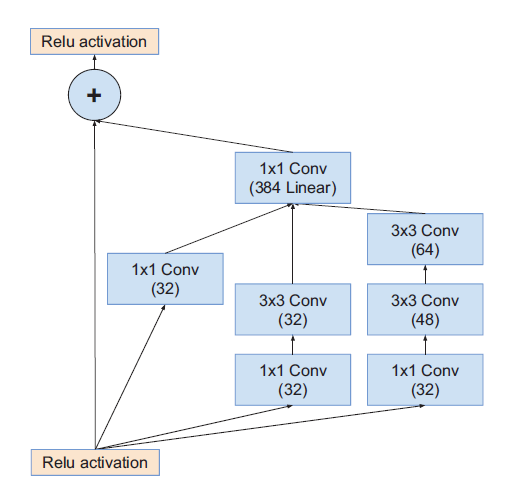 | 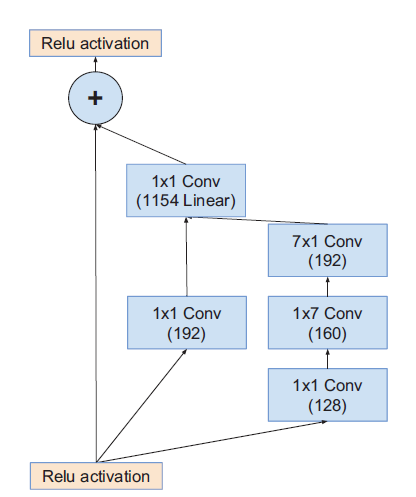 | 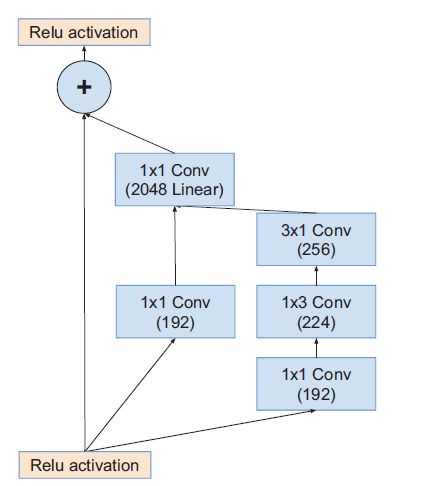 |
| Inception-ResNet-v2_Module_A | Inception-ResNet-v2_Module_B | Inception-ResNet-v2_Module_C |
模块A输出Grid Size:$35\times35$
模块B输出Grid Size:$17\times17$
模块C输出Grid Size:$8\times8$
Scaling of the Residuals
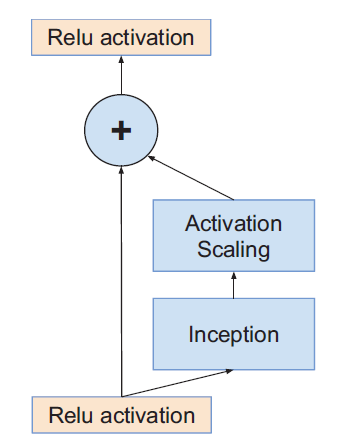
对残差块输出进行幅度减小
在加法融合之前,对残差分支的结果乘以幅度缩小系数
拓展阅读
Inception-V4和Inception-Resnet论文阅读和代码解析
Xception
文章标题:Xception: Deep Learning with Depthwise Separable Convolutions
作者:Francois Chollet
发表时间:(CVPR 2017)
谷歌Xception,将深度可分离卷积引入Inception模块,实现长宽方向的空间信息和跨通道信息的完全解耦。X代表Extreme,极致。
在ImageNet数据集和JFT数据集两个大规模图像分类任务上,收敛速度、最终准确率都超过Inception V3。
Xception作者为深度学习框架Keras作者François Chollet。在Keras中可调用预训练的Xception模型作为迁移学习的骨干网络。
VGG:经典串行堆叠深度
Inception:拓展多分支宽度,分别处理(解耦)再整合汇总
在 DeeplabV3+ 中,作者将 Xception 做了进一步的改进,同时增加了 Xception 的层数,设计出了 Xception65 和 Xception71 的网络。
The Cxeption architecture
假设:跨通道信息和长宽方向的空间信息可完全分离解耦
Xception与标准可分离卷积的区别
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (2017)
顺序不同
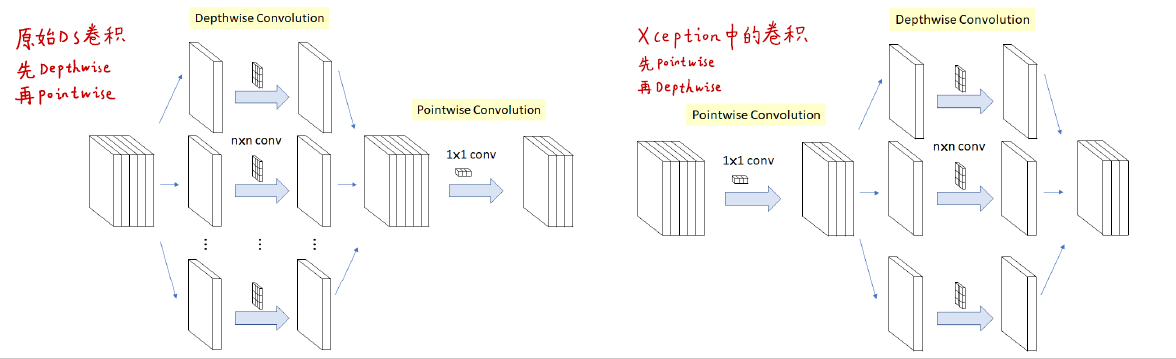 Xception与深度可分离卷积的区别
Xception与深度可分离卷积的区别Xception中使用非线性激活函数ReLu
常规卷积:一个卷积核处理所有通道
深度可分离卷积:一个卷积核处理一个通道
SeperableConv包含$1\times1$卷积+深度可分离卷积+合并
极限版本:每个$3\times3$卷积单独处理一个通道
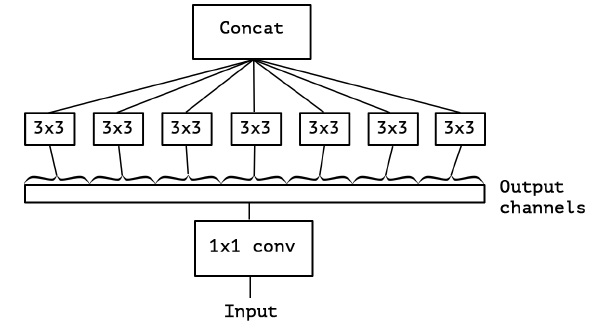
Effect of an intermediate activation after pointwise convolutions
非线性激活对空间-通道未解耦时有用
对$1\times1$卷积后的特征图,非线性激活会导致信息丢失,不利于后续的深度可分离卷积。