ResNet
ResNet
文章标题:Deep Residual Learning for Image Recognition
作者:Kaiming He ,Xiangyu Zhang ,Shaoqing Ren ,Jian Sun,Microsoft Research
发表时间:(CVPR 2016)
微软亚洲研究院提出的深度残差网络ResNet,获得2015年ImageNet图像分类、定位、检测,MS COCO竞赛检测、分割五条赛道的冠军,通过引入残差连接,有效解决深层网络训练时的退化问题,可以通过加深网络大大提升性能。
ResNet在ILSVRC-2015图像分类竞赛中获得了top-5误差3.57%的冠军成绩,在图像分类任务上首次超过人类能力。ResNet常用于迁移学习和fine-tuning微调的特征提取的基模型。
提出残差学习结构解决深网络的退化问题和训练问题。
Introduction
Question: 简单叠加神经网络层可以吗?
Phenomenon:
明显的梯度消失/爆炸问题,难以收敛——正则化,适当的权重初始化+Batch Normalization可以加快网络收敛
模型退化问题凸显,准确率饱和
- 网络退化:深层网络在训练集和测试集上的表现都不如浅层网络
- 模型退化问题并非过拟合导致,增加深度导致训练集错误率提升
- 深层网络不能比浅层网络错误率更高——identity mapping恒等映射
Residual block
- 残差路径如何设计?
- shortcut路径如何设计?
- Residual Block之间怎么连接?
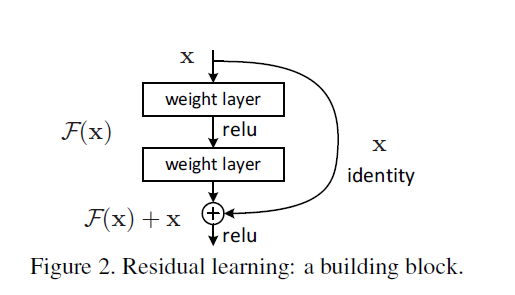
残差模块
过去:
- 直接拟合$H(x)$
现在:
- 拟合残差$F(x)=H(x)-x$
shortcut connection:短路连接/捷径连接
- 既没有引入额外参数,也没有增加计算复杂度
- 打破了网络对称性,提升网络表征能力
identity mapping:恒等映射
$\bigoplus$为element-wise addition,要求参与运算的$F(x)$和$x$的尺寸要相同
残差网络
- 易于优化收敛
- 解决退化问题
- 可以很深
Related Work
残差表示( Residual Representations):
有效的浅层表示方法:
VLAD( vector of locally aggregated descriptors)
Fisher Vector: Probabilistic version of VLAD
编码残差向量比编码原始向量表现更好
捷径连接( shortcut Connections):
- MLP——通过线性层将输入连接到输出
- 从中间层直接连接到辅助分类器
- GoogLeNet——Inception Layer
- Highway Networks——门控函数扮演残差角色,门控参数由学习得到
- Residual Learning——提高信息流效率
Deep Residual Learning
传统多层网络难以拟合恒等映射
如果恒等映射已经最优,残差模块只需要拟合零映射
后面的网络只拟合前面网络的输出与期望函数的残差。
[残差块](###Residual block):$y=F(x,{W_i})+x$
- $F(x,{W_i})$:需要学习的残差映射,维度与$x$一致
- $x$:自身输入
- $F+x$:跳跃连接,逐一加和,最后输岀经过激活函数ReLU
- 没有额外参数,不增加复杂度
- $F$包含两个或两个以上网络层,否则表现为线性层$y=W_1x+x$
- 如果卷积层后加BN层,则不需要偏置项(期望为0)
残差分支出现下采样(虚线表示)
shortcut分支第一个卷积层步长都为2
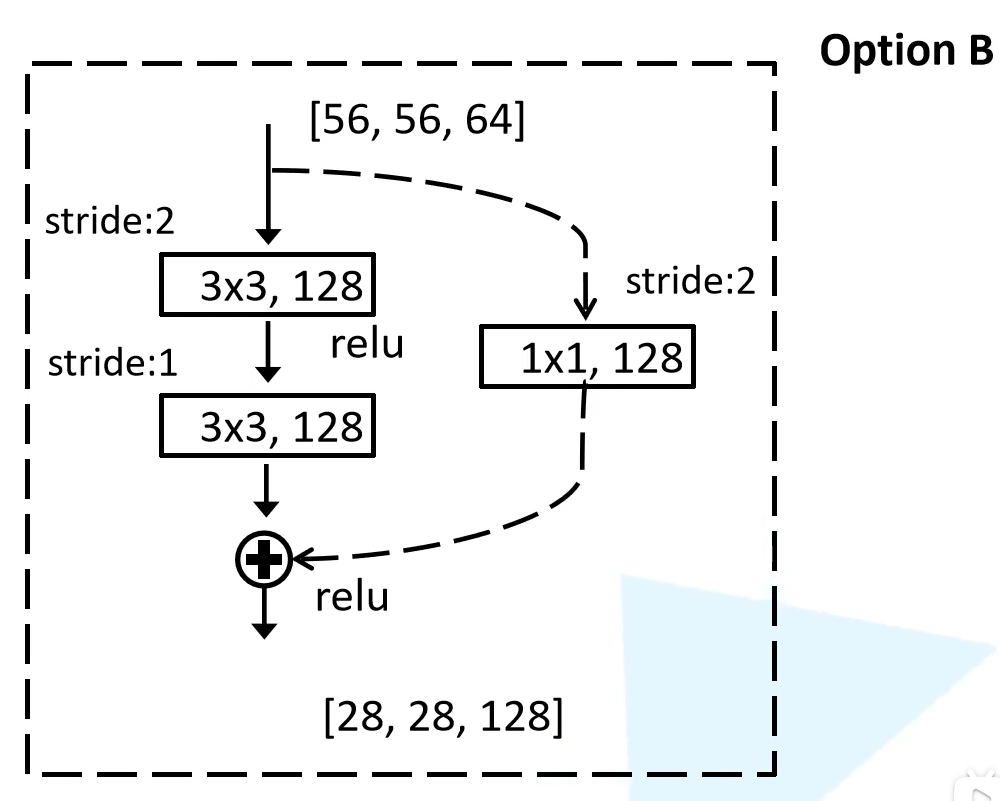
- 对多出来的通道padding补零填充
- 用$1\times1$卷积升维
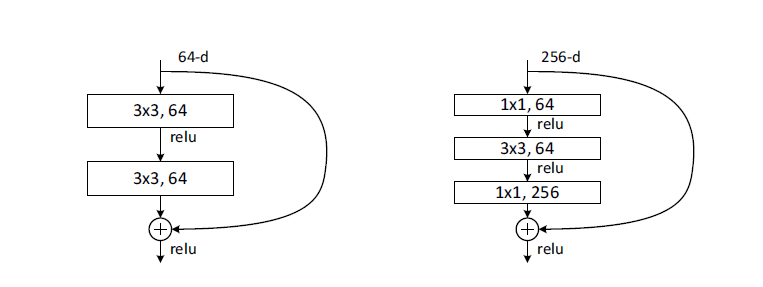
普通残差模块,用于ResNet-18/34
bottleneck残差模块,用于ResNet-50/101/152
$1\times1$卷积,先降维后升维
减少参数量与计算量
Plain Network(普通无残差网络)

ResNet
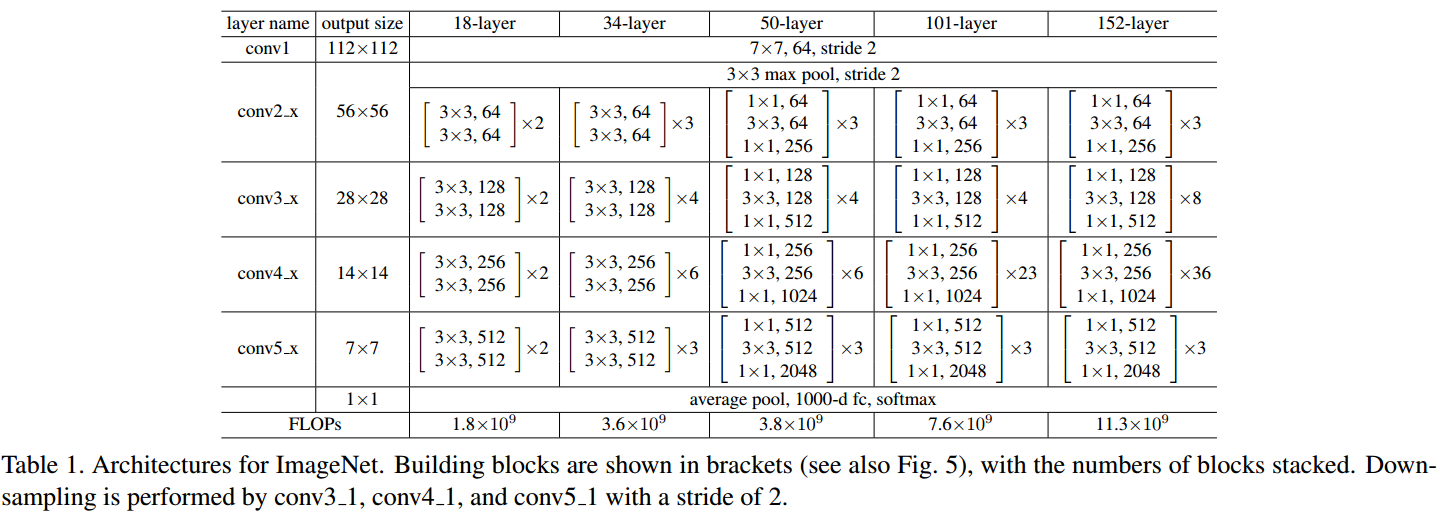
- ResNet中,所有的Residual Block都没有pooling层,降采样是通过conv的stride实现的;
- 分别在conv3_1、conv4_1和conv5_1 Residual Block,降采样1倍,同时feature map数量增加1倍,如图中虚线划定的block;
- 通过Average Pooling得到最终的特征,而不是通过全连接层;
- 每个卷积层之后都紧接着BatchNorm layer。
拓展阅读
ResNet解决退化问题机理
深层梯度回传顺畅
- 恒等映射这一路的梯度是1,把深层梯度注入底层,防止梯度消失。
类比其它机器学习模型
- 集成学习 boosting,每一个弱分类器拟合“前面的模型与GT之差”
- 长短时记忆神经网络LSTM的遗忘门。
- Relu激活函数。
传统线性结构网络难以拟合“恒等映射”
- skip connection可以让模型自行选择要不要更新
- 弥补了高度非线性造成的不可逆的信息损失。( MobileNet v2)
ResNet反向传播传回的梯度相关性好
The Shattered Gradients Problem: If resnets are the answer, then what is the question?
网络加深,相邻像素回传回来的梯度相关性越来越低,最后接近白噪声但相邻像素之间具有局部相关性,相邻像素的梯度也应该局部相关。相邻像素不相关的白噪声梯度只意味着随机扰动,并无拟合。 ResNet梯度相关性衰减从$\frac{1}{2^L}$加为$\frac{1}{\sqrt L}$。保持了梯度相关性。
ResNet相当于几个浅层网络的集成
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
$2^n$个潜在路径(类似 dropout) 测试阶段去掉某几个残差块,几乎不影响性能
skip connection可以实现不同分辨率特征的组合
FPN、 DenseNet
ResNet数学本质是用微分方程的积分曲线去拟合系统的目标函数;构造了一个平滑的解空间流形,在这个平滑的流形上更容易找到解。 残差网络相当于不同长度的神经网络组成的组合函数;残差模块相当于一个差分放大器
孙剑首个深度学习博士张祥雨:3年看1800篇论文,28岁掌舵旷视基础模型研究
PreResNet:Identity Mappings in Deep Residual Networks-2016
ResNeXt
文章标题:Aggregated Residual Transformations for Deep Neural Networks
作者:Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He
发表时间:(CVPR 2017)
设计block遵循以下两个规则:
如果输出相同 size 的 spatial map, 那么,block 的 hyper-parameters (即 width 和 filter size) 相同
feature map大小缩减一半,通道数增一倍。
这个规则保证了每个block的计算复杂度几乎一致!
ResNeXt
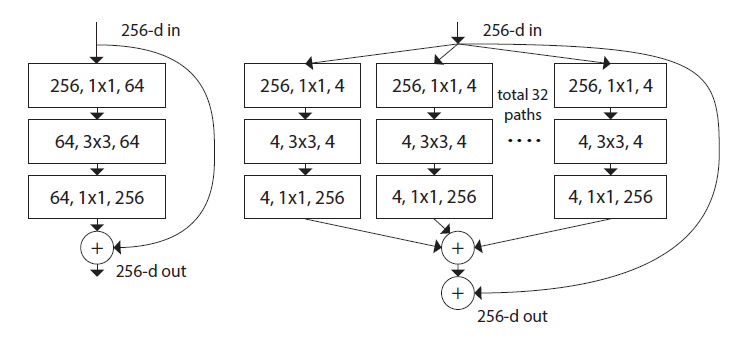
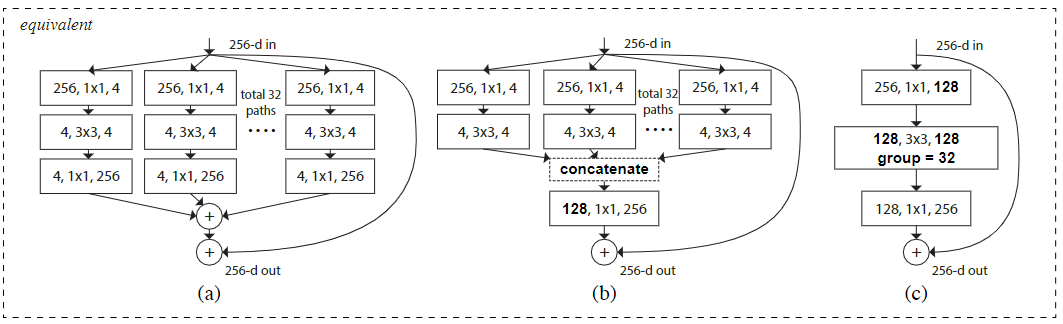
三种等价
b和Inception V3类似,但b是同构
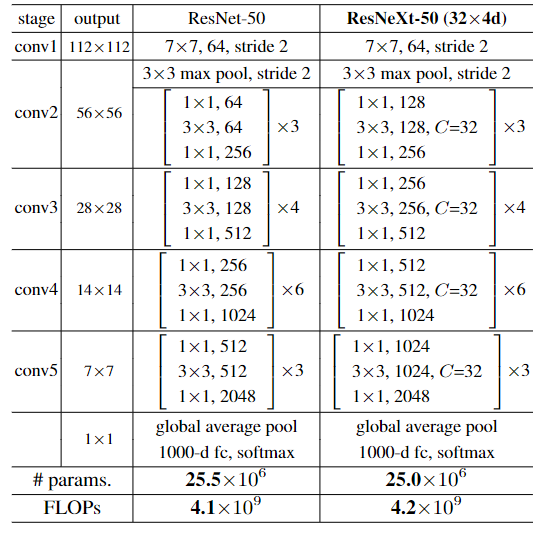
ResNeXt-50(32x4d):32指进入网络的第一个ResNeXt基本结构的分组数量C(即cardinality基数)为32,4d表示depth即每一个分组的通道数为4(所以第一个基本结构输入通道数为128)
拓展阅读
Review: ResNeXt — 1st Runner Up in ILSVRC 2016 (Image Classification)
Exploring the Limits of Weakly Supervised Pretraining-ECCV-2018
在 2019 年,facebook 通过弱监督学习研究了该系列网络在 ImageNet 上的精度上限,为了区别之前的 ResNeXt 网络,该系列网络的后缀为 wsl,其中 wsl 是弱监督学习(weakly-supervised-learning)的简称。为了能有更强的特征提取能力,研究者将其网络宽度进一步放大,其中最大的 ResNeXt101_32x48d_wsl 拥有 8 亿个参数,将其在 9.4 亿的弱标签图片下训练并在 ImageNet-1k 上做 finetune,最终在 ImageNet-1k 的 top-1 达到了 85.4%。Fix-ResNeXt 中,作者使用了更大的图像分辨率,针对训练图片和验证图片数据预处理不一致的情况下做了专门的 Fix 策略,并使得 ResNeXt101_32x48d_wsl 拥有了更高的精度,由于其用到了 Fix 策略,故命名为 Fix-ResNeXt101_32x48d_wsl。
ResNeSt
文章标题:ResNeSt: Split-Attention Networks
作者:Hang Zhang, Chongruo Wu, Zhongyue Zhang, Yi Zhu, Haibin Lin, Zhi Zhang, Yue Sun, Tong He, Jonas Mueller, R. Manmatha, Mu Li, Alexander Smola
发表时间:(2020)
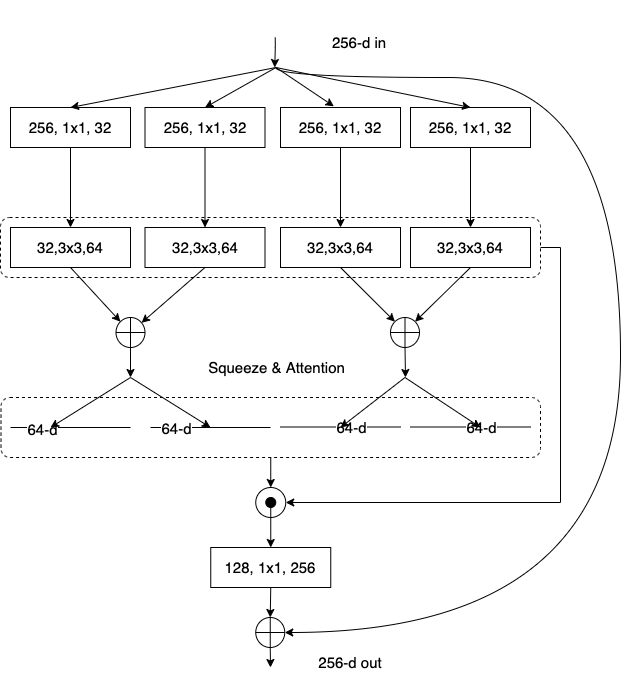
Split-Attention Networks
Split-Attention Block
featuremap group and split attention operations
ResNeSt中每个块将特征图沿着channel维度划分为几个组(groups)和更细粒度的子组(splits),每个组的特征表示是由其splits的表示的加权组合来确定的(根据全局上下文信息来确定权重),将得到的这个单元称之为 Split-Attention block
featuremap group
借鉴了ResNeXt网络的思想,将输入分为K个,每一个记为Cardinal1-k ,然后又将每个Cardinal拆分成R个,每一个记为Split1-r,所以总共有G=KR个组
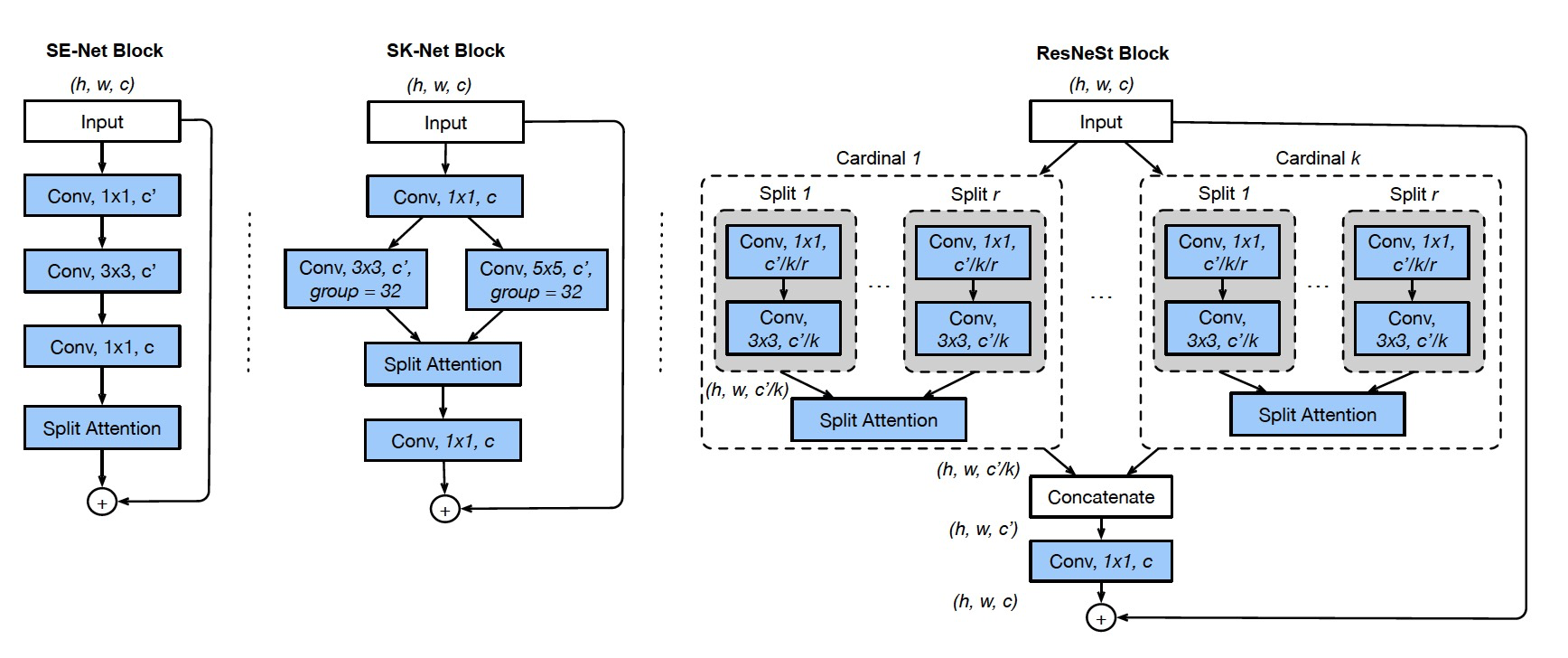
Split Attention in Cardinal Groups
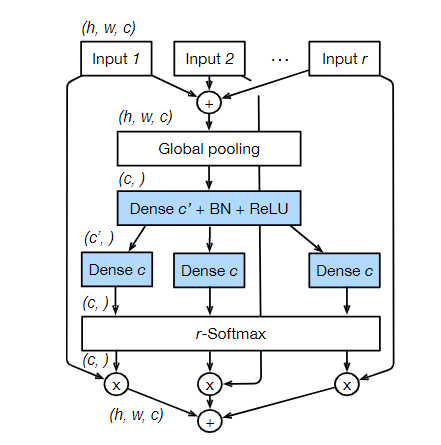
$\hat U^k\in R^{H\times W\times C/K}$;$s^k\in R^{C/K}$;$k\in1,2,…,K$;$H、W $和$ C $是block输出特征图的大小
$$ a_i^k(c) = \begin{cases} \frac{\exp(G_i^c(s^k))}{\sum_{j=1}^R \exp(G_i^c(s^k))} & \text{if } R > 1 \\ \frac{1}{1 + \exp(-G_i^c(s^k))} & \text{if } R = 1 \end{cases} $$$$ V_c^k=\sum_{i=1}^R a_i^k(c)U_{R(k-1)+1}\\ V =Concat\{V^1,V^2,...,V^K\} $$G:注意力权重函数G是两个全连接层(Dense)外加relu激活函数;如果R=1的话就是对该Cardinal中的所有通道视为一个整体
$\hat V^k\in R^{H\times W\times C/K}$
Radix-major Split-Attention Block
转换成这一形式是为了便于使用标准的CNN进行加速(像group convolution, group fully connectd layer等)
在 channel 维度上被分为 cardinal 个不同的组,每个组叫 cardinal groups。可以把这个 cardinal group 继续分成 radix 个小组。这样每个组都一个 cardinal 的序号,和 radix 的序号。

展示出从 cardinality-major 到 radix-major 的变化过程
 | 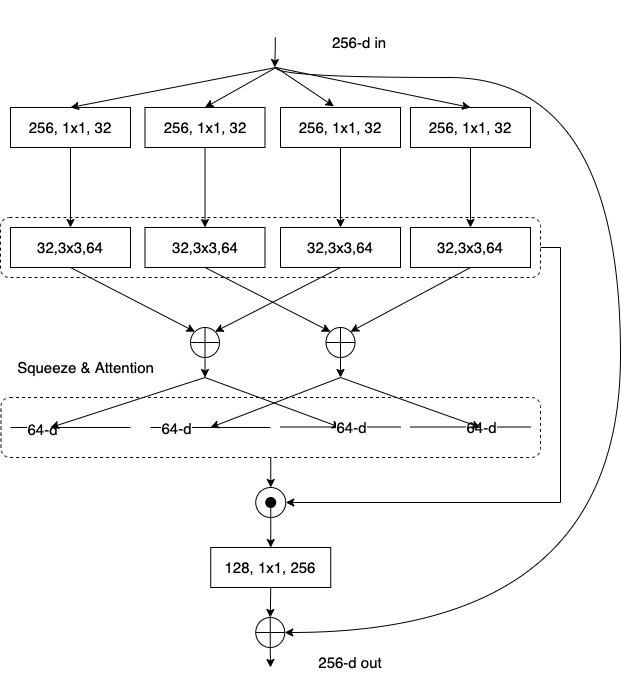 |  |
| cardinality-major | 中间变换 | radix-major |
Channel/group shuffling equivariant:
全局平均池化层:把 channel 维度任意打乱,再通过全局平均池化层,然后再把 channel 顺序还原
批量归一化 (Batch Normalization):打乱 channel,然后再还原,保证 BN 层的 gamma 和 beta 也相应调整顺序
分组卷积
1x1 卷积与全连接层:1x1 的分组卷积来实现多个并行的全连接层
If several consecutive modules are shuffling-equivariant, then the entire block is shuffling-equivariant.
| |
Network and Training
Network Tweaks
平均下采样: 对于检测和分割任务,下采样过程对于保持空间信息非常重要,ResNeSt采用的是平均池化方法,使用$3\times3$的kernel来很好的保持空间信息。
从ResNet-D中学到的策略:用3个$3\times3$卷积替代一个$7\times7$卷积;加了一个$2\times2$的平均池化到skip connection里去。
Training Strategy
- 大型小批量分布式训练:$\eta =\frac{B}{256}\eta_{base}$; B 為为mini-batch size、base learning rate 设定为0.1;在前五個个epoch 使用 warm-up strategy 逐渐增加 learning rate
- Label Smoothing
- Auto Augmentation
- Mixup Training
- 则化:可以选择dropout、DropBlock、L2正则化方法。
Ablation Study
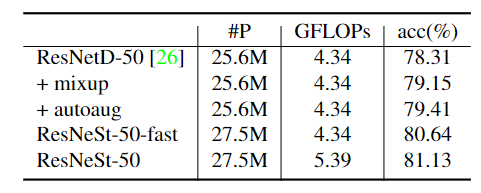 | 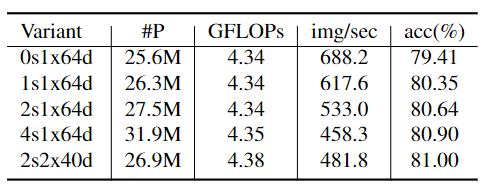 |
| breakdown of improvement | radix vs. cardinality under ResNeSt-fast setting |
补充来源 setting #P GFLOPs PyTorch Gluon ResNeSt-50-fast 1s1x64d 26.3M 4.34 80.33 80.35 ResNeSt-50-fast 2s1x64d 27.5M 4.34 80.53 80.65 ResNeSt-50-fast 4s1x64d 31.9M 4.35 80.76 80.90 ResNeSt-50-fast 1s2x40d 25.9M 4.38 80.59 80.72 ResNeSt-50-fast 2s2x40d 26.9M 4.38 80.61 80.84 ResNeSt-50-fast 4s2x40d 30.4M 4.41 81.14 81.17 ResNeSt-50-fast 1s4x24d 25.7M 4.42 80.99 80.97 2s2x40d :radix=2, cardinality=2 and width=40
拓展阅读
https://github.com/zhanghang1989/ResNeSt/issues/74
https://github.com/zhanghang1989/ResNeSt/issues/4
https://github.com/zhanghang1989/ResNeSt/issues/41
DenseNet
文章标题:Densely Connected Convolutional Networks
作者:Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger
发表时间:(CVPR 2017)
稠密连接网络(DenseNet)在某种程度上是ResNet的逻辑扩展
相比 ResNet 中的 bottleneck,dense-block 设计了一个更激进的密集连接机制,即互相连接所有的层,每个层都会接受其前面所有层作为其额外的输入。
DenseNet 将所有的 dense-block 堆叠,组合成了一个密集连接型网络。
密集的连接方式使得 DenseNet更容易进行梯度的反向传播,使得网络更容易训练。
Motivation动机
DenseNets 不是从极深或极宽的架构中汲取表征能力,而是通过特征重用来利用网络的潜力。
Q:从输入层到输出层的信息路径(以及相反方向的梯度)变得很大,以至于它们可能在到达另一边之前就消失了。
只需将每一层直接相互连接起来:解决了确保最大信息(和梯度)流动的问题。
每一层都可以直接访问损失函数和原始输入图像的梯度。
缺点:反向传播虽然容易,但是计算复杂
Q:DenseNets 比等效的传统 CNN 需要更少的参数
不需要学习冗余特征图:对于旧的特征图(feature-map)是不需要再去重新学习的
特征重用缺点:训练模型时RAM会爆炸
growth-rate不用设很大,所以减少许多参数。
growth-rate:卷积层中卷积核的数量(k),DenseNet:k=12
卷积块的通道数控制了输出通道数相对于输入通道数的增长,因此也被称为增长率
Memory-Efficient Implementation of DenseNets
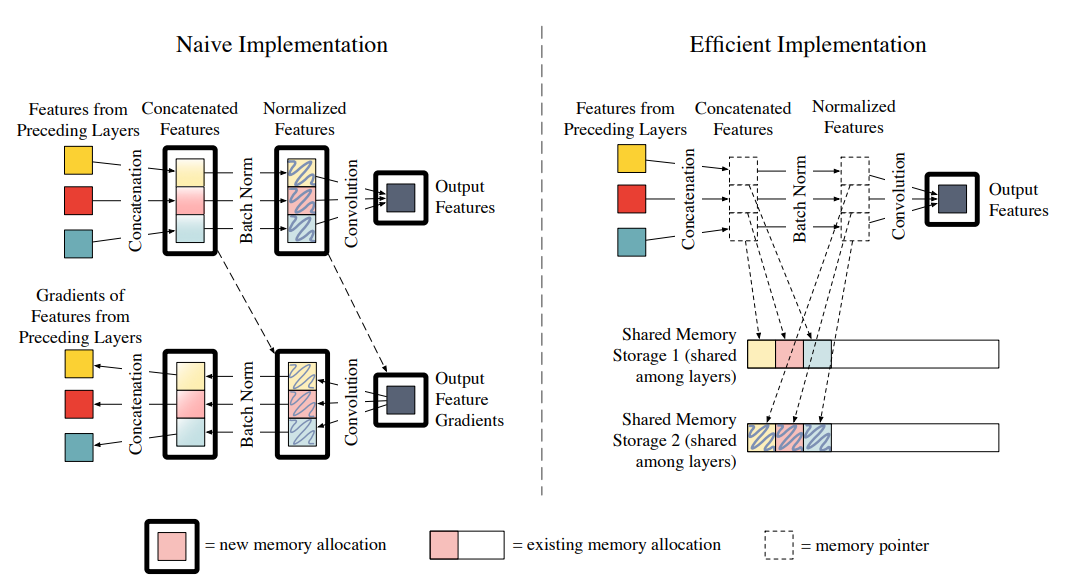
DenseNet
假如我们有$L$层卷积神经网路,那就有$L$个(层与层之间的)连结。但是DenseNet设计成有$\frac{L(L+1)}{2}$个连结。

稠密块(dense block)
一个稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道。在前向传播中,我们将每个卷积块的输入和输出在通道维上连结。
过渡层(transition layer)
过渡层可以用来控制模型复杂度。通过$1\times1$卷积层来减小通道数,并使用步幅为2的平均汇聚层减半高和宽,从而进一步降低模型复杂度。
为什么在过渡层使用平均汇聚层而不是最大汇聚层?
参考:平均池化的特点是保留背景信息让每一个信息对最后的输出都有帮助,最大池化的特点是提取特征只保留特征最明显的信息,当我们费劲心力把不同层的信息叠在了一起以后用最大池化等于前面都做了无用功
Model
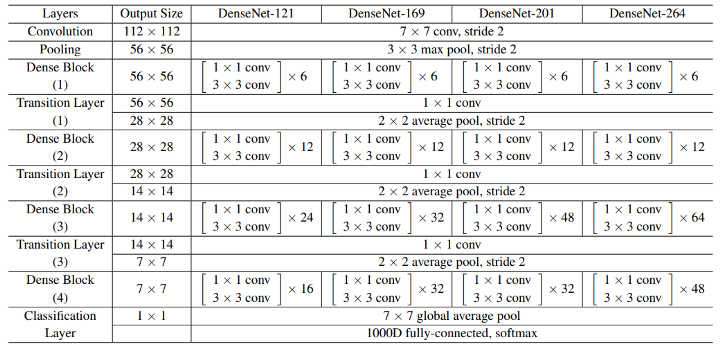
DenseNet-121是指网络总共有121层:(6+12+24+16)*2 + 3(transition layer) + 1(7x7 Conv) + 1(Classification layer) = 121。
DenseNet首先使用同ResNet一样的单卷积层和最大汇聚层。
类似于ResNet使用的4个残差块,DenseNet使用的是4个稠密块。
在每个模块之间,ResNet通过步幅为2的残差块减小高和宽,DenseNet则使用过渡层来减半高和宽,并减半通道数。
与ResNet类似,最后接上全局汇聚层和全连接层来输出结果。
拓展阅读
DenseNet Architecture Explained with PyTorch Implementation from TorchVision
Understanding and visualizing DenseNets
DPN
文章标题:Dual Path Networks
作者:Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, Jiashi Feng
发表时间:(NIPS 2017)
DPN,DPN 的全称是 Dual Path Networks,即双通道网络。
该网络是由 DenseNet 和 ResNet 结合的一个网络,利用残差网络的跳跃连接对特征进行复用,又可以利用密集连接路径持续探索新特征。
DenseNet 把每一层的输出都拼接(concatenate)到其后每一层的输入上,从靠前的层级中提取到新的特征。 善于挖掘新特征,冗余度高
ResNet 把输入直接加到(element-wise adding)卷积的输出上是对之前层级中已提取特征的复用。善于复用特征,冗余度低
$[W_1 \ W_2][X_1;X_2]=W_1X_1+W_2X_2$:如果两组conv,输出的filter个数是一样的,那么在input channel上concat是可以等价于分别两组conv求和的形式
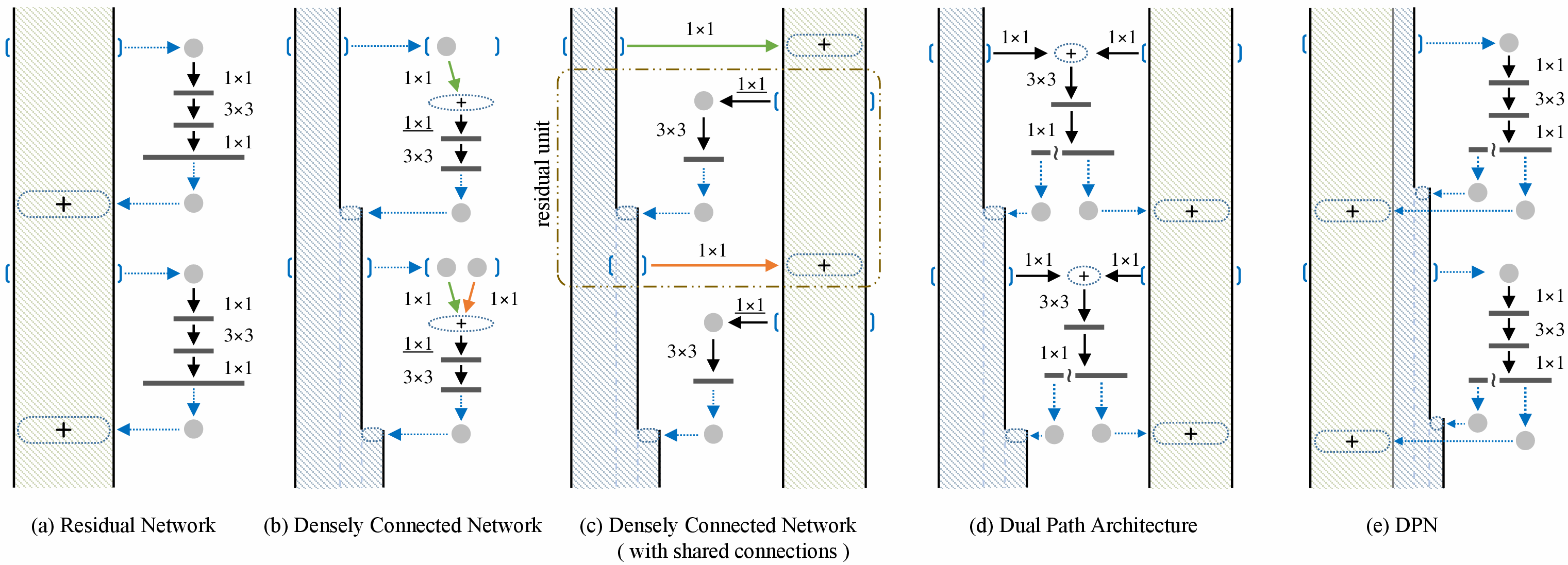
(a) 残差网络。
(b) 密集连接的网络,其中每一层都可以访问所有先前微块的输出。在这里,为了与(a)中的微块设计保持一致,添加了一个 1×1 卷积层(下划线)。
(c) 通过在 (b) 中的微块之间共享相同输出的第一个 1×1 连接,密集连接的网络退化为残差网络。(c) 中的虚线矩形突出显示了残差单元。
(d) 双路径架构,DPN。
(e) 从实现的角度看(d)的等价形式,其中符号“~”表示拆分操作,“+”表示逐元素加法
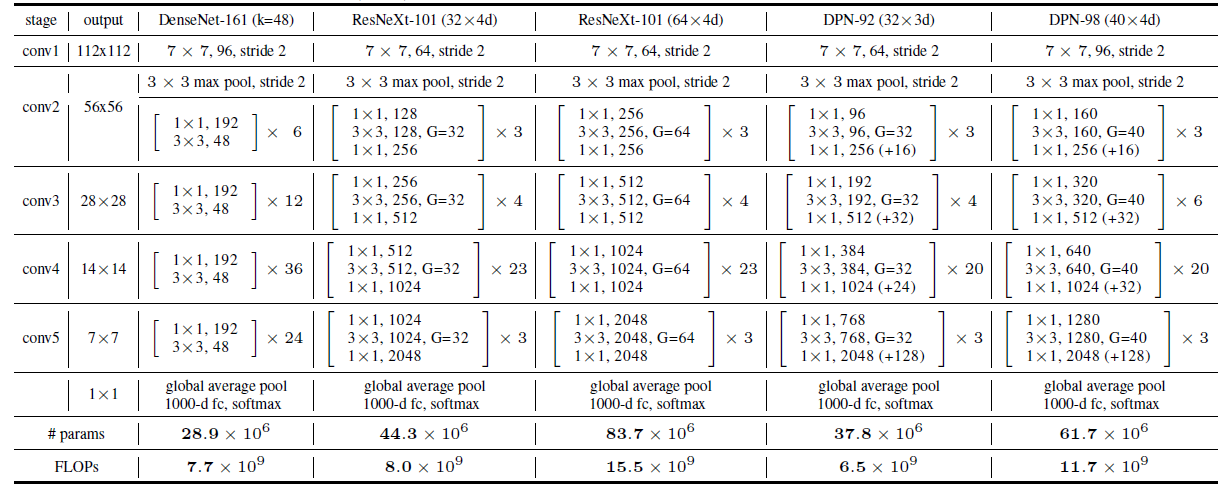
- $3\times3$ 的卷积层采用的是 group convolution
- $1×1×256(+16) $中的 256 代表的是 ResNet 的通道数,16 代表的是 DenseNet 一层的输出通道数,将结果分成 256 和 16 两部分,256 的 element-wise 的加到 ResNet 通道,16 的 concat 到 DenseNet 通道,然后继续下一个 block,同样输出 256 + 16 个通道,重复操作。
拓展阅读
知乎:解读Dual Path Networks(DPN,原创)
知乎:卷积神经网络学习路线(十五) | NIPS 2017 Dual Path Network
HarDNet
文章标题:HarDNet: A Low Memory Traffic Network
作者:Ping Chao, Chao-Yang Kao, Yu-Shan Ruan, Chien-Hsiang Huang, Youn-Long Lin
发表时间:(ICCV 2019)
HarDNet,HarDNet(Harmonic DenseNet)是 2019 年由国立清华大学提出的一种全新的神经网络,在低 MAC 和内存流量的条件下实现了高效率。与 FC-DenseNet-103,DenseNet-264,ResNet-50,ResNet-152 和 SSD-VGG 相比,新网络的推理时间减少了 35%,36%,30%,32% 和 45%。使用了包括 Nvidia Profiler 和 ARM Scale-Sim 在内的工具来测量内存流量,并验证推理延迟确实与内存流量消耗成正比,并且所提议的网络消耗的内存流量很低。
评价指标
Nvidia profiler获取DRAM读/写的字节数。
ARM Scale Sim获取每个CNN框架的流量数据和推理次数。
Convolutional Input/Output (CIO):每个卷积层的输入和输出尺寸之和。CIO是DRAM流量的近似处理。
MoC(MACs over CIO)。在MoC低于某个值时,CIO才会在推理时间中占主导地位。
对每一层的MoC施加一个软约束,以设计一个低CIO网络模型,并合理增加MACs。
首先减少来自DenseNet的大部分层连接,以降低级联损耗。然后,通过增加层的通道宽度来平衡输入/输出通道比率。
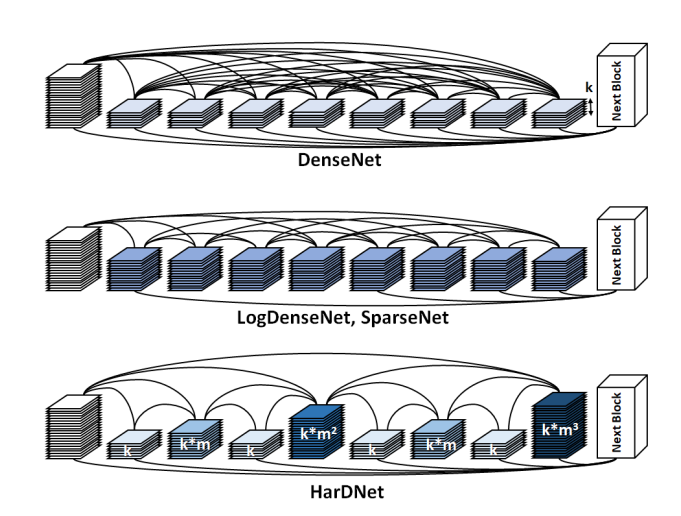
采用的稀疏连接方式:当$k$能被$2^n$整除,让$k$层和$k-2^n$层相连,其中$n$为非负整数;并且还需满足$k-2^{n} \ge 0$。
$l$层初始化growth-rate k
卷积层中卷积核的数量(k),DenseNet:k=12
m 用作低维压缩因子
通道数:$k\times m^n$,n是$l$除以$2^n$时的最大数
在HDB后连接一个1x1 conv层,作为trainsition。此外,设置HDB的深度为$L=2^n$,这样一个HDB的最后一层就有最大的通道数,梯度最多能传输$\text{log}L$层。为了缓解这种梯度消失,将一个HDB的输出设置为第L层和它前面所有奇数层的级联。当完成HDB以后,就可以丢弃从2至L-2的所有偶数层。当m=1.6-1.9时,这些偶数层的内存占用是奇数层的2至3倍。
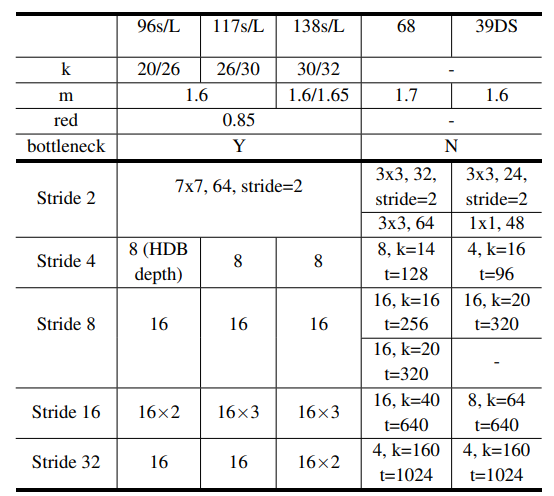
3x3, 64:64个输出通道的Conv3x3层
8,k=14,t=256:有8层的HDB,增长率k和一个有t个输出通道的trainsition过渡层 conv1x1
m :低维压缩因子
所有层的Conv-BN-ReLU,而不是DenseNet中使用的BN-ReLU-Conv
实现折叠批量标准化
HardNet-68 中每个 HDB 的专用增长率 k 提高了 CIO 效率。
由于深度 HDB 具有更多的输入通道,因此更大的增长率有助于平衡层的输入和输出之间的通道比率,以满足对MoC 约束。
对于层分布,没有集中在大多数 CNN 模型采用的 stride16 上,而是让 stride8 在 HardNet-68 中拥有最多的层,
提高了局部特征学习,有利于小规模目标检测。相比之下,分类任务更多地依赖全局特征学习,因此专注于低分辨率可以获得更高的准确度和更低的计算复杂度
拓展阅读
ResNet_D
文章标题:Bag of Tricks for Image Classification with Convolutional Neural Networks
作者:Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li
发表时间:(CVPR 2019)
Basline Implemention
- 预处理与数据增强
- 随机sample并且转化为[0,255]之间的32位宽浮点数
- 随机Crop的高宽比在3/4到4/3;面积占比大小从8~100%;最后被Resize到[224,224]
- 50%概率水平翻转
- 缩放色调,饱和度和亮度,取[0.6,1.4]
- 加上PCA Noise
- 最后Normalize整个图片
- (对测试的时候,不做增强,首先对图片按照短边resize到256,再随机Crop到244,然后Normalize)
- 采用Xavier初始化
- 使用加Nesterov加速的SGD(NAG)
- batch-size: 256
- 共训练120 epoch
- lr 0.1(30,60,90 epoch上除以10)
Efficient Training
Large-batch training
与小批量训练的模型相比,使用大批量训练训练的模型的验证精度降低
如何解决:四种启发式方法,有助于扩大单机训练的批处理规模
Linear scaling learning rate 线性缩放学习率。
在小批量SGD中,梯度下降是一个随机过程,因为每批样本都是随机选取的。增加批处理大小并不会改变随机梯度的期望,但会降低其方差。换句话说,大的batch size会降低gradient中的noise。
随批大小线性增加学习率对ResNet-50训练有效。选取0.1作为批量大小为256的初始学习率,那么当批量大小为b时,我们将初始学习率提高到0.1 × b/256。
learning rate warmup
一开始使用较小的学习率,然后在训练过程稳定时切换回初始学习率。
一种渐进的预热策略,将学习率从0线性增加到初始学习率。
Zero $\gamma$
BN 的$\gamma$和$\beta$一般分别初始化为1和0
Zero $\gamma$:对位于残差块末端的所有BN层初始化$\gamma=0$。
因此,所有的残差块都只是返回它们的输入,模拟的网络,它的层数较少,在初始阶段更容易训练。Therefore, all residual blocks just return their inputs, mimics network that has less number of layers and is easier to train at the initial stage.
No bias decay
将权值衰减应用于卷积层和全连接层中的权值。其他参数,包括偏置和在BN层的γ和β,保持不正则化
Low-precision training
将所有参数和激活存储在FP16中,并使用FP16计算梯度。同时,所有参数在FP32中都有一个副本,用于参数更新。此外,将一个标量乘以损失,以更好地将梯度范围对齐到FP16
结论
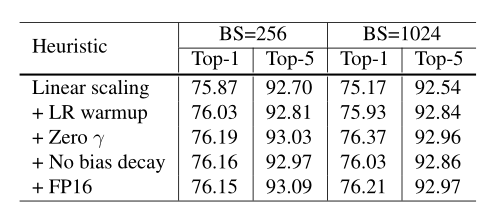
与基线模型相比,1024批大小和FP16训练的模型甚至略微提高了0.5%的top-1精度。
仅通过线性缩放学习率将批量大小从256增加到1024会导致top-1准确率下降0.9%,而堆叠其余三个启发式方法可以弥补这一差距。训练结束时从FP32切换到FP16不会影响精度。
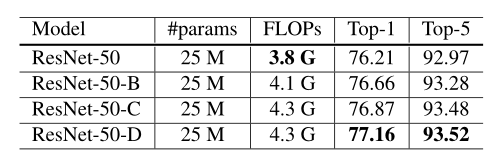
Model Tweaks
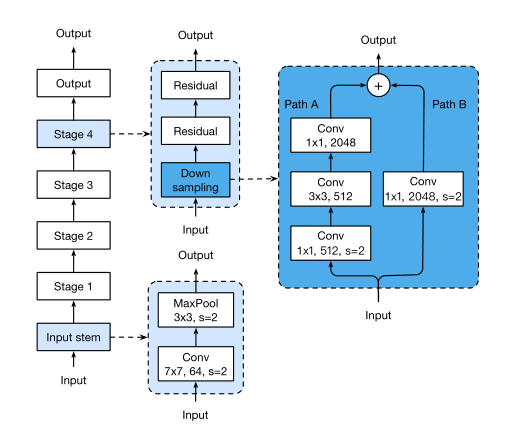 | 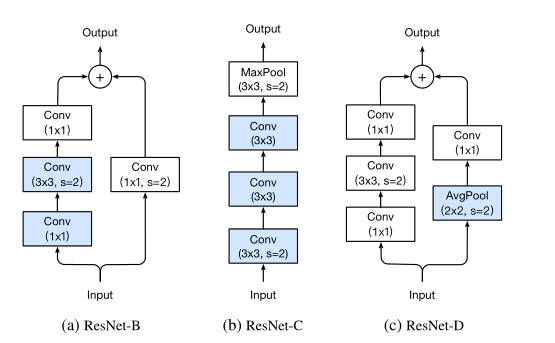 |
| Resnet50 | ResnetB-C-D |
ResNet-B:前两个卷积的步长进行了切换
Path A中的卷积忽略了四分之三的输入特征映射,因为它使用了一个跨步为2的内核大小1×1。
ResNet-C:Input stem 的$7\times7$卷积替换成3个$3\times 3$
ResNet-B:ResNet-B基础上增加一个stride为2的2×2平均池化层,将$1\times1$卷积stride改为1
Path B中的卷积忽略了四分之三的输入特征映射,因为它使用了一个跨步为2的内核大小1×1。
Training Refinements
Cosine learning rate decay
$\eta_{t}=\frac{1}{2}\left(1+\cos \left(\frac{t \pi}{T}\right)\right) \eta $,其中是$\eta$初始化学习率。
label smoothing
通常分类任务中每张图片的标签是one hot形式的,也就是说一个向量在其对应类别索引上设置为1,其他位置为0,形如[0,0,0,1,0,0]。
label smoothing就是将类别分布变得平滑一点,即
$q_{i}=\left{\begin{array}{ll}{1-\varepsilon} & {\text { if } i=y} \ {\varepsilon /(K-1)} & {\text { otherwise }}\end{array}\right. $
其中$q_{i}$就代表某一类的ground truth,例如如果\(i==y\),那么其最终真实值就是$1-\varepsilon$,其它位置设置为$\varepsilon /(K-1)$,而不再是。这里的$\varepsilon$=0.1
Knowledge Distillation
T=20
Mixup
每次随机抽取两个样本进行加权求和得到新的样本,标签同样做加权操作。公式中的$\lambda\in[0,1]$是一个随机数,服从$\text{Beta}(\alpha,\alpha)$分布。$\alpha=0.2$
$\begin{aligned} \hat{x} &=\lambda x_{i}+(1-\lambda) x_{j} \ \hat{y} &=\lambda y_{i}+(1-\lambda) y_{j} \end{aligned} $
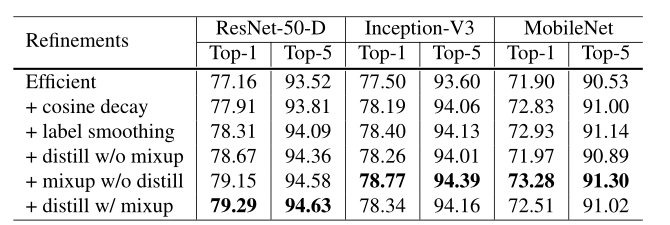
蒸馏在ResNet上工作得很好,然而,它在Inception-V3和MobileNet上不太好。
可能解释是:教师模型不是来自于学生的同一家庭,因此在预测中分布不同,给模型带来了负面影响
拓展阅读
Bag of tricks for image classification with convolutional neural networks review [cdm]
ResNet strikes back: An improved training procedure in timm Top-1:80.4%
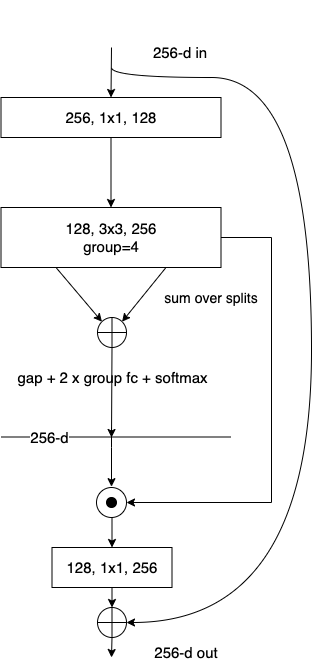
Res2Net
文章标题:Res2Net: A New Multi-scale Backbone Architecture
作者:Shang-Hua Gao, Ming-Ming Cheng, Kai Zhao, Xin-Yu Zhang, Ming-Hsuan Yang, Philip Torr
发表时间:(TPAMI 2020)
通过在一个残差块中构筑类似残差分层的方式进行连接。Res2Net 可以在更细粒度级别表达多尺度特征,并且可以增加每层网络的感受野大小。
Res2Net 揭示了一个新的提升模型精度的维度,即 scale,其是除了深度、宽度和基数的现有维度之外另外一个必不可少的更有效的因素。
 |  |
| Res2Net_Module:s=4 | Res2Net_Module + group_conv + SE_block集成 |
在$1\times1$卷积层后面,将特征图分为s个子集($s$为尺度(scale)维度)
原有的$n$通道$3\times3$滤波器替换为一系列有$w$通道的更小的滤波器组(避免损失,令$n = s × w$);子集有着和原始特征图集相同的空间大小。
每一组滤波器先从一组输入特征图中进行特征提取,然后与先前组生成的特征图和另一组输入的特征图一起被送到下一组卷积核进行处理。
小滤波器组以类似于残差的模式被逐层连接,这样可以增加输出特征能表达的不同尺度的数量。
最终,所有特征图将被拼接在一起并被送到一组$1\times1$的卷积核处进行信息融合。
忽略了第一个分组的卷积层:这也是一种特征复用的形式,减少参数并增加$s $的数量
拓展阅读
RedNet
文章标题:Involution: Inverting the Inherence of Convolution for Visual Recognition
作者:Duo Li, Jie Hu, Changhu Wang, Xiangtai Li, Qi She, Lei Zhu, Tong Zhang, Qifeng Chen
发表时间:(CVPR 2021)
普通convolution
空间不变性(spatial-agnostic)
平移等价性
大小一般3x3,偏小
通道特异性(channel-specific)
不同通道包含不同语义信息
不同通道的卷积核存在冗余
希望具有:自适应长距离关系建模
involution
通道不变性(channel-agnostic): kernel privatized for different positions
空间特异性(spatial-specific): kernel shared across different channels
kernel:$H\in R^{H\times W \times K\times K \times G}$
#groups: G
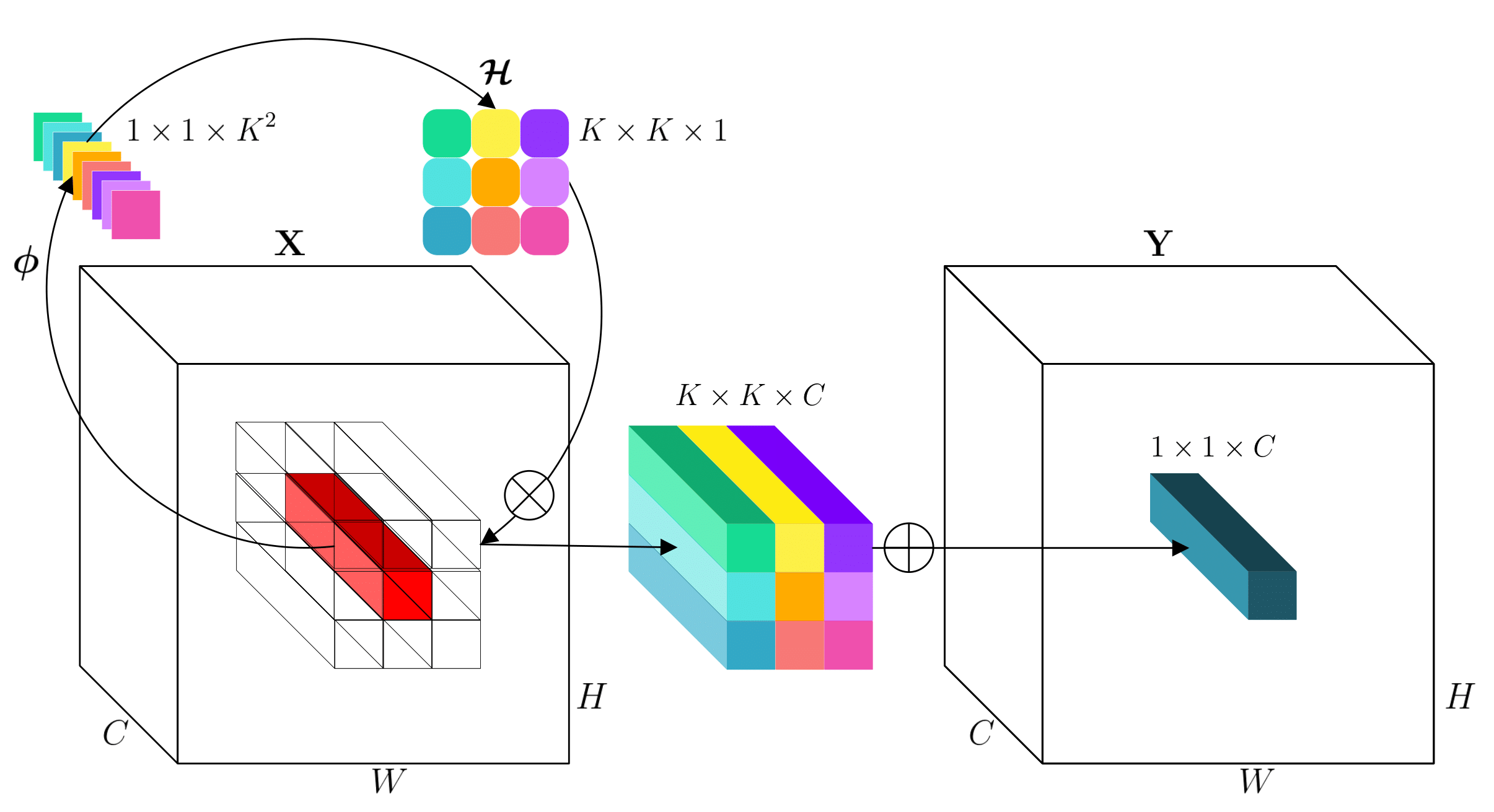
针对输入feature map的一个坐标点上的特征向量,先通过 $\phi$ (FC-BN-ReLU-FC)和reshape (channel-to-space)变换展开成kernel的形状,从而得到这个坐标点上对应的involution kernel,再和输入feature map上这个坐标点邻域的特征向量进行Multiply-Add得到最终输出的feature map。
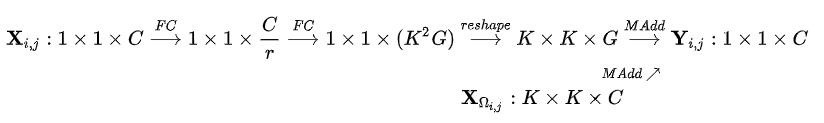
在 ResNet的stem中(使用$3\times 3$或$7\times7$ involution进行分类或密集预测)和trunk(对所有任务使用$7\times7$ involution)位置中的所有bottleneck位置上替换掉了$3\times 3$卷积,但保留了所有的$1\times 1$卷积用于通道映射和融合。这些精心重新设计的实体联合起来,形成了一种新的高效 Backbone 网络,称为 RedNet。
拓展阅读
超越卷积、自注意力机制:强大的神经网络新算子involution
DCDC
文章标题:Dual Complementary Dynamic Convolution for Image Recognition
作者:Longbin Yan, Yunxiao Qin, Shumin Liu, Jie Chen
发表时间:( 2022)
在本文中,我们新颖地将特征建模为局部空间自适应**(LSA)和全局位移不变[GSI]**部分的组合,然后提出了一个双分支双互补动态卷积算子来正确处理这两类特征,显着增强了代表能力。基于所提出的算子构建的 DCDC-ResNets 的性能明显优于 ResNet 基线和大多数最先进的动态卷积网络,同时具有更少的参数和 FLOP。我们还对目标检测、实例和全景分割等下游视觉任务进行了迁移实验,以评估模型的泛化能力,实验结果显示出显着的性能提升