SENet
SENet
文章标题:Squeeze-and-Excitation Networks 作者:Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu 发表时间:(CVPR 2018)
Squeeze-and-Excitation blocks
关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度
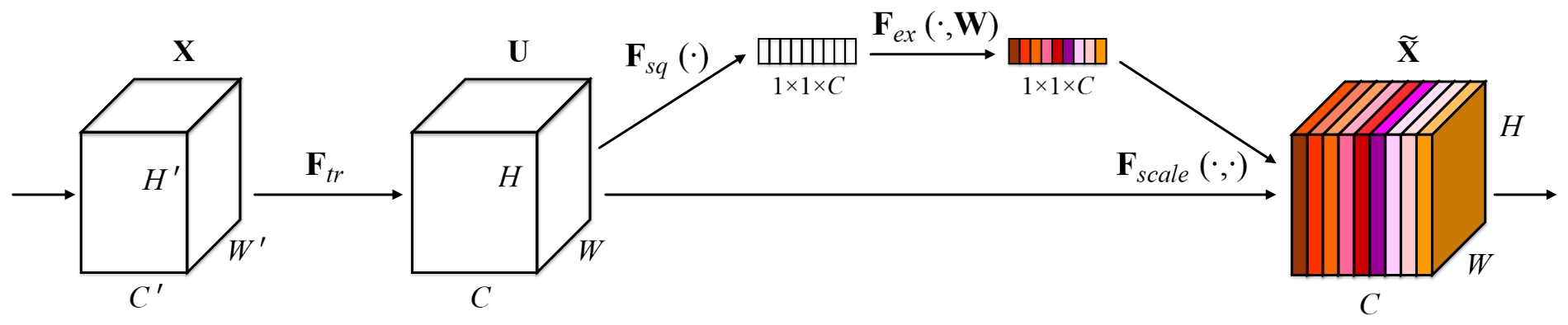
$$ u_c=v_c*X=\sum_{s=1}^{C'}v_c^s*x^s $$$$ z_c=F_{sq}(u_c)=\frac{1}{H\times W}\sum_{i=1}^H\sum_{j=1}^Wu_c(i,j) $$输入:$X=[x^1,x^2,…,x^{C’}]$
输出:$U=[u_1,u_2,…,u_C]$
$v_c=[v_c^1,v_c^2,…,v_c^{C’}] $;$v_c^s$是一个二维空间内核,表示作用于 $X $的相应通道的 $v_c$的单个通道。
卷积核的集合:$V=[v_1,v_2,…,v_C]$
压缩(Squeeze):经过(全局平均池化)压缩操作后特征图被压缩为1×1×C向量;也可以采用更复杂的策略
卷积计算:参数量比较大
最大池化:可能用于检测等其他任务,输入的特征图是变化的,能量无法保持
$$ s=F_{ex}(z,W)=\sigma(g(z,W)) =\sigma(W_2\delta(W_1z)) $$$$ \tilde x_c = F_{scale}(u_c,s_c)=s_cu_c $$$\delta$:ReLU;$\sigma$:sigmoid激活,$W_1\in R^{\frac{C}{r}\times C}$:降维层;$W_2\in R^{C \times\frac{C}{r}}$:升维层
比直接用一个 Fully Connected 层的好处在于
1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;
2)极大地减少了参数量和计算量
c可能很大,所以需要降维
scale操作:最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上
| |
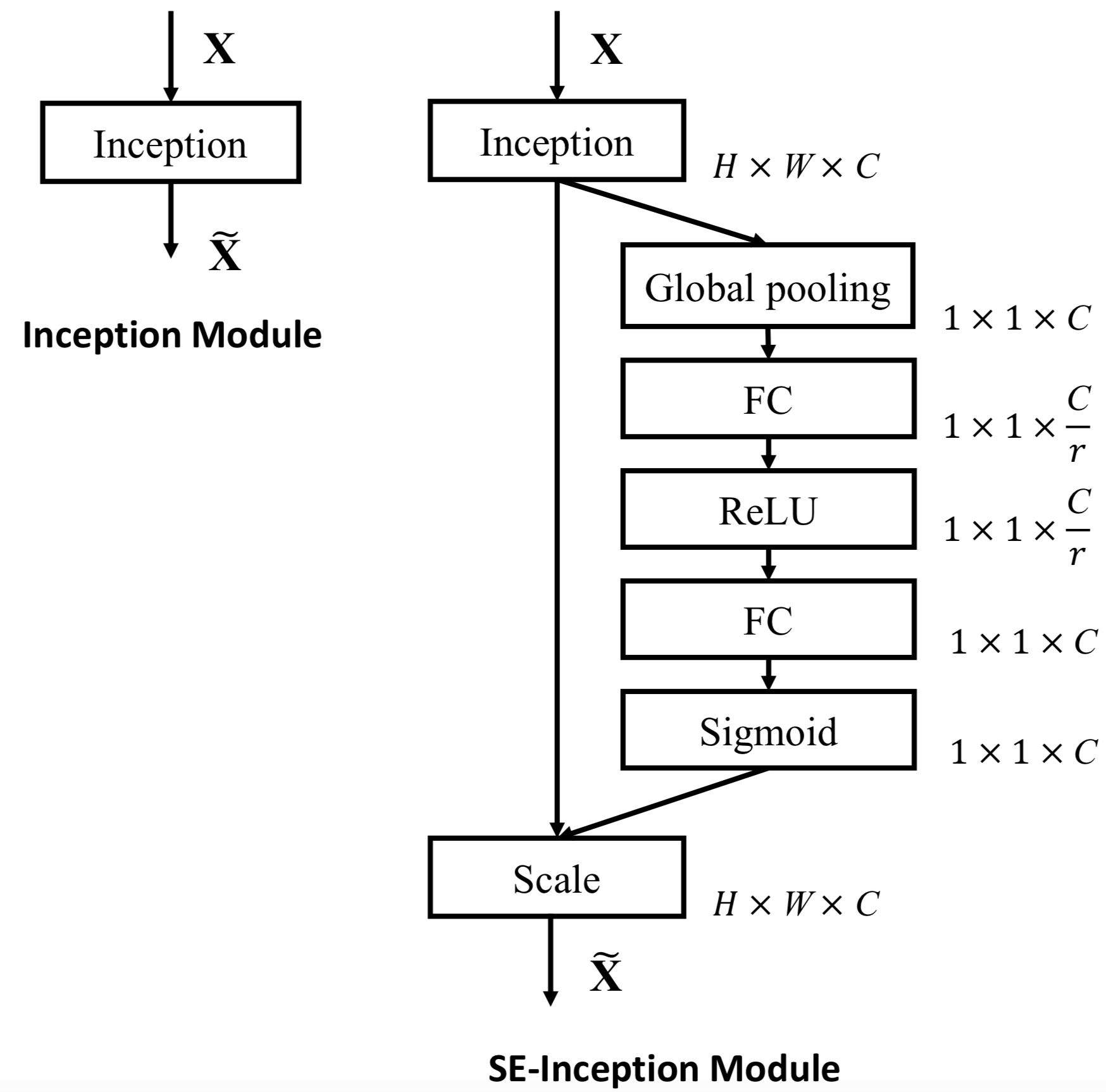 | 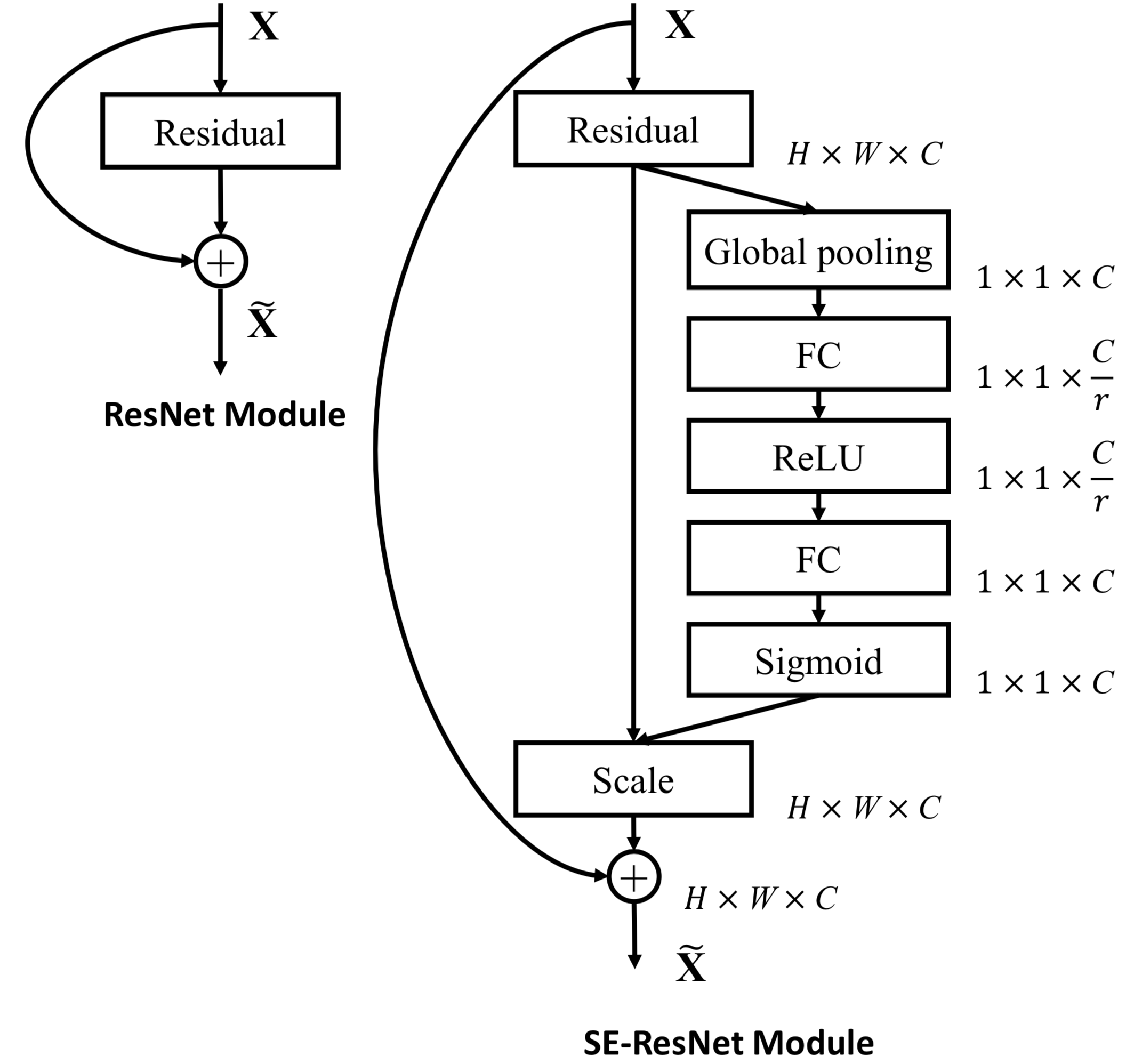 |
| SE-Inception-module | SE-ResNet-module |
Model and computational complexity
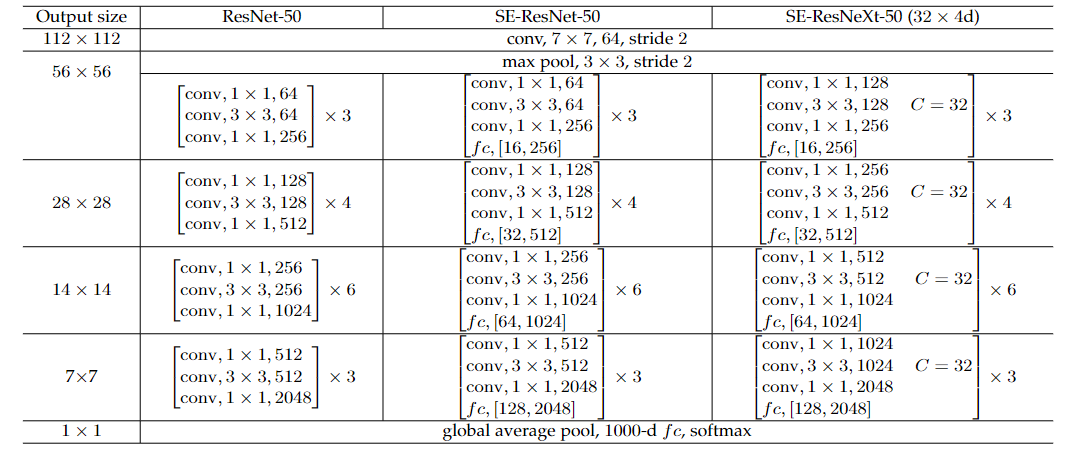
$$ \frac{2}{r}\sum_{s=1}^SN_s\cdot C_s^2 $$reduction为16.
$fc,[16,256]$:16为第一个全连接层的输出通道数;256为第二个全连接层的输出通道数;
$r$表示降维比;$S$:第几个stage;$C_s$ 表示输出通道的维度;$N_s $表示第$s$个stage的重复块的数量
Ablation study
不同Reduction ratio也进行了消融实验。
Squeeze Operator不同操作(如Max,Avg)也进行了消融实验。
Excitation Operator不同激活函数操作(如ReLU,Tanh,Sigmoid)也进行了消融实验。
SE block在不同stage也进行了消融实验。
Integration strategy进行消融实验。
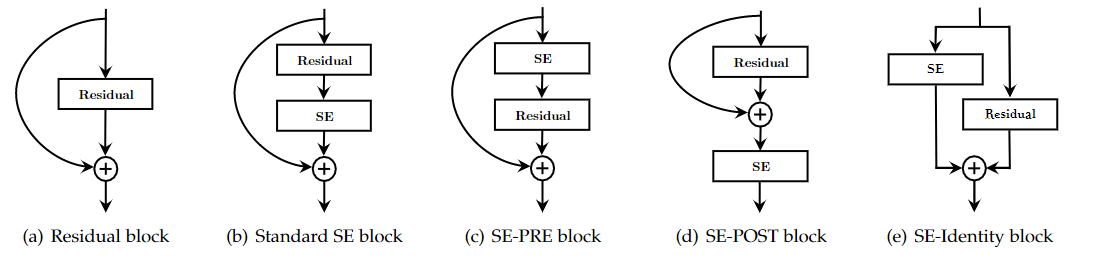 SE block integration designs explored in the ablation study
SE block integration designs explored in the ablation study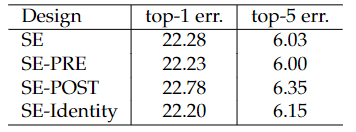 Effect of different SE block integration strategies with ResNet-50 on ImageNet
Effect of different SE block integration strategies with ResNet-50 on ImageNetSE的三种变体:SE 单元在分支聚合之前应用产生的性能改进对其位置相当稳健
如果对 Addition 后主支上的特征进行重标定,由于在主干上存在 0~1 的 scale 操作,在网络较深 BP 优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。
 Effect of integrating SE blocks at the 3x3 convolutional layer of each residual branch in ResNet-50 on ImageNet
Effect of integrating SE blocks at the 3x3 convolutional layer of each residual branch in ResNet-50 on ImageNet另一种设计变体:将 SE 块移动到残差单元内,将其直接放在 3×3 卷积层之后。
以更少的参数实现了可比的分类精度
Role of SE blocks
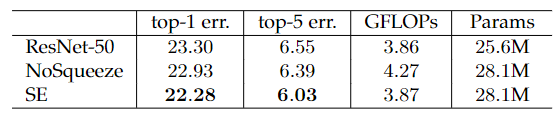
Effect of Squeeze:强调了挤压操作的重要,作为对比,它添加了相同数量的参数,删除了池化操作,用具有相同通道维度的相应 $1\times1 $卷积替换了两个 FC 层,即 NoSqueeze,其中激励输出保持空间维度作为输入。
Role of Excitation
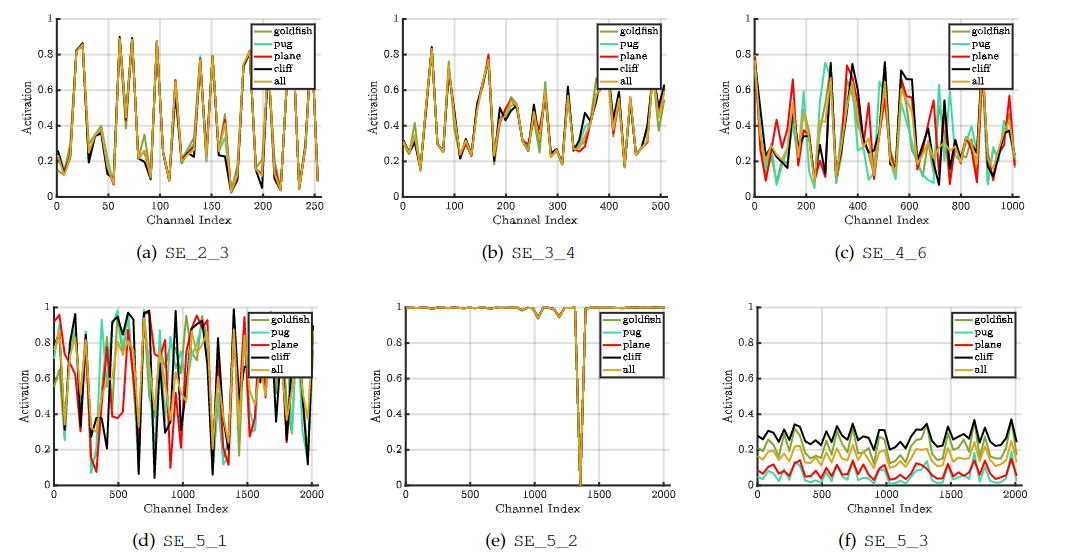
$$ SE\_5\_2:SE\_{stageID}\_{blockID} $$不同类别的分布在网络的早期层非常相似,表明特征通道的重要性很可能在早期由不同的类别共享
后面的层特征表现出更高水平的特异性
SE_5_2表现出一种有趣的趋向于饱和状态的趋势,大多数激活都接近于 1
SE_5_3 的网络末端(紧随其后的是分类器之前的全局池),在不同的类中出现了类似的模式
为网络提供重新校准方面不如之前的块重要,通过移除最后阶段的 SE 块,可以显着减少额外的参数计数,而性能只有边际损失
训练细节
每个瓶颈构建块的前$ 1\times1 $卷积通道的数量减半以降低模型的计算成本性能下降最小。
第一个$ 7 \times 7 $卷积层被三个连续的 $3 \times3 $卷积层替换。(Inception)
具有步长为2 的 $1 \times 1 $下采样卷积被替换为$ 3 \times 3$ 步长为2的 卷积以保留信息。
在分类层之前插入一个 dropout 层(dropout 比为 0.2)以减少过度拟合。
在训练期间使用了标签平滑正则化(。
在最后几个训练时期,所有 BN 层的参数都被冻结,以确保训练和测试之间的一致性。
使用 8 个服务器(64 个 GPU)并行进行训练,以实现大批量(2048 个)。初始学习率设置为 1.0
拓展阅读
CV27 Momenta研发总监 孙刚 Squeeze and Excitation Networks上
CV27 Momenta研发总监 孙刚 Squeeze and Excitation Networks下
SKNet
文章标题:Selective Kernel Networks 作者:Xiang Li, Wenhai Wang, Xiaolin Hu, Jian Yang 发表时间:(CVPR 2019)
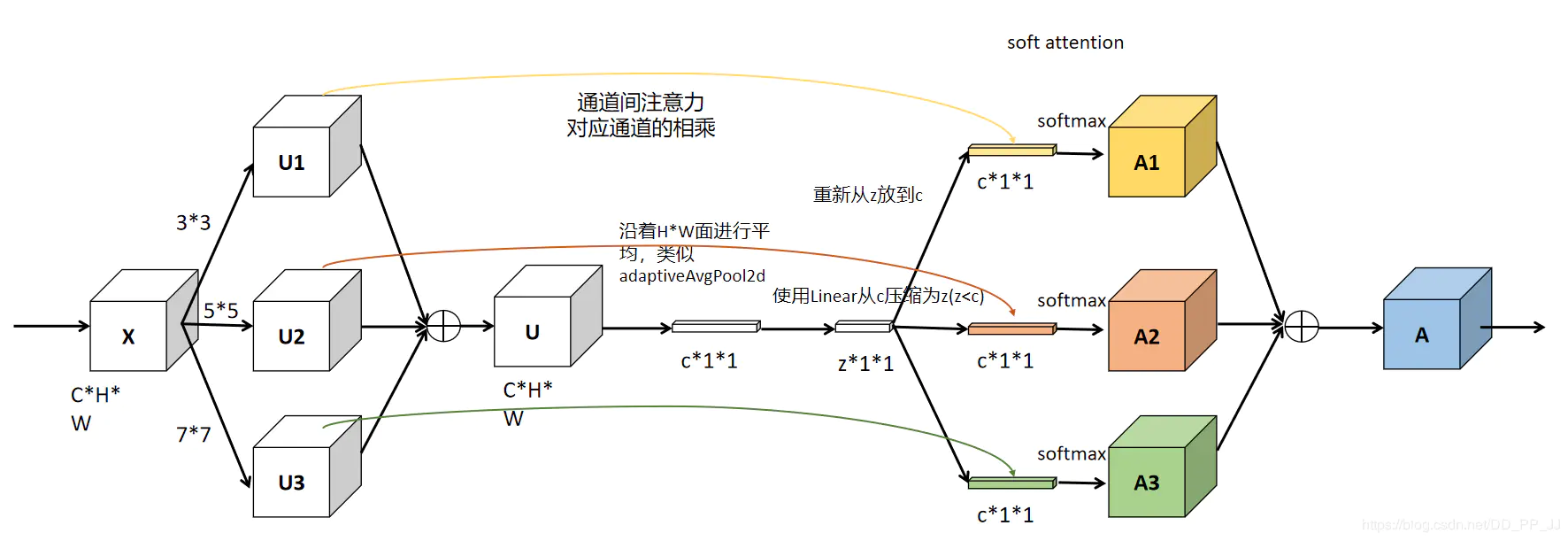
Selective Kernel Convolution
用multiple scale feature汇总的information来channel-wise地指导如何分配侧重使用哪个kernel的表征
一种非线性方法来聚合来自多个内核的信息,以实现神经元的自适应感受野大小
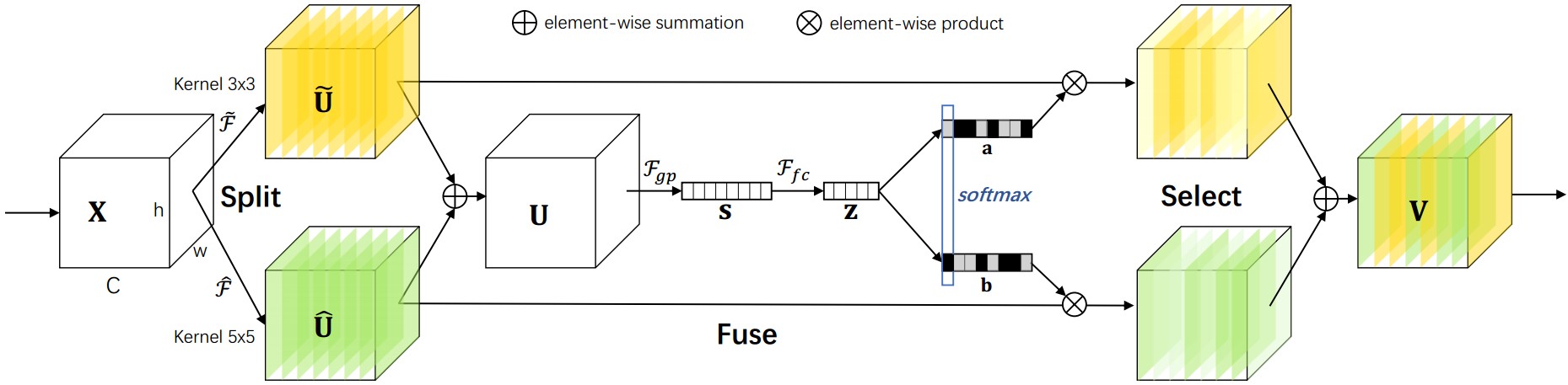
$$ U=\tilde U+\hat U\\ s_c=F_{gp}(U_c)=\frac{1}{H\times W}\sum_{i=1}^H\sum_{j=1}^WU_c(i,j)\\ z=F_{fc}(s)=\delta(B(Ws)) 降维处理\\ $$Split:生成具有不同内核大小的多条路径,这些路径对应于不同感受野(RF,receptive field) 大小的神经元
$X\in R^{H’\times W’\times C’} $
$\tilde F:X\to \tilde U \in R^{H\times W\times C} $ kernel size $3\times3$
$\hat F:X\to \hat U \in R^{H\times W\times C}$ kernel size $5\times5$:使用空洞卷积$3\times3$,空洞系数为2。
Fuse:聚合来自多个路径的信息,以获得选择权重的全局和综合表示。
$s\in R^c$;$\delta$:ReLU;$z\in R^{d\times1}$;$W\in R^{d\times C}$:批量归一化;
$d=max(C/r,L)$ L:d的最小值,本文设置32
Select:根据选择权重聚合不同大小内核的特征图
$$ a_c=\frac{e^{A_cz}}{e^{A_cz}+e^{B_cz}}\\ b_c=\frac{e^{B_cz}}{e^{A_cz}+e^{B_cz}}\\ $$$$ V_c=a_c\cdot\tilde U_c + b_c\cdot \hat U_c\\\ a_c+b_c=1\\ V_c\in R^{H\times W} $$$SK[M,G,r]\to SK[2,32,16]$
M:确定要聚合的不同内核的选择数量
G:控制每条路径的基数的组号
r:reduction ratio
| |
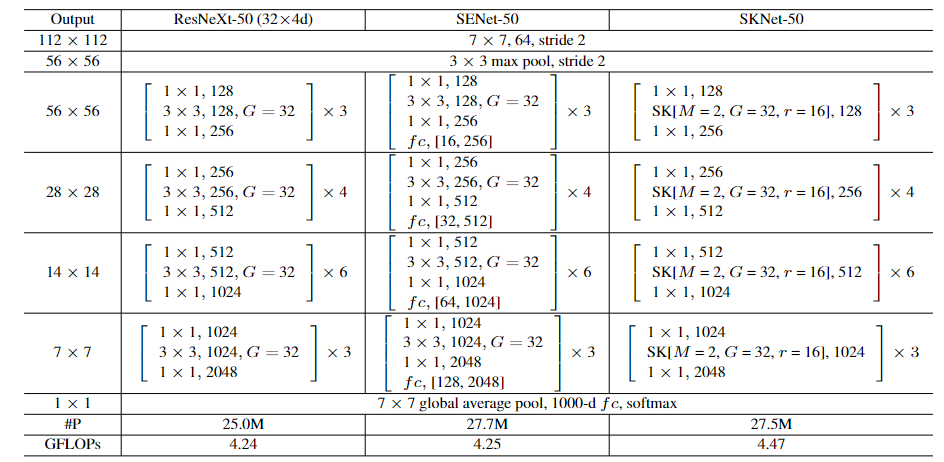
Network Architecture
Ablation Studies
The dilation D and group number
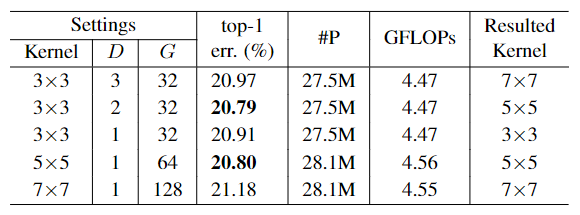 The dilation D and group number
The dilation D and group numberCombination of different kernels
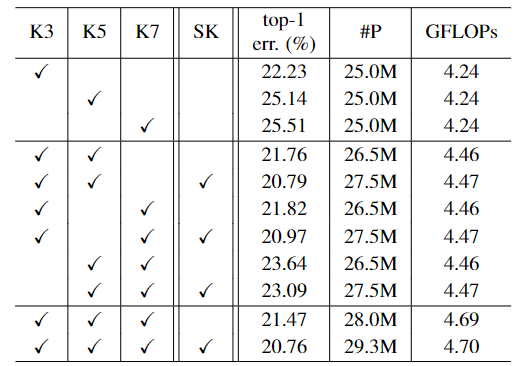 The dilation D and group number
The dilation D and group numberk3 表示 3x3 conv,k5 表示 3x3 conv with 2 dilated,k7 表示 3x3 conv with 3 dilated。
Dilated 是一种在不改变参数数量的情况下扩大感受区域的方法,主要用于分割。
(1) 当路径 M 的数量增加时,识别误差通常会减小。
(2) 无论 M = 2 还是 3,基于 SK 注意力的多路径聚合总是比简单聚合方法(朴素基线模型)实现更低的 top-1 误差。
(3) 使用 SK attention,模型从 M = 2 到 M = 3 的性能增益是微不足道的(top-1 error 从 20.79% 下降到 20.76%)。为了更好地权衡性能和效率,M = 2 是首选