MobileNet
MobileNetV1
文章标题:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
作者:Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
发表时间:(CVPR 2017)
MobileNet V1是谷歌2017年提出的轻量化卷积神经网络,用于在移动端、边缘终端设备上进行实时边缘计算和人工智能推理部署。
使用深度可分离卷积Depthwise Separable Convolution,在保证准确度性能的基础上,将参数量、计算量压缩为标准卷积的八到九分之一。引入网络宽度超参数和输入图像分辨率超参数,进一步控制网络尺寸。
在ImageNet图像分类、Stanford Dog细粒度图像分类、目标检测、人脸属性识别、人脸编码、以图搜地等计算机视觉任务上,结合知识蒸馏进行评估,MobileNet表现出极致的轻量化和速度性能。
Prior Work
压缩已有模型
知识蒸馏
权值量化
剪枝
权重剪枝
通道剪枝
注意力迁移
直接训练小模型
squeezeNet
MobileNet
ShuffleNet
Xception
EfficientNet
NasNet
DARTS
直接加速卷积运算
im2col+GEMM
Winograd
低秩分解
硬件部署
TensorRT
Jetson
Tensorflow-slim
Tensorflow-lite
Openvino
MobileNet Architecture
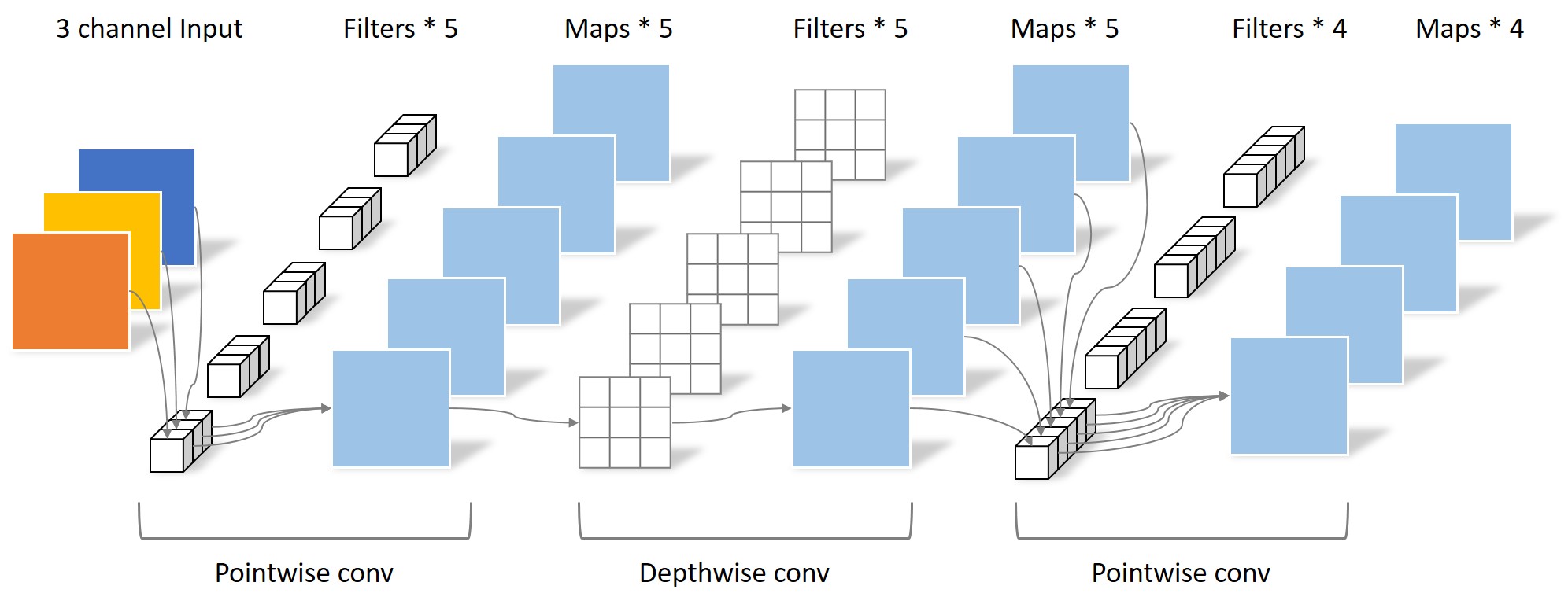
Depthwise Separable Convolution 深度可分离卷积
将标准卷积分为两部分:depthwise convolution,$1\times1$ pointwise convolution
逐层卷积处理每个特征通道上的空间信息,逐点卷积进行通道间的特征融合。
标准卷积:卷积核channel=输入特征矩阵channel;输出特征矩阵channel=卷积核个数
深度可分离卷积:卷积核channel=1;输出特征矩阵channel=卷积核个数=输入特征矩阵channel;
每个输入通道应用一个卷积核进行逐层卷积
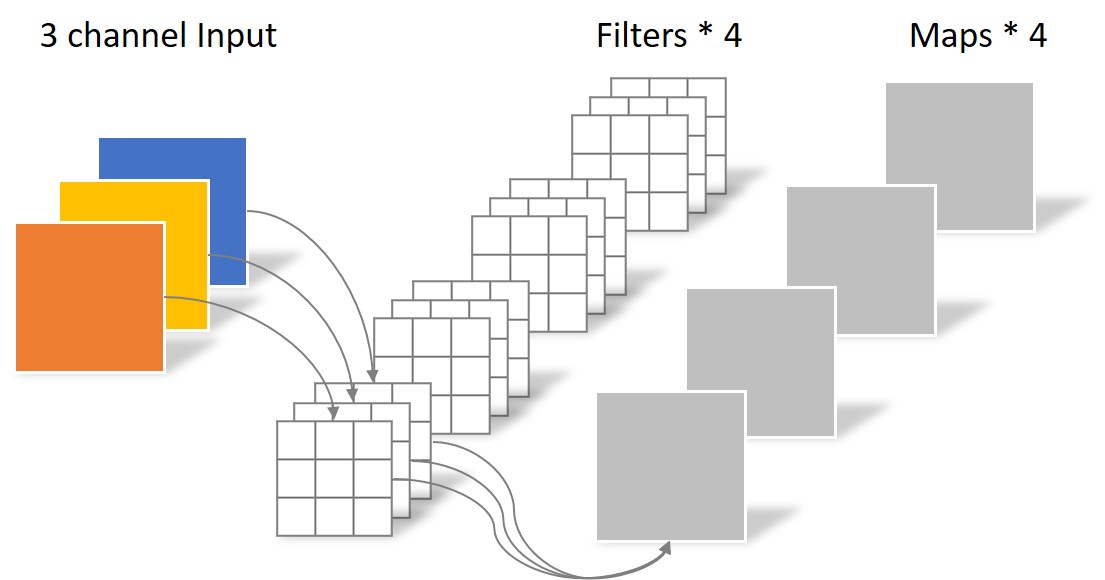
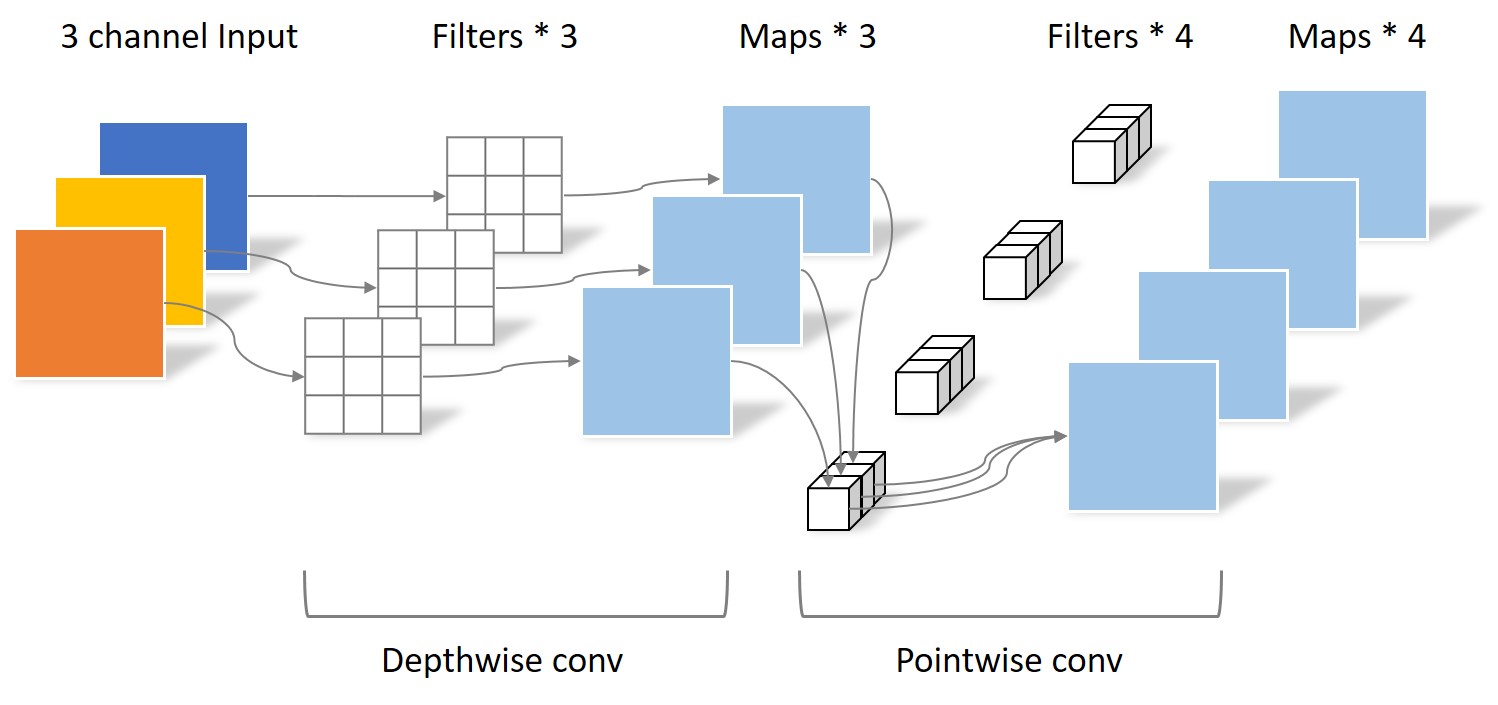
标准卷积 深度可分离卷积 - $D_K$:卷积核尺寸;$M$:卷积核通道数(输入通道数);$N$:卷积核个数(输出通道数);$D_F$:特征图大小
- 标准卷积参数计算:$D_K\times D_K\times M\times N$; 计算量:$D_K\times D_K\times M\times N\times D_F\times D_F$
- 深度可分离卷积参数计算:$D_K\times D_K\times M+M\times N$;
- 深度可分离卷积计算量:$D_K\times D_K\times M\times D_F\times D_F+M\times N \times D_F \times D_F$
Network Structure and Training
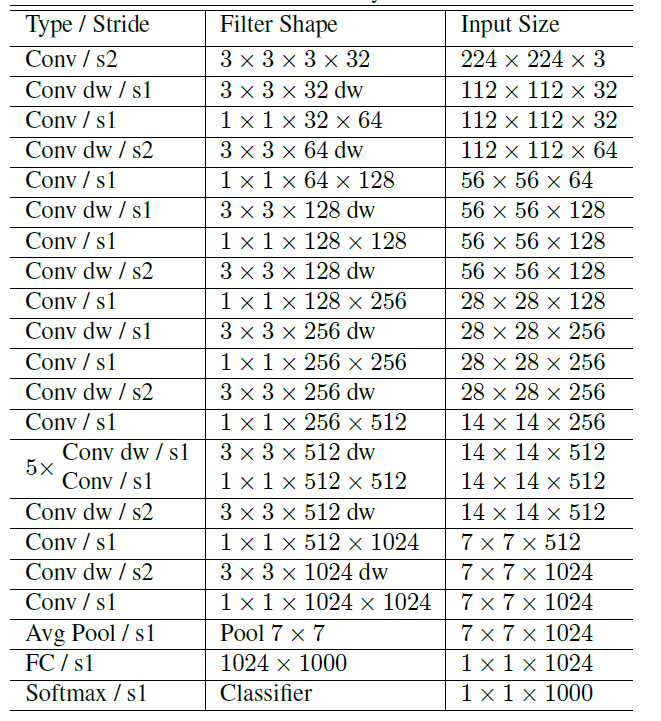
Filter Shape:卷积核尺寸×输入特征矩阵深度×卷积核个数
第一层是标准卷积
放弃pooling层,而使用stride=2的卷积
所有层后面都有BN层和ReLU6;更多的ReLU6,增加了模型的非线性变化,增强了模型的泛化能力。
这个激活函数在float16/int8的嵌入式设备中效果很好,能较好地保持网络的鲁棒性。
深度可分离卷积 MobileNetV1的大部分计算量和参数量都是$1\times1$卷积花费的。
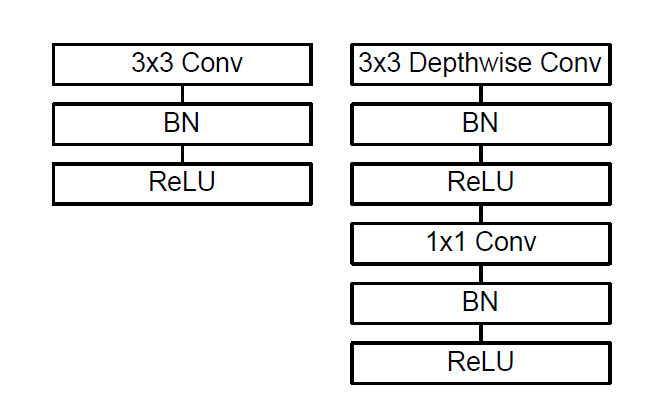

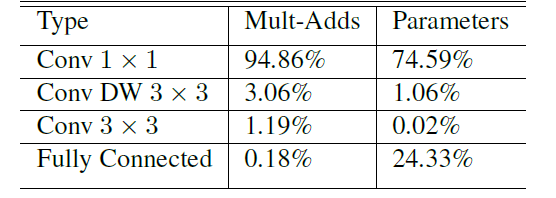
Width and Resolution Multiplier 宽度$\alpha $和分辨率$ \rho$超参数
宽度超参数$\alpha $:控制卷积层卷积核个数
$D_K\times D_K\times \alpha M\times D_F\times D_F+\alpha M\times \alpha N \times D_F \times D_F$
$\alpha \in(0,1]$;一般设置为:$1, 0.75,0.5,0.25$
分辨率超参数$\rho $:控制输入图像大小
$D_K\times D_K\times \alpha M\times \rho D_F\times \rho D_F+\alpha M\times \alpha N \times \rho D_F \times \rho D_F$
$\rho \in(0,1]$;一般设置为:$1, \frac {6}{7},\frac {5}{7},\frac {4}{7}$ 对应分辨率为$224,192,160,128$
计算举例:$D_K=3,M=512,N=512,D_F=14$
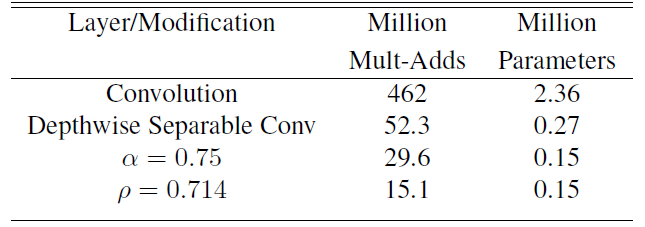 | 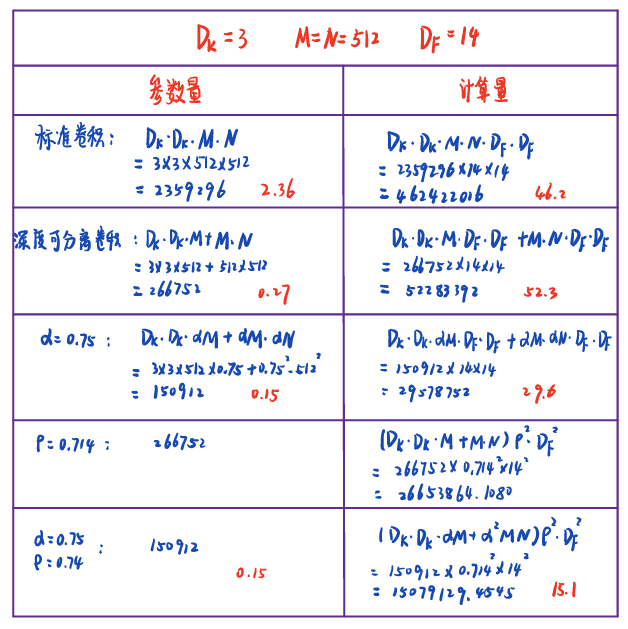 |
| MobileNetV1的计算例子 | |
代码
| |
扩展阅读
Laurent Sifre2013博士论文:Rigid-motion scattering for image classification]
为什么 MobileNet、ShuffleNet 在理论上速度很快,工程上并没有特别大的提升?
轻量级神经网络“巡礼”(二)—— MobileNet,从V1到V3
Why MobileNet and Its Variants (e.g. ShuffleNet) Are Fast
Google’s MobileNets on the iPhone
MobileNetV2
文章标题:MobileNetV2: Inverted Residuals and Linear Bottlenecks
作者:Mark Sandler, Andrew Howard ,Menglong Zhu ,Andrey Zhmoginov, Liang-Chieh Chen
发表时间:(CVPR 2018)
Preliminaries, discussion and intuition
[Depthwise Separable Convolution](###Depthwise Separable Convolution 深度可分离卷积)
linear bottleneck

第一层Pointwise convolution:目的是在数据进入深度卷积之前扩展数据中的通道数
Depthwise convolution的Filter数量取决于之前的Pointwise的通道数。而这个通道数是可以任意指定的,因此解除了3x3卷积核个数的限制
第二次Pointwise则不采用非线性激活,保留线性特征
If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to a linear transformation.
ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.
ReLU激活函数对低维特征信息造成大量损失。
Inverted residuals
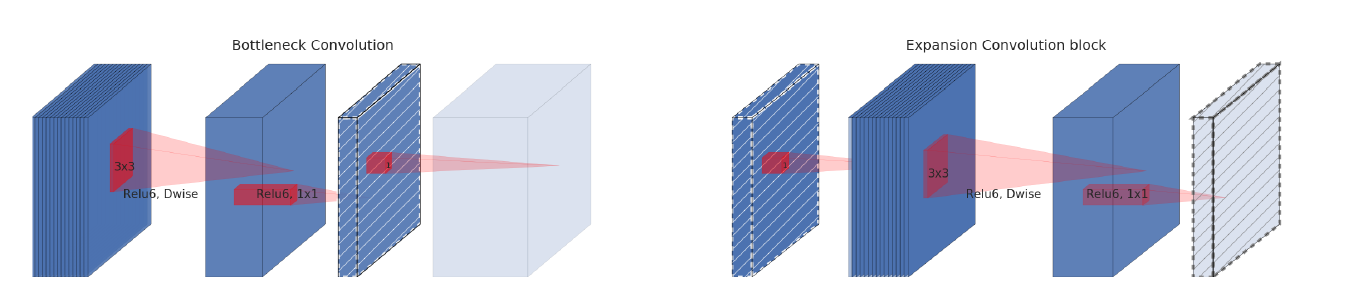
灰色为下一个结构的开始;有格子阴影的层:表示不包含非线性的层
The diagonally hatched texture indicates layers that do not contain non-linearities.

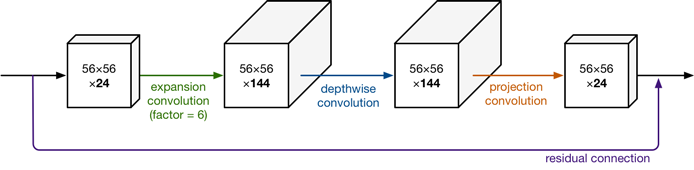
ResNet 先降维 (0.25倍)、卷积、再升维,而 MobileNet V2 则是 先升维 (6倍)、卷积、再降维。
Information flow interpretation
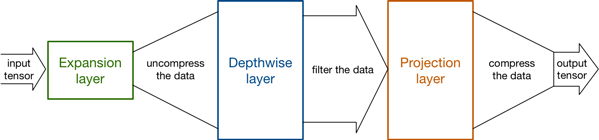
扩展层充当解压缩器(如unzip),首先将数据恢复为完整形式,然后深度层执行网络此阶段重要的任何过滤,最后投影层压缩数据以使其再次变小。
Model Architecture
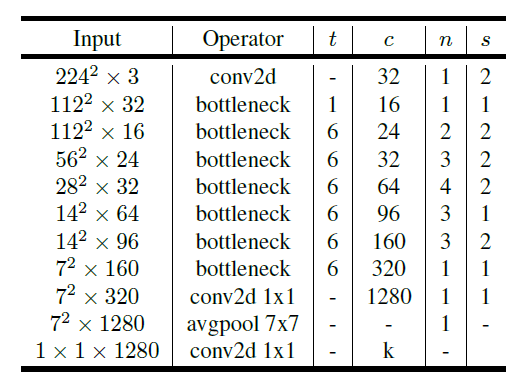
t:expansion rate;c:卷积核个数;n:重复次数;s:首个模块的步长,其他为1
Experiments
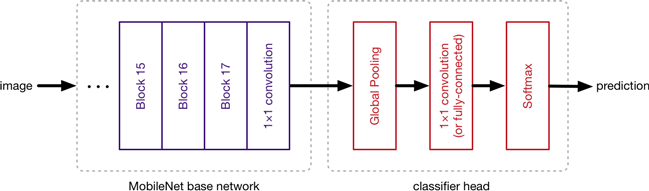
基础网络的输出通常是 7×7 像素的图像。分类器首先使用全局池化层将大小从 7×7 减小到 1×1 像素——基本上采用 49 个不同预测器的集合——然后是分类层和 softmax。
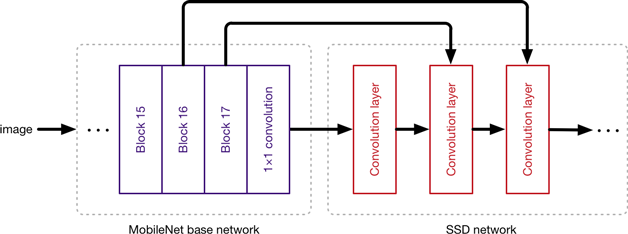
获取最后一个基础网络层的输出,还获取前几个层的输出,并将这些输出送到 SSD 层。MobileNet 层的工作是将输入图像中的像素转换为描述图像内容的特征,并将这些特征传递给其他层。因此,此处使用 MobileNet 作为第二个神经网络的特征提取器。
拓展阅读
Figure 2: MobileNetV2 with inverted residuals
MobileNetV3
文章标题:Searching for MobileNetV3
作者:Andrew Howard,Mark Sandler,Grace Chu,Liang-Chieh Chen,Bo Chen, Mingxing Tan,Weijun Wang,Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam
发表时间:(CVPR 2019)
Efficient Mobile Building Blocks更新Block
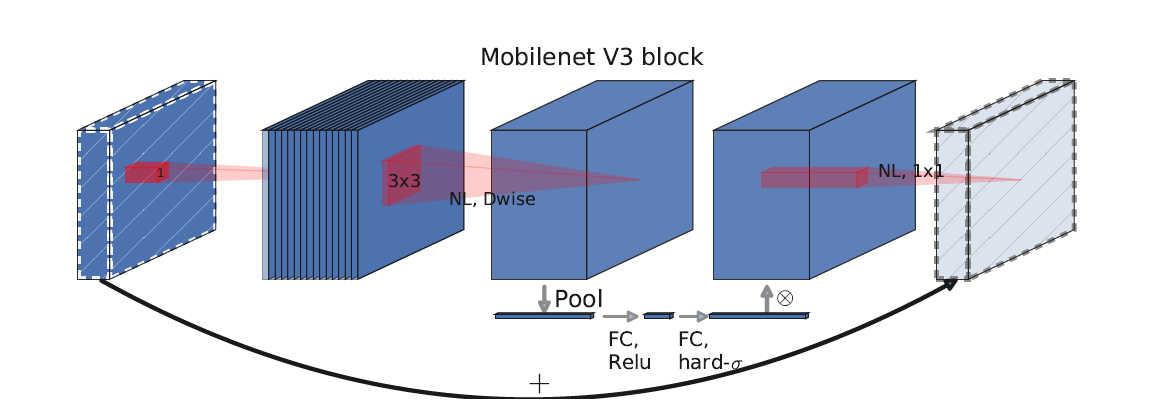
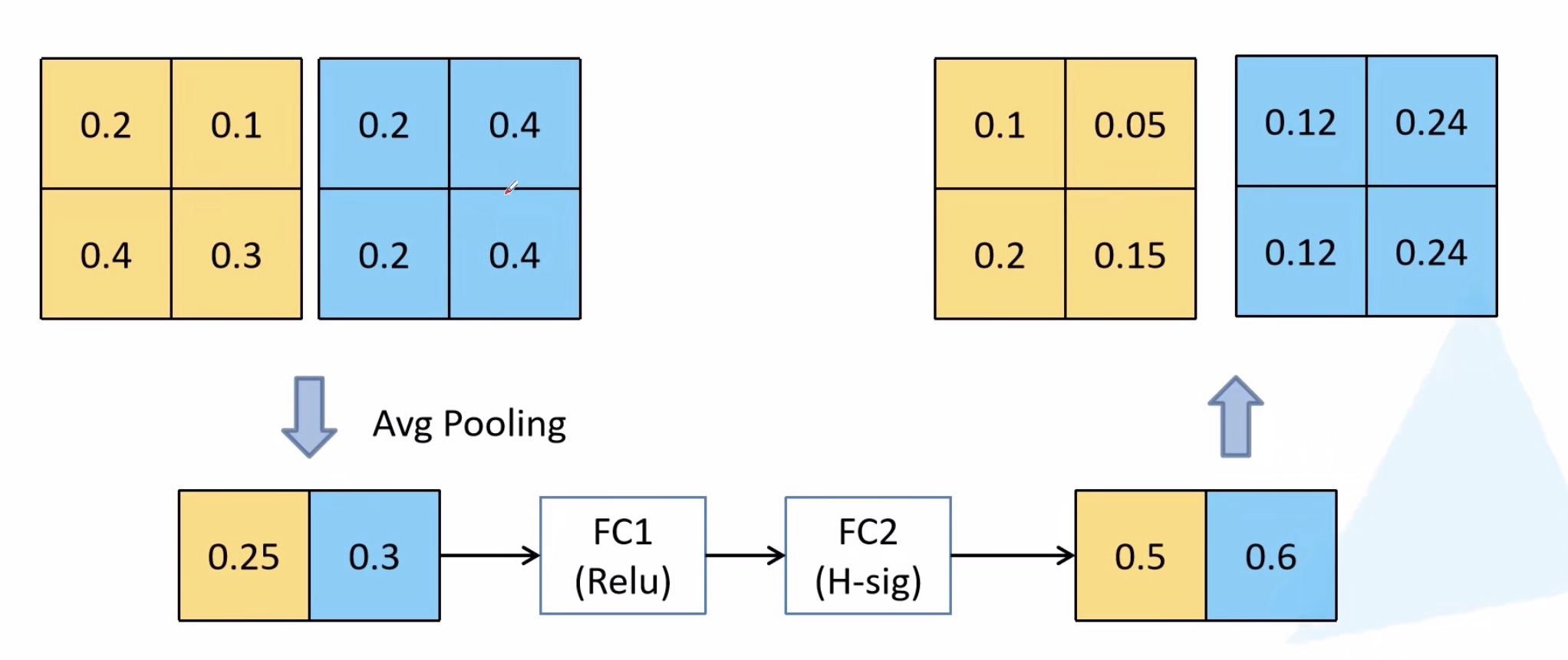
- 加入SE模块(Squeeze-and-Excite):SE模块是一种轻量级的通道注意力模块。depthwise之后,经过池化层,然后第一个fc层,通道数缩小4倍,再经过第二个fc层,通道数变换回去(扩大4倍),然后与depthwise进行按位相乘。
- 更新激活函数
使用NAS搜索参数
利用NAS(神经结构搜索)和NetAdapt来搜索网络的配置和参数。
Redesigning Expensive Layers重新设计耗时层结构
$$ ReLU6(x)=min(max(x,0),6)\\ h\_sigmoid[x]=\frac{ReLU6(x+3)}{6} $$减少第一个卷积层的卷积核个数(32->16):使用ReLU或者swish激活函数,能将通道数缩减到16维,且准确率保持不变。这又能节省2ms的延时。
$swish\ x = x\dot \sigma (x)$ ;$\sigma = \frac{1}{1+e^{-x}}$ 计算、求导复杂,对量化过程不友好。将sigmoid函数替换为piece-wise linear hard analog function.
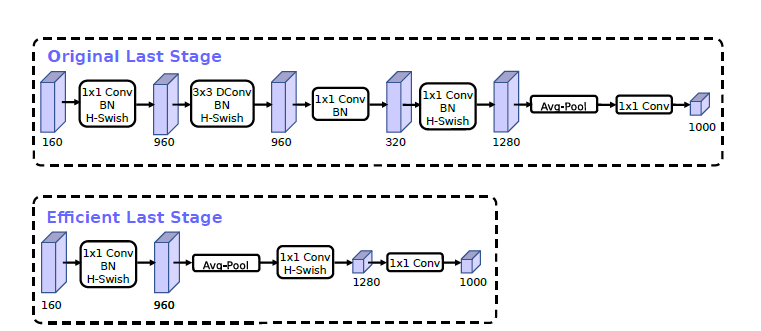
$$ h\_swish[x]=x\frac{ReLU6(x+3)}{6} $$精简Last Stage :Original Last Stage为v2的最后输出几层,v3版本将平均池化层提前了。在使用1×1卷积进行扩张后,就紧接池化层-激活函数,最后使用1×1的卷积进行输出。通过这一改变,能减少7ms的延迟,提高了11%的运算速度,且几乎没有任何精度损失。
MobileNetV3 Architecture
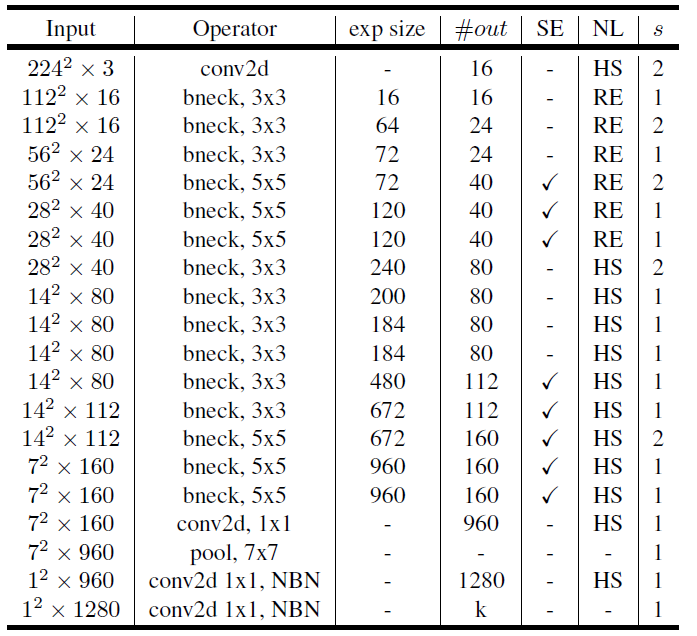 | 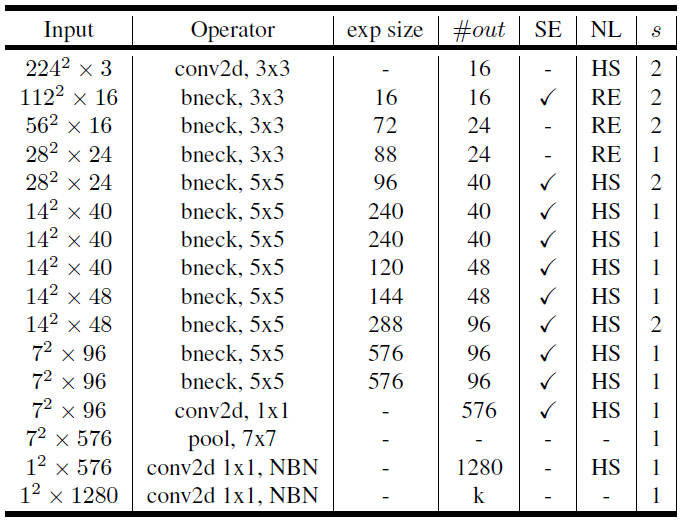 |
| Specification for MobileNetV3-Large | Specification for MobileNetV3-Small |
exo_size:升维;#out 输出通道数; NL:激活函数 ; s:步距 ;NBN:没有批量归一化
MobileNeXt
文章标题:Rethinking Bottleneck Structure for Efficient Mobile Network Design
作者:Zhou Daquan, Qibin Hou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan
发表时间:(ECCV 2020)
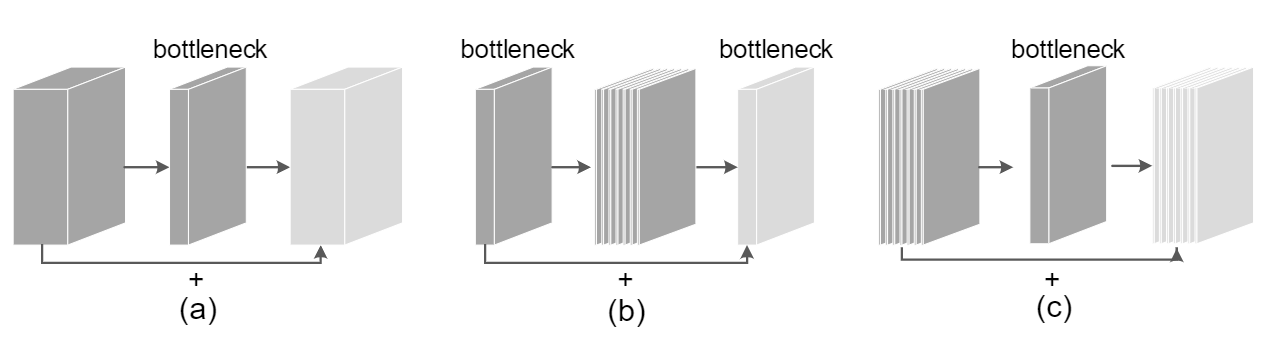
每个块的厚度来表示相应的相对通道数
(a):Classic residual bottleneck blocks 经典残差块
一个 1×1 卷积用于通道缩减,一个 3×3 卷积用于空间特征提取,另一个 1×1 卷积用于通道扩展
(b):Inverted residual blocks 倒残差块
一个 1×1 卷积用于通道扩展,一个 3×3 深度可分离卷积用于空间特征提取,另一个 1×1 卷积用于通道缩减
将低维压缩张量作为输入,并通过逐点卷积将其扩展到更高维。应用深度卷积进行空间上下文编码,另一个逐点卷积以生成低维特征张量作为下一个块的输入。
由于相邻倒置差之间的表示是低维的。bottleneck之间的shortcut可能会阻止来自顶层的梯度在模型训练期间成功传播到底层。
深度可分离卷积用于空间特征提取后进行通道压缩可能无法保留足够的有用信息,造成信息丢失
ShuffleNetV2 在反向残差块之前插入一个通道拆分模块,并在其后添加另一个通道混洗模块
HBONet 中,下采样操作被引入到倒残差块中,用于对更丰富的空间信息进行建模。
MobileNetV3 提出在每个阶段搜索最优激活函数和倒残差块的扩展率
MixNet 提出在倒残差块中搜索深度可分离卷积的最佳内核大小
(c):Sandglass Block 沙漏块
在更高维度上执行恒等映射和空间变换,从而有效地减轻信息丢失和梯度混淆
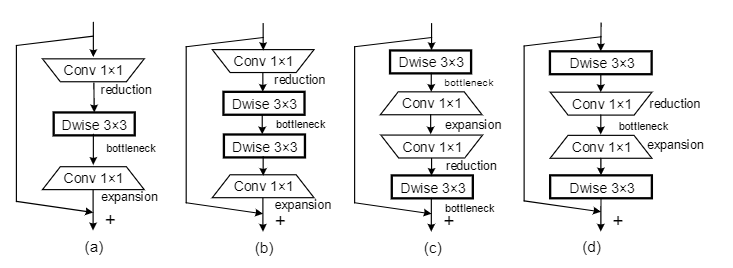
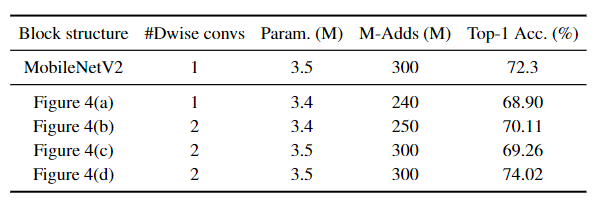
(a):直接修改经典的残差块构建的,将标准的 3×3 卷积替换为 3×3 深度卷积。
与(d)相比,性能下降了约 5%:可能由于深度卷积是在具有低维特征空间的bottleneck中进行的,因此无法捕获足够的空间信息。
(b):在a基础上添加加了另一个 3×3 深度卷积
与(a)相比 精度提高了 1% 以上:表明编码更多的空间信息确实有帮助
与(d)相比
(c):基于原始的倒残差块,将深度卷积从高维特征空间移动到特征通道较少的bottleneck位置
与(b)相比更差:表明在高维表示之间建立shortcut更有利于网络性能
(d):沙漏块
设计原则
为了在传输到顶层时保留来自底层的更多信息并促进跨层的梯度传播,应该在高维表示之间建立shortcut
具有小内核大小(例如 3 × 3)的深度卷积是轻量级的,可以适当地将几个深度卷积应用于更高维的特征,以便可以编码更丰富的空间信息。
将bottleneck保持在剩余路径的中间,以节省参数和计算成本。
高维表示之间建立shortcut。
两个深度卷积都是在高维空间中进行的,可以提取更丰富的特征表示。
使用线性瓶颈可以帮助防止特征值被归零,从而减少信息丢失:第一个逐点卷积之后不添加任何激活层。
仅在第一个深度卷积层和最后一个逐点卷积层之后添加激活层:最后一个卷积之后添加一个激活层会对分类性能产生负面影响(经验)。

注意,$M\neq N$时不添加shortcut
MobileNeXt Architecture
| 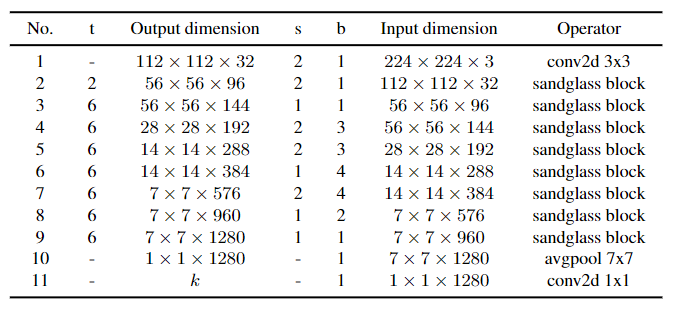 |
| MobileNetV2 | MobileNeXt |
b:重复次数。
t:通道扩展比。
k:类别
为了证明模型的好处来自于新颖架构,而不是利用更多的深度卷积或更大的感受野
$$ G_{1:\alpha M}= φ(F)_{1:\alpha M} + F_{1:\alpha M}, \ G_{\alpha M:M} = φ(F)_{\alpha M:M} $$与 MobileNetV2 的改进版本进行比较,在中间插入了一个深度卷积块。MobileNetV2 的性能提高到了 73%,这仍然比MobileNeXt的 (74%) 差得多。
首先,在减少乘数之后,可以减少每个构建块中的element-wise additions的数量。逐元素加法非常耗时。可以选择较低的恒等张量乘数以产生更好的延迟,而性能几乎没有下降。
其次,可以减少内存访问次数。减少恒等张量的通道维度可以有效地鼓励处理器将其存储在缓存或处理器附近的其他更快的内存中,从而改善延迟。
ReXNet
文章标题:Rethinking Channel Dimensions for Efficient Model Design
作者:Dongyoon Han, Sangdoo Yun, Byeongho Heo, YoungJoon Yoo
发表时间:(CVPR 2021)
v1版本叫做ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network
ReXNet,ReXNet 是 NAVER 集团 ClovaAI 研发中心基于一种网络架构设计新范式而构建的网络。针对现有网络中存在的 Representational Bottleneck 问题,作者提出了一组新的设计原则。作者认为传统的网络架构设计范式会产生表达瓶颈,进而影响模型的性能。为研究此问题,作者研究了上万个随机网络生成特征的 matric rank,同时进一步研究了网络层中通道配置方案。基于此,作者提出了一组简单而有效的设计原则,以消除表达瓶颈问题。
Designing an Expansion Layer
在第一个1×1卷积时,需要用6或更小的扩展比来设计一个inverted bottleneck;
在轻量级模型中,每个带有深度卷积的inverted bottleneck都需要更高的通道维度比;
复杂的非线性,如ELU和SiLU,需要放在1×1卷积或3×3卷积之后(不是深度卷积)
channel dimension ratio:$d_{in}/d_{out}\in[0.1,1]$
rank ratio:$rank(f(WX))/d_{out}$
$f(WX)$:输出特征;$W\in R^{d_{out}\times d_{in}};X\in R^{d_{in}\times N}$;$N$为batchsize;$f$为归一化后的非线性函数
Average Rank Ratio:每个模型取平均
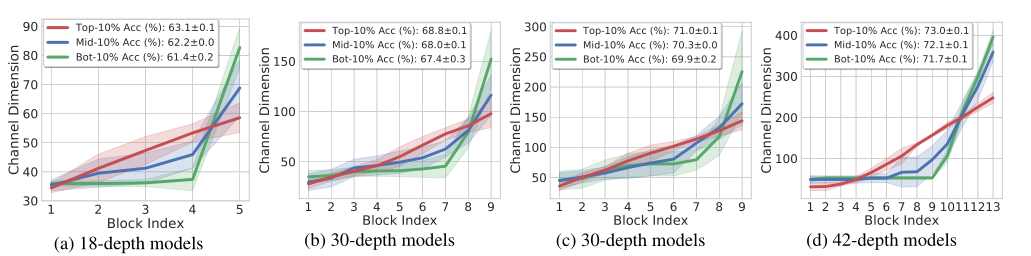
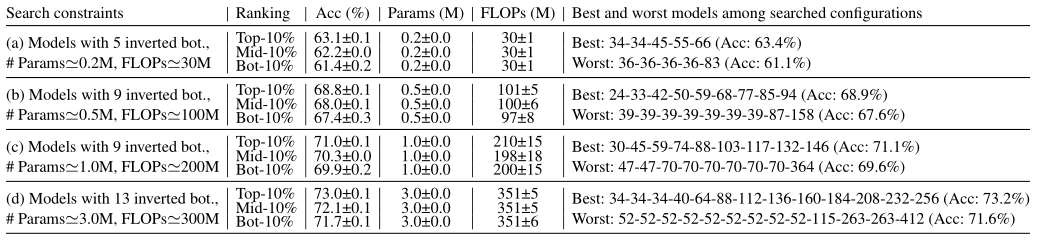
从200个搜索过的模型中收集前10%、中间10%(即前50%和60%之间的模型)和后10%的模型 Red: top-10%; blue: middle-10%; green: bottom-10% accuracy models
红色的Block Index的线性参数化享有更高的精度,同时保持类似的计算成本。最佳模型的通道配置为线性增加。
绿色的模型大幅减少了输入侧的通道,因此,大部分的权重参数被放置在输出侧,导致精度的损失。
蓝色代表处于中间10%精度的模型,与传统通道配置相似。传统配置是通过限制早期层的通道,并在靠近输出的地方提供更多的通道来达到flop-efficienty的目的。
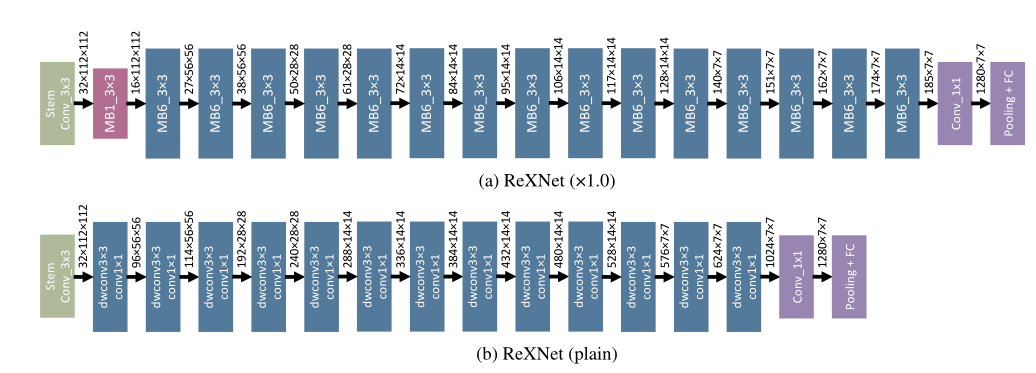
Network upgrade
| 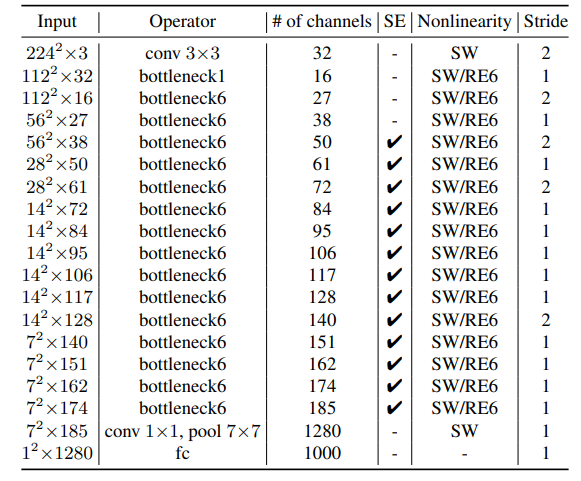 |
| MobileNetv2 | ReXNet_1.0x |
| 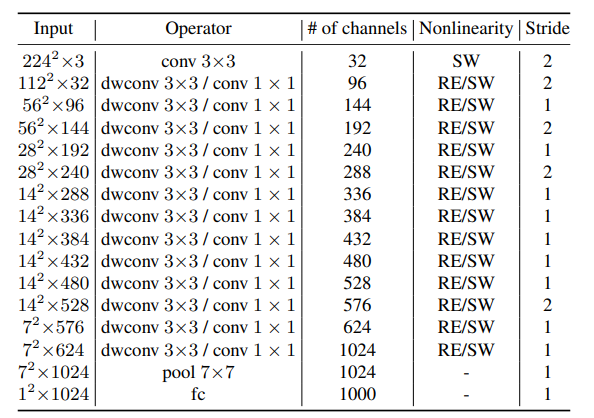 |
| MobileNetv1 | ReXNet_plain |
通道数线性增加
在每个倒置瓶颈的第一个1×1卷积后替换ReLU6
观察到维数比较小的层需要更多的处理
第二个深度卷积的通道维数比为1,所以在此不替换ReLU6。
MB1和MB6指的是MobileNetV2的inverted bottleneck,扩展率分别为1和6。
MixNet
文章标题:MixConv: Mixed Depthwise Convolutional Kernels
作者:Mingxing Tan, Quoc V. Le
发表时间:(BMVC 2019)
MixConv,MixNet 是谷歌出的一篇关于轻量级网络的文章,主要工作就在于探索不同大小的卷积核的组合。作者发现目前网络有以下两个问题:小的卷积核感受野小,参数少,但是准确率不高;大的卷积核感受野大,准确率相对略高,但是参数也相对增加了很多.为了解决上面两个问题,文中提出一种新的混合深度分离卷积(MDConv)(mixed depthwise convolution),将不同的核大小混合在一个卷积运算中,并且基于 AutoML 的搜索空间,提出了一系列的网络叫做 MixNets,在 ImageNet 上取得了较好的效果。