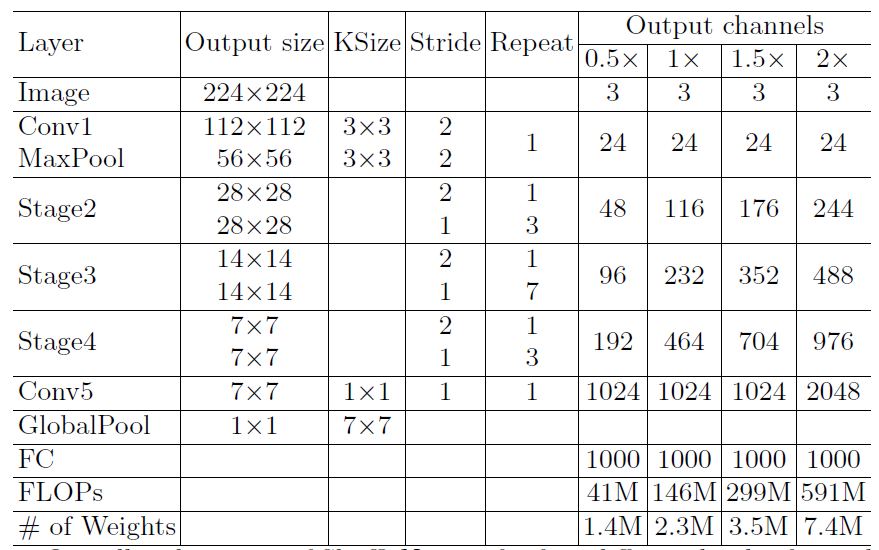
ShuffleNet
ShuffleNetV1
文章标题:Shufflenet: An extremely efficient convolutional neural network for mobile devices 作者:Xiangyu Zhang,Xinyu Zhou,Mengxiao Lin ,Jian Sun ,Megvii Inc (Face++) 发表时间:(CVPR 2018)
ShuffleNet V1,ShuffleNet主要包含两个新型的结构:分组逐点卷积(pointwise group conv)和通道重排(channel shuffle)。作者们通过使用分组的1x1卷积在MobileNet的基础上进一步减少参数, 同时为了保障分组后的Channelwise的信息交换, 作者们引入了ChannelShuffle这一操作, 将channel重新排列, 使得下次分组卷积的每一组特征图都含有来自上次卷积的各组特征图. 再引入残差连接之外, ShuffleNetV1也通过连接下采样的输入在降低分辨率的同时扩张通道数, 同时也没有引入新的参数。
Related work
Group Convolution
每个卷积核不再处理所有输入通道,而只是处理一部分通道。
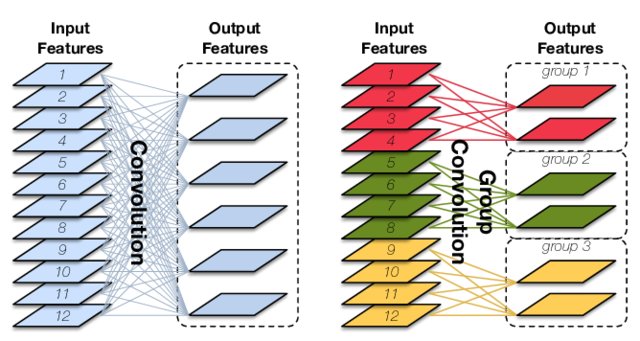
Approach
Channel Shuffle for Group Convolutions
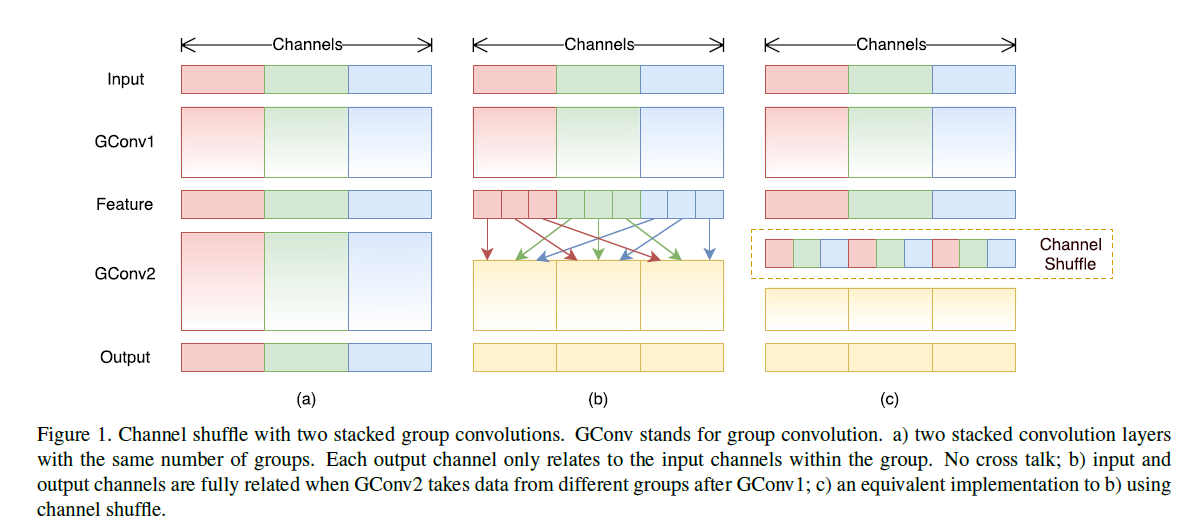
(a) GConv虽然能够减少参数与计算量,但 GConv中不同组之间信息没有交流。
(b)(c) 通道重排
| |
ShuffleNet unit
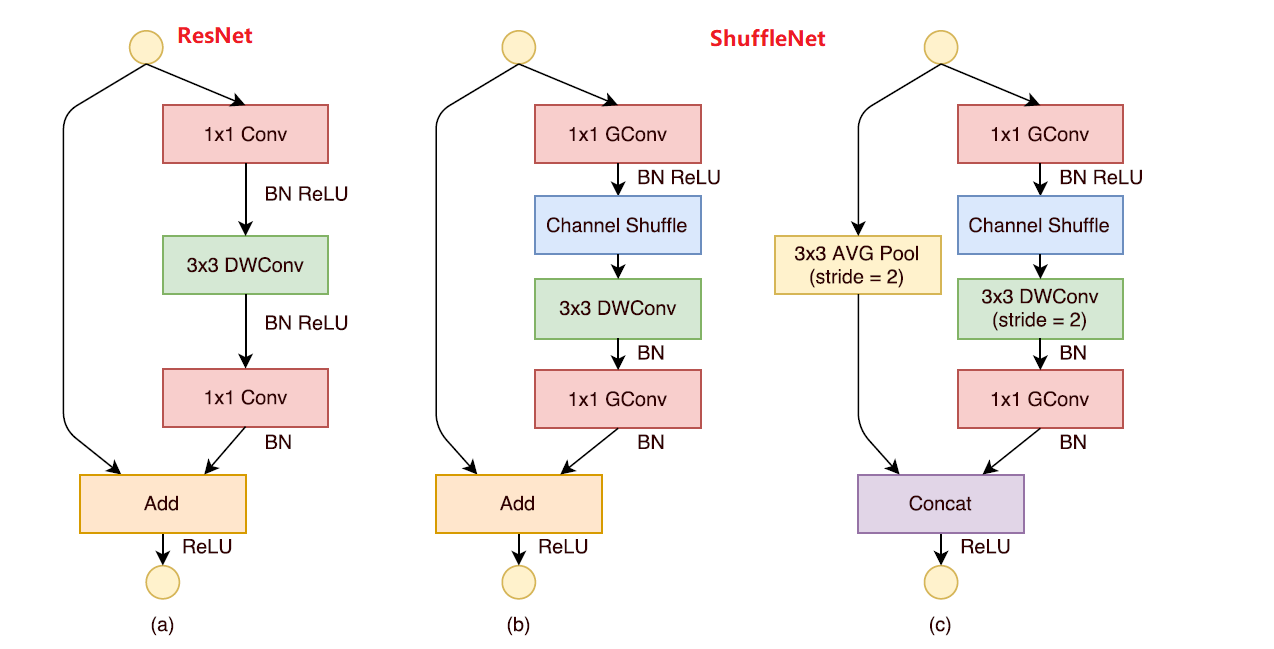
(a) ResNet网络中$1\times1$卷积理论计算量占据93.4%
$1\times1$卷积换成GConv,第一个进行通道重排
(b) stride =1
(c) stride =2;进行Concat拼接
Feature Map的尺寸为$w\times h \times c$;bottleneck的通道数为$m$。
ResNet:$F_{ResNet}=hw(1\times1\times c\times m)+hw(3\times3\times m\times m)+hw(1\times1\times m\times c)=hw(2cm+9m^2)$
ResNeXt:$F_{ResNeXt}=hw(1\times1\times c\times m)+hw(3\times3\times m\times m)/g+hw(1\times1\times m\times c)=hw(2cm+9m^2/g)$
ShuffleNet:$F_{ShuffleNet}=hw(1\times1\times c\times m)/g+hw(3\times3\times m)+hw(1\times1\times m\times c)/g=hw(2cm/g+9m)$
结构的第一个block的第一个point conv用的普通卷积
shuffle block:如下图所示,整个block首先通过如下图所示的group操作减少网络参数,并对group操作后输出的特征图作shuffle操作,用以消除由于group造成的特征屏蔽现象,紧接着再跟一个group操作。

拓展阅读
知乎:如何看待 Face++ 旷视科技出品的轻量高效网络 ShuffleNet ?
ShuffleNetV2
文章标题:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design 作者:Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, Jian Sun 发表时间:(ECCV 2018)
高效网络设计的四个指导原则
G1:当输入和输出的通道数相同时,conv计算所需的MAC最小(保持FLOPs不变);
$$ \begin{equation} \begin{split} MAC &= h\times w\times c_1+h \times w \times c_2+1\times 1\times c_1 \times c_2\\ &=hw(c_1+c_2)+c_1c_2\\ &=B(\frac{1}{c_1}+\frac{1}{c_2})+\frac{B}{hw}\\ &\geq 2\sqrt{hwB}+\frac{B}{hw} (当且仅当c_1=c_时,等号成立) \end{split} \end{equation} $$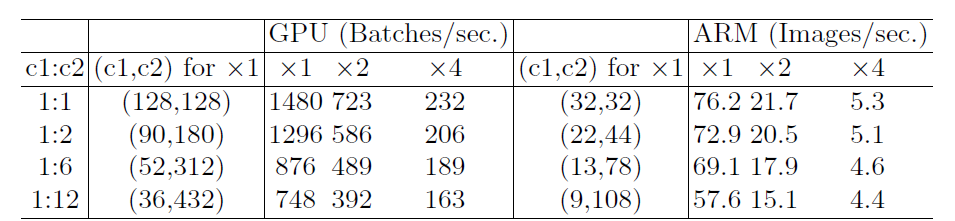 Validation experiment for Guideline 1,Input image size is 56 × 56.
Validation experiment for Guideline 1,Input image size is 56 × 56.FLOPS计算量: $B=1\times 1\times c_1\times h \times w\times c_2=hwc_1c_2$; $c_1$:输入通道数;$c_2$:输出通道数
$$ \sqrt{\frac{{c_1}^2+{c_2}^2}{2}}\geq \frac{c_1+c_2}{2}\geq \sqrt{c_1c_2}\geq \frac{2}{\frac{1}{c_1}+\frac{1}{c_2}} $$
G2:大量的分组卷积会增加MAC开销(保持FLOPs不变);
$$ \begin{equation} \begin{split} MAC &=hw(c_1+c_2)+c_1c_2/g\\ &=hwc_1+\frac{Bg}{c_1}+\frac{B}{hw}\\ \end{split} \end{equation} $$$$ B = \frac{hwc_1c_2}{g} $$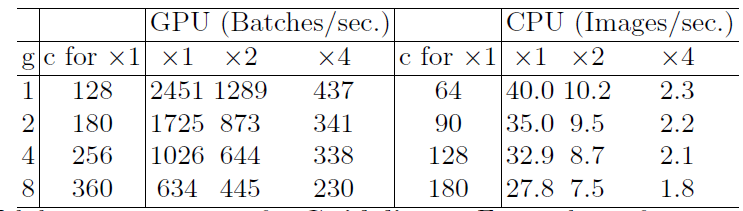 Validation experiment for Guideline 2,Input image size is 56 × 56.
Validation experiment for Guideline 2,Input image size is 56 × 56.固定输入尺寸和计算量:$g$越大,MAC越大
ShuffleNet V1 严重依赖分组卷积,这违反了 G2
G3:网络结构的碎片化会减少其可并行优化的程度;
GoogleNet系列和NASNet中很多分支进行不同的卷积/pool计算非常碎片,对硬件运行很不友好;
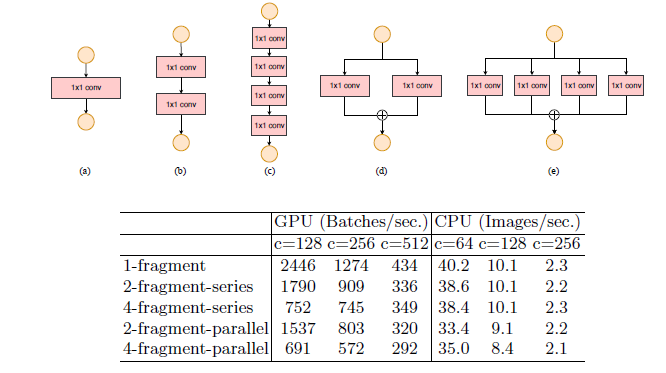 Validation experiment for Guideline 3,Input image size is 56 × 56
Validation experiment for Guideline 3,Input image size is 56 × 562-fragment-series表示一个block中有2个卷积层串行,也就是简单的叠加; 4-fragment-parallel表示一个block中有4个卷积层并行,类似Inception的整体设计。 可以看出在相同FLOPs的情况下,单卷积层(1-fragment)的速度最快。
在 GPU 上碎片结构会大大降低运算速度,而在 CPU 上则不是那么明显
G4:Element-wise操作不可忽视;
对延时影响很大,包括Add/Relu/short-cut/depthwise convolution等,主要是因为这些操作计算与内存访问的占比太小;
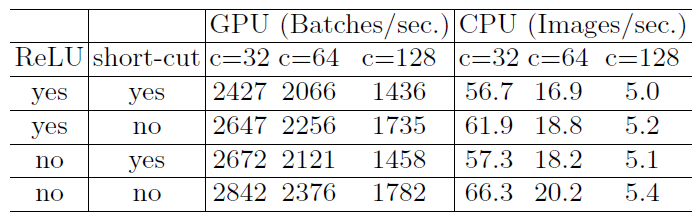 Validation experiment for Guideline 4
Validation experiment for Guideline 4采用的是Resnet50的瓶颈结构(bottleneck),分别去掉其中的 ReLU 和跳跃连接,然后测试它们各自的运行速度。可以看到无论是去掉其中哪一个操作,运行速度都会加快。
ShuffleNet V2
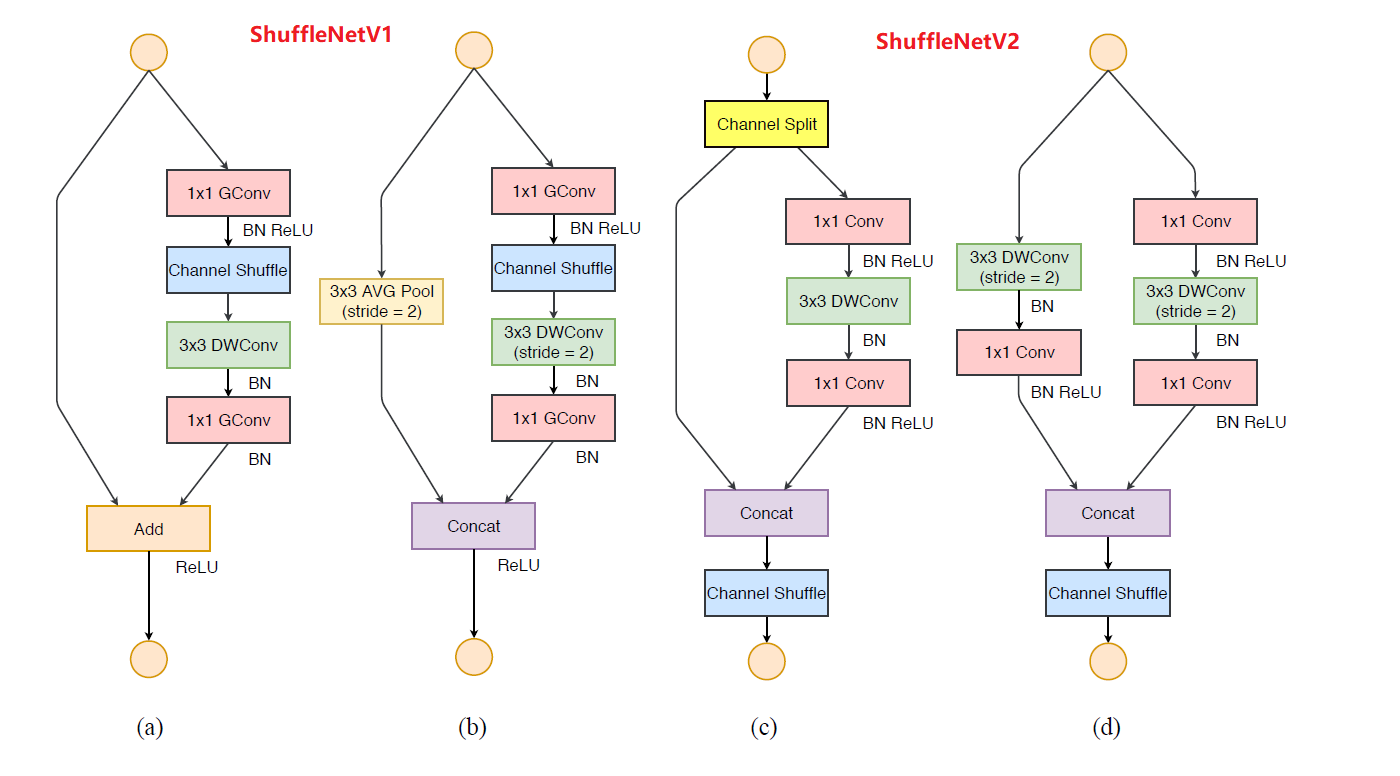
去掉了分组卷积(G2)的操作,去掉了Add(G4)操作,换成两个分支拼接(Concat)起来,从而通道数量保持不变 (G1),然后进行与ShuffleNetV1相同的Channel Shuffle操作来保证两个分支间能进行信息交流。
拓展阅读
知乎:轻量级神经网络“巡礼”(一)—— ShuffleNetV2
知乎:如何看待 Face++ 旷视科技出品的轻量高效网络 ShuffleNet ?