ALBEF
ALBEF
文章标题:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
作者:Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, Steven Hoi
发表时间:(NIPS 2021)
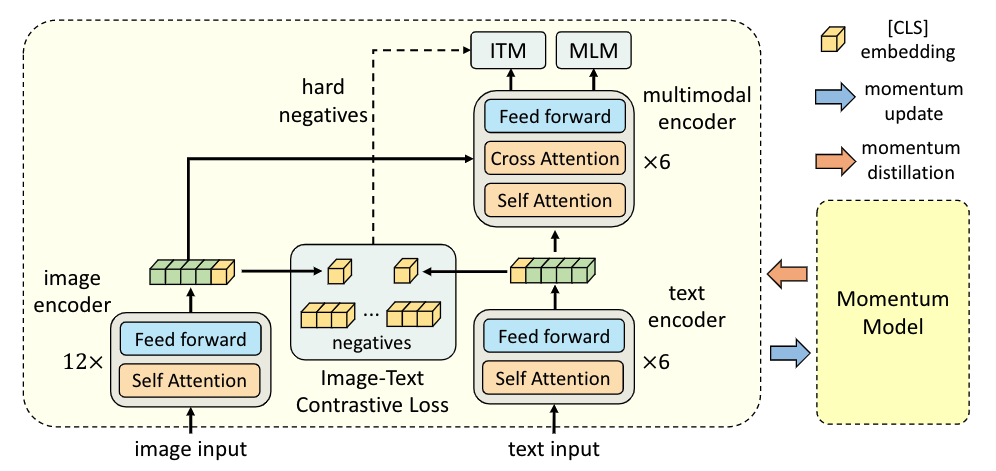
ALBEF 包含一个图像编码器 (ViT-B/16)、一个文本编码器(前 6 层 BERT)和一个多模态编码器(后 6 层 BERT,带有额外的交叉注意层)。
image input打成patch,通过patch embedding layer,在通过12层 Vision Transformer
$224\times224-$-> $(196+1)\times 768=197\times768$
BERT前六层去做文本编码,剩下的六层transformer encoder直接当成multi-model fusion的过程
Loss
Image-Text Contrastive Learning (ITC)。类似于CLIP,增大同(正)样本对的similarity,减小负样本对的similarity。
CLS Token当做全局特征,图像和文本各一个$768\times1$的一个向量;通过downsample和normalization变成$256\times 1$ (MoCo实现)
Masked Language Modeling (MLM,generative)。类似于BERT,遮盖住一些单词,然后预测出来。
Image-Text Matching (ITM,contrastive)。二分类任务,判断图-文对是否匹配。
动量蒸馏 momentum distillation
拓展阅读
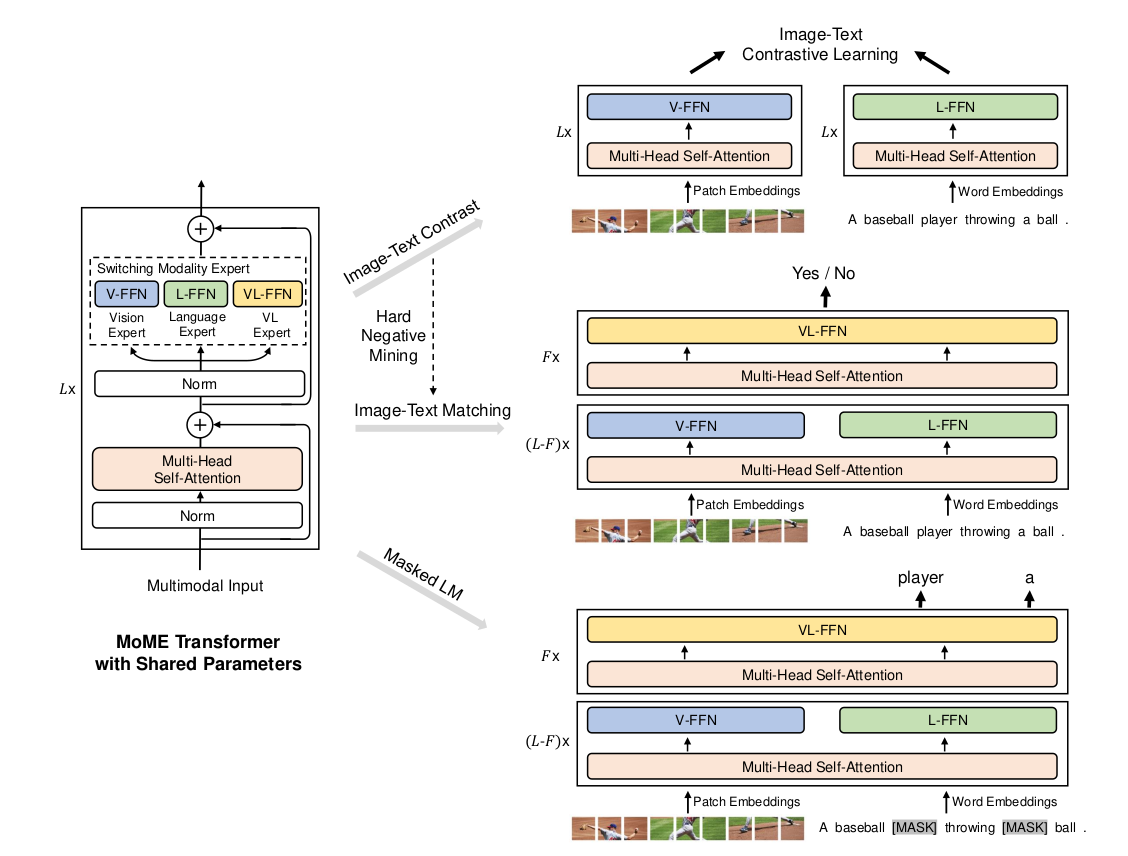
VLMo
文章标题:VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
作者:Hangbo Bao, Wenhui Wang, Li Dong, Qiang Liu, Owais Khan Mohammed, Kriti Aggarwal, Subhojit Som, Furu Wei
发表时间:(NIPS 2022)