CLIP
CLIP
文章标题:Learning Transferable Visual Models From Natural Language Supervision
作者:Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
发表时间:(ICML 2021)
offical code 代码只是可以用来做推理并没有开源
图片和文本之间的对比学习
CLIP:Con-trastive Language-Image Pre-training
利用自然语言的这种监督信号去学习一个迁移性能好的视觉网络
优点
不需要再去标注数据
图片-文本对这种多模态特征适合zero-shot迁移学习
单模态的对比学习:MoCo;单模态的掩码学习:MAE;只能学到视觉特征,很难zero-shot迁移学习
局限性:
- ResNet50打平手但是离SOTA还很远,扩大模型和数据集能提高预计资源$\times 1000$,代价太大
- 在有些数据集上的zero-shot效果也不好:细分类数据集,抽象概念
- 推理时,目标数据集out-of-distribution,CLIP泛化照样差
- 不能做成生成式模型(GPT)(对比学习的目标函数和生成式的目标函数结合)
- 数据利用不高效(数据大)减少数据用量:数据增强;自监督;伪标签
- 下游任务数据集测试调参带入偏见:创建一个用来测试各种各样的zero-shot的迁移能力的数据集
- 网上爬的未清洗,可能带有社会偏见
- 提供一些训练样本反而效果变差(Few Shot效果不好)
不使用ImageNet的训练集的情况下直接Zero-shot 做推理就获得和之前监督训练好ResNet50同样的效果
使用超大规模 web Image Text 数据集
Related work
Learning visual n-grams from web data:和CLIP相似,没有transformer和大规模数据集,效果很差
VirTex (CVPR 2021) 自回归的预测方式去做模型的预训练
ICMLM (ECCV 2020) 用这种完形填空的方式去做预训练
ConVIRT (MLHC 2022) 和CLIP类似,只在医疗图像上做了实验
Methods
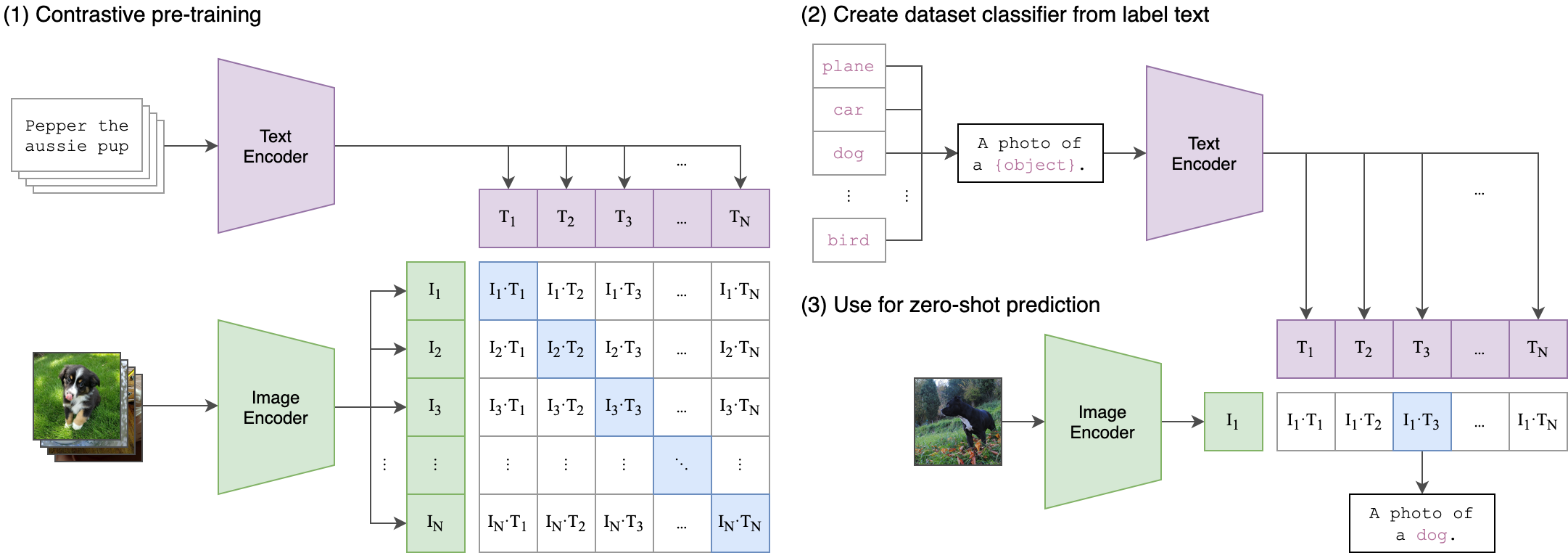
(1) 模型的输入是一个图片和文字的配对;图片通过了一个图片编码器 Image Encoder 得到了一些特征 $I_1,I_2,…,I_N$;句子通过一个文本编码器 Text Encoder 得到一些文本的特征 $T_1,T_2,…,T_N$。
正样本:对角线上文本和图片配对的元素 $N$
负样本:其他 $N^2-N$
(2) prompt template 提示模板
把Image Net 里的1,000个类变成1000个句子;句子通过预训练好的文本编码器得到1,000个文本的特征
如何变成句子?用物体类别去替代图里的 object 变成 A photo of a (object).
为什么要prompt template ?只用一个单词去做 prompt 经常出现歧异性(不同语境下意思不同)。由于模型预训练时,图片和句子成对使用,推理时直接用类别单词得到的文本特征(distribution gap),效果就会稍有下降。
prompt engineering :为每个任务定制提示文本可以显着提高零样本性能(缩小解空间)
prompt ensemble:80个模板结果综合
(3) Zero-shot
推理时,输入一张图片通过预训练好的图片编码器得到图片的特征 $I_1$,$I_1 $ 和所有的文本特征做cosine similarity (相似性比较),得到文本特征最相似的句子$I_1T_3$。
摆脱了categorical label 的限制
不论是训练还是推理,都不需要提前定好一个标签列表。
任意一张照片可以通过给模型输入不同的文本句子从而知道这张图片里到底有没有感兴趣的物体

两个输入:一个是图片的输入;一个是文本的输入。通过编码器输出图像特征和文本特征
线性投射层 W 学习一下如何从单模态转变为多模态,再做一次 L2 归一化
投射层 线性还是非线性 没太大关系(数据集大,多模态)
数据增强只使用随机裁剪
计算consine similarity
交叉熵目标函数 一个是 Image loss;一个是 text loss; 把两个 loss 加起来取平均
推荐阅读
style CLIP (ICCV 2021): CLIP + style GAN 想通过文字上的改变从而去引导图像生成
CLIP draw 不需要任何训练,CLIPDraw在矢量笔画上操作,而不是在像素图像上操作,使绘画偏向于更简单的人类可识别的形状。
视频检索:CLIP模型把检索对象(一句话表示)变成文本特征,把视频里的每一帧都变成视觉上的特征,然后一帧一帧的去跟文本特征做对比然后挑出相似性最高的那一帧展现出来
How to Train Really Large Models on Many GPUs?
LSeg
文章标题:Language-driven Semantic Segmentation
作者:Boyi Li, Kilian Q. Weinberger, Serge Belongie, Vladlen Koltun, René Ranftl
发表时间:(ICLR 2022)
CLIP做图像分割:像素级别的分类
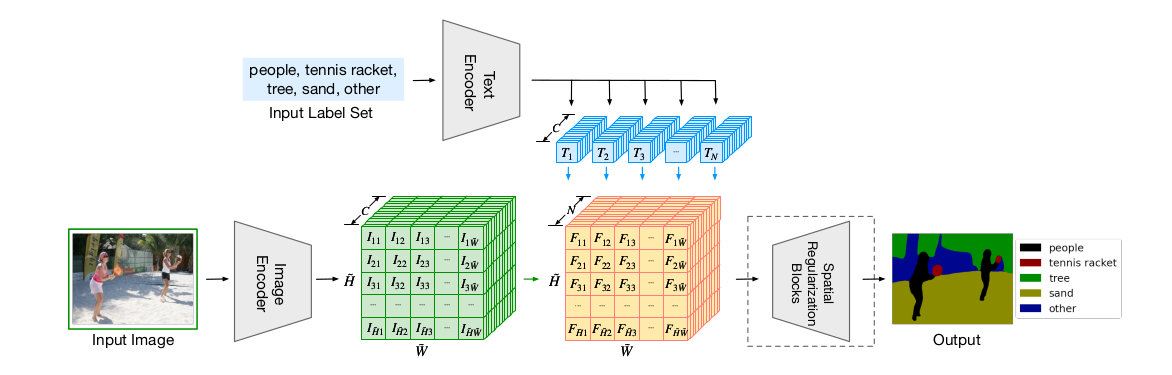
模型的输入是一个图片和文字的配对;图片通过了一个图片编码器 Image Encoder 得到了一些密集特征$C\times \tilde H \times \tilde W$矩阵 ,各元素为$I_{11},I_{12},…,I_{\tilde H \tilde W}$;文本通过一个文本编码器 Text Encoder 得到一些文本的特征$N\times C$矩阵,各元素为 $T_1,T_2,…,T_N$。
图片编码器:dpt的结构-vision Transformer + decoder
decoder目的:把bottleneck feature慢慢upscale;特征维度$C$一般是512或者768
使用原始的ViT或者dit的预训练参数
文本编码器:CLIP里的文本编码器
图片特征和文本特征做点积得到$N\times \tilde H \times \tilde W$矩阵,各元素为$F_{11},F_{12},…,F_{\tilde H \tilde W}$;拿输出特征和最后的ground truth去做cross entropy loss
spetial regularization block 文本和视觉特征交互,加两个这种block效果最好
局限性
目标函数不是对比学习;也不是无监督学习的框架;依赖于手工标注的segametation mask
GroupViT
文章标题:GroupViT: Semantic Segmentation Emerges from Text Supervision
作者:Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang
发表时间:(CVPR 2022)
CLIP做图像分割:监督信号来自于文本
为什么叫group?
视觉做无监督分割经常就是用一类方法叫做grouping(一种自下而上的方式)
类似于有一些聚类中心点,从这个点开始发散,把附近周围相似的点逐渐扩充成一个group,那这个group相当是一个segametation mask。
Methods
ViT + grouping block + 可学习的group tokens
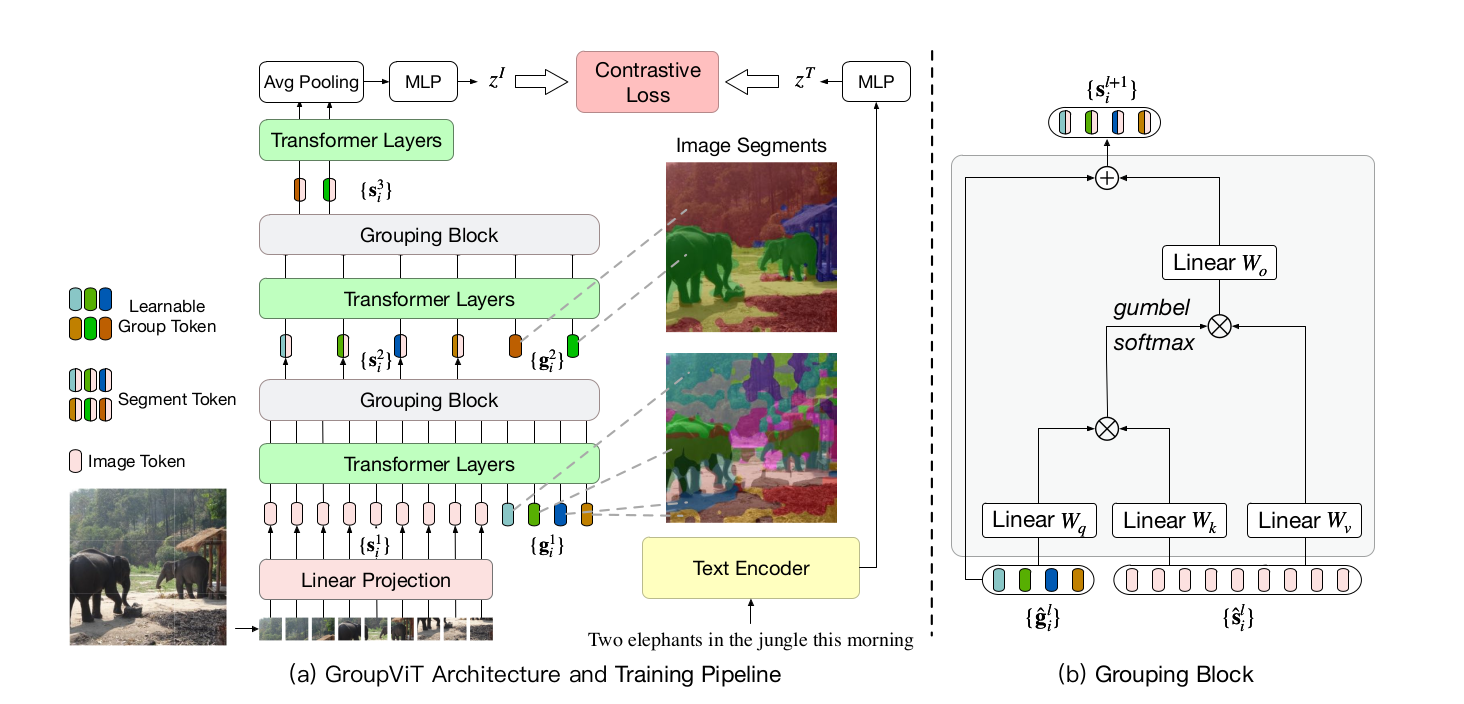
图像编码器:Vision Transformer(12层Transformer layers)
两部分输入
原始图像的patch embedding
大小$224\times224$的图片,patch size选择$16\times16$;就有一个$14\times14=196$序列长度的一个序列 然后经过这个linear projection就得到了patch embedding,维度为$196\times384$(ViT small)
可学习的group tokens
开始设的是$64\times384$:64个聚类中心;384为了保持维度和patch embedding进行拼接
grouping block (6层Transfor Layer之后加了一个grouping block)
类似于自注意力的方式先算一个相似度矩阵,用这个相似的矩阵去帮助原来的这个image token 做聚类中心的分配,从而完成了输入$(196+64)\times384$降到这个$64\times 384$
合并成为更大的group,做一次聚类的分配
降低序列长度,模型的计算复杂度,训练时间相应的都减少了
第9层Transformer Layer 之后又加了一次grouping block:$64\times 384$降到这个$8\times 384$
文本编码器得到文本特在$z^T$;图像编码器输出$8\times 384$进行average pooling得到$1\times384$,在通过MLP得到图片特征$z^I$
后续和CLIP一样对比学习
zero shot推理
给定一个图片首先经过group ViT 得到最后8个group Embedding
再把有可能这些标签通过这个文本编码器得到一系列的这个文本特征
计算这些图像的Group Embedding和这些文本的特征之间的相似度
局限性:最多只能检测到8类;没有很好的利用dense prediction的特性;CLIP 这种训练方式 没有办法学到这些背景类(语义太模糊)
VILD
文章标题:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
作者:Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, Yin Cui
发表时间:(ICLR 2022)
Methods
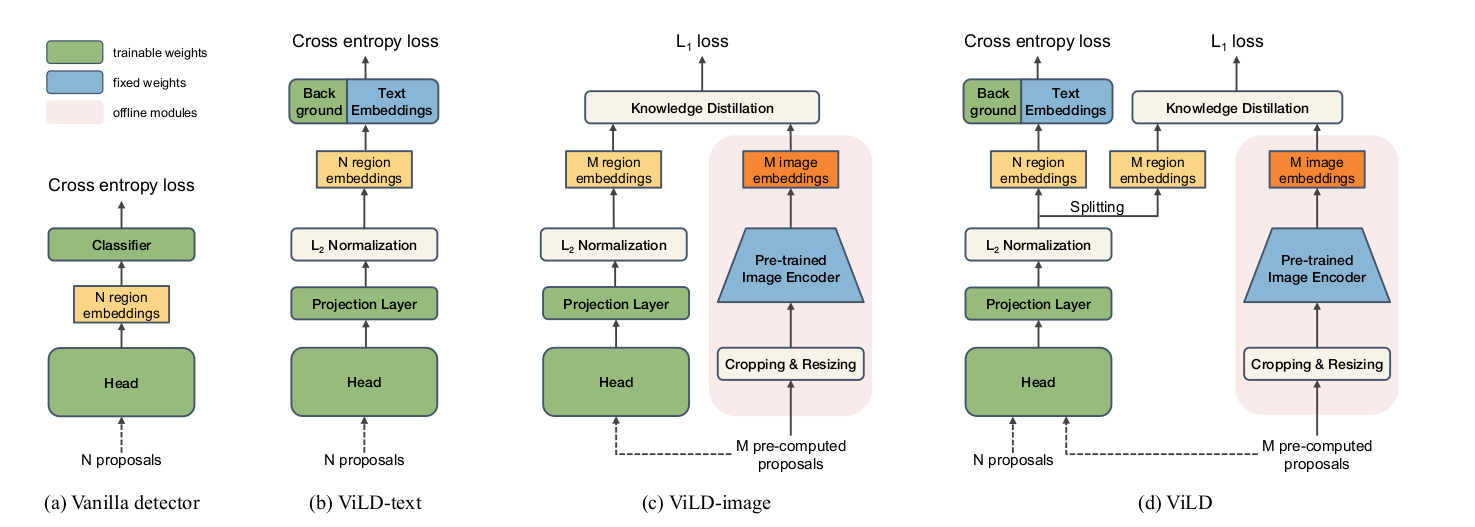
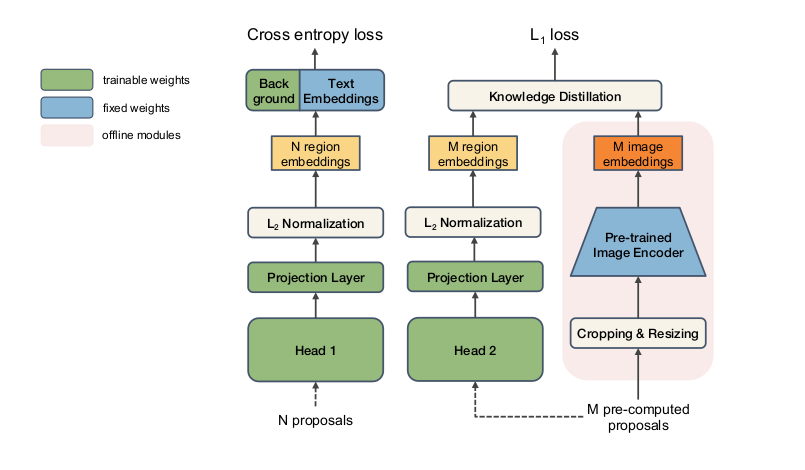
(a) baseline 就是一个maskRCNN(定位+分类)
两阶段的分类器:第一阶段RPN抽取 $N$个region Proposal ;第二阶段就是根据着$N$个 Proposal 通过detection head得到一些region embedding ,最后再通过一些分类头判断类别
(b) ViLD-text:和a类似得到N个region embedding之后,和base category基类+背景类的text embedding去做点乘计算相似度,得到一个81维的向量,将这个向量做softmax,再去和ground truth做交叉熵,得到的结果即为ViLD的损失函数
text embedding:经过CLIP的文本编码器得到的,不参与训练的。(类别通过prompt生成一个句子进入编码器输出)
在b中需要改动的参数有两处,一是图像处理模块,也即抽取图像特征的backbone需要训练;二是背景类的embedding。
背景类:不在基础类里的所有别的类别
(c) ViLD-image:利用CLIP的图像编码器对自己的视觉backbone进行知识蒸馏,让backbone输出的region embedding 尽可能地靠近CLIP的image embedding
一些抽好的Proposal 做一些resize的操作
c 中输入的是M个pre-computed proposal,和a、b不同(加快训练)
预先把所有图像的proposal算出来,然后一次性扔到CLIP图像编码器中先抽好存到硬盘中,这样在训练的时候就直接把这些存好的embedding取出来就可以了。
损失函数:常用的L1 Loss。需要注意的是,作者在把一个proposal送入CLIP的图像编码器时,是将其1x和1.5x分别送入进行编码,最后再把这两个embedding加起来。
损失函数:常用的L1 Loss
(d) ViLD:ViLD-image和ViLD-text两个的合体
左侧将N+M个proposal同时输入进目标检测框架,然后分开,n个Embedding去算cross entropy loss 然后m 个 precomputer embedding去算这个蒸馏的L_1 loss。
右侧为teacher网络,只有训练的时候用,测试的时候用不到。
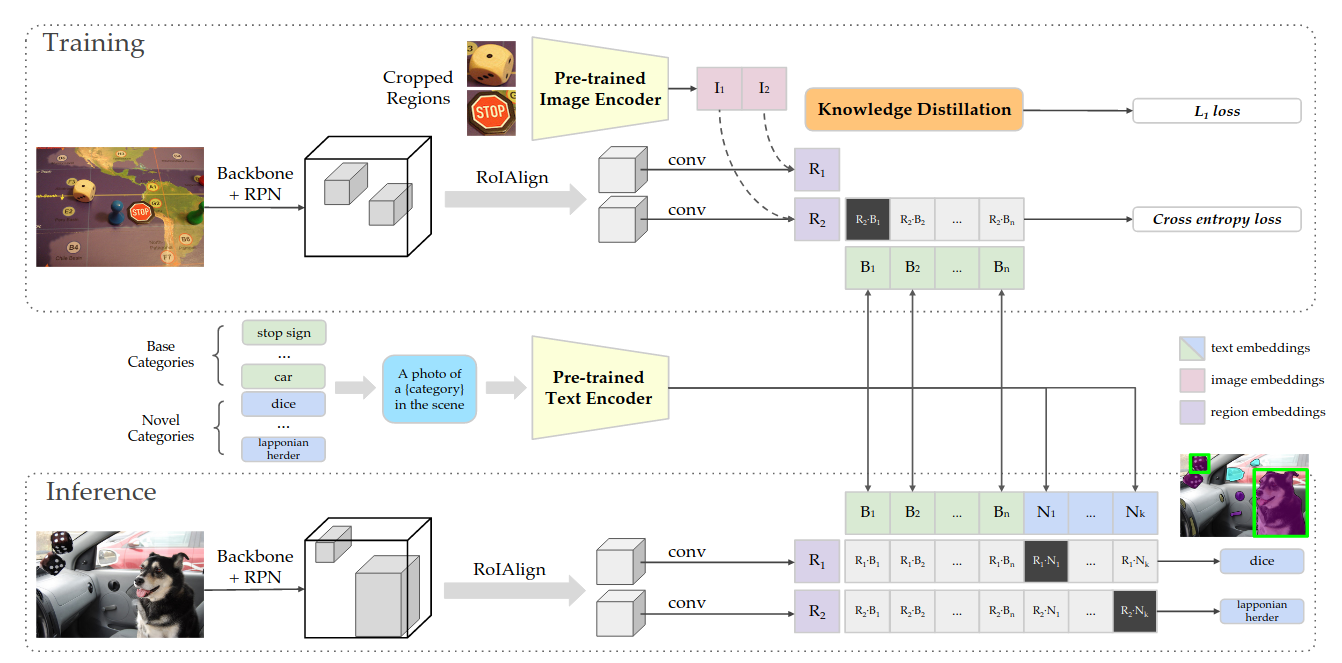
训练阶段
图片先通过一个RPN得到一些region Proposal 然后通过RoI Align 和一些Conv层得到一些region embedding $R_1,R_2$;
绿色的基础类先通过一个prompt然后通过文本编码器得到绿色的文本编码和$R_1,R_2$做点乘,再和ground truth做cross entropy loss; 把已经抽取好的region Proposal 通过CLIP model得到一些CLIP的iamge embedding $ I_1, I_2$;使用蒸馏计算$L_1$ loss 希望$R_1, R_2$呢尽可能的跟$I_1, I_2 $去接近
推理阶段
不论是基础类还是新类都通过prompt再通过这个文本编码器得到所有的这些text embedding;然后让Mask RCNN抽取的region embedding去和text embedding做相似度计算,计算结果最大的那个,就是模型输出的检测到的类型。
拓展阅读
GLIP
文章标题:Grounded Language-Image Pre-training
作者:Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong
发表时间:(CVPR 2022)
object detection 目标检测:给定图片,把bounding box 给找出来
phrase grounding:给定图片和文本,根据文本把物体找出来
定位 loss 部分差不多
分类 loss 部分
detection:它的标签是一个或者两个单词是one-hot的这种标签
给定图片通过backbone得到$N\times D$的region embedding (n个bounding box,每个bounding box Embedding的维度是d);通过$C\times D$矩阵的分类头;MNS把bounding box筛选一下,然后再去跟ground Truth 去算cross entropy loss
Vision grounding:标签是一个句子。
给定图片通过backbone得到了一些region feature;一个句子prompt通过文本编码器得到文本的embedding,进行相似度计算。(类似ViLD-text)
目标检测和Vision grounding 结合
判断一下什么时候算是一个positive match;什么时候算是一个negative match
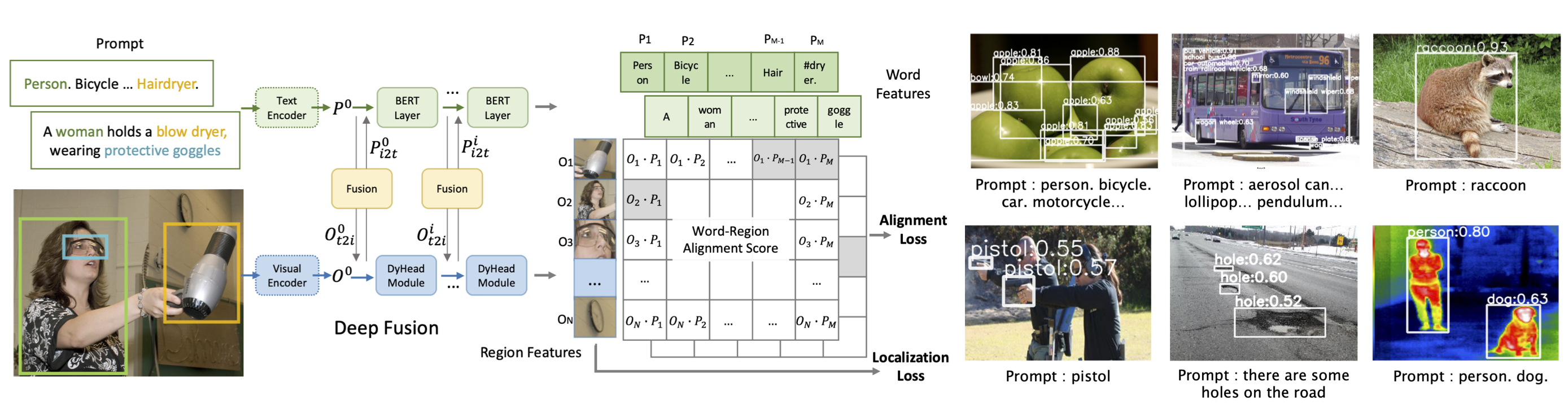
- 图片通过图像编码器得到一些region embedding;文本通过文本编码器得到一些text embedding
- 用Cross Attention啊把这个文本和图像的特征交互一下
拓展阅读
CLIPasso
文章标题:CLIPasso: Semantically-Aware Object Sketching
作者:Yael Vinker, Ehsan Pajouheshgar, Jessica Y. Bo, Roman Bachmann, Amit Haim Bermano, Daniel Cohen-Or, Amir Zamir, Ariel Shamir
发表时间:(SIGGRAPH 2022) (Best Paper Award)
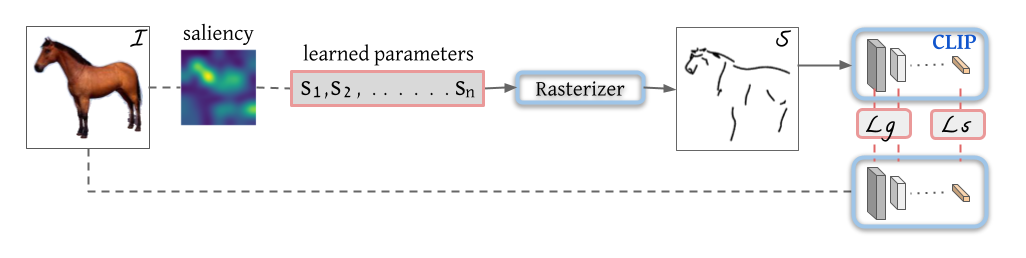
贝兹曲线
通过一系列的2维的点控制的一个曲线
基于saliency的一个初始化的方式
把图片扔给已经训练好的Vision Transformer,然后把最后一层的多头自注意力取加权平均做成了一个siliancy map;在这个siliancy map上去看哪些区域更显著,这些显著的区域上去采点。
定义了这几个曲线,也就这里说的$S_1$到$S_N$就是n个笔画,通过光栅化器Rasterizer得到简笔画。
Loss 选择
$L_s$ 基于语义性的目标函数:简笔画生成的特征和原始图像生成的特征尽可能的接近
$L_g$ 基于geometric的目标函数:resnet的 2 3 4各阶段特征拿出来算loss,而不是用最后的那个2048维的特征。
保证最后生成的简笔画无论是在几何形状上,位置上跟原有的图像尽可能的一致;而且在语义信息上也能尽可能的保持一致
局限性
图像有背景,效果就会大打折扣。必须是一个物体然后处在一个纯白色的背景上
先把一张带背景的图片,把这个物体抠出来,背景是一个白色幕布的图片,扔给CLIPasso去生成简笔画(两阶段)
初始化的笔画都是同时生成的而不是序列生成的(怎样才能一笔一画)
通过控制笔画数去控制图片的抽象程度 (手动–优化参数)
拓展阅读
Multimodal Neurons in Artificial Neural Networks 可视化分析 CLIP
CLIP4Clip
文章标题:CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
作者:Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, Tianrui Li
发表时间:( 2021)
视频领域
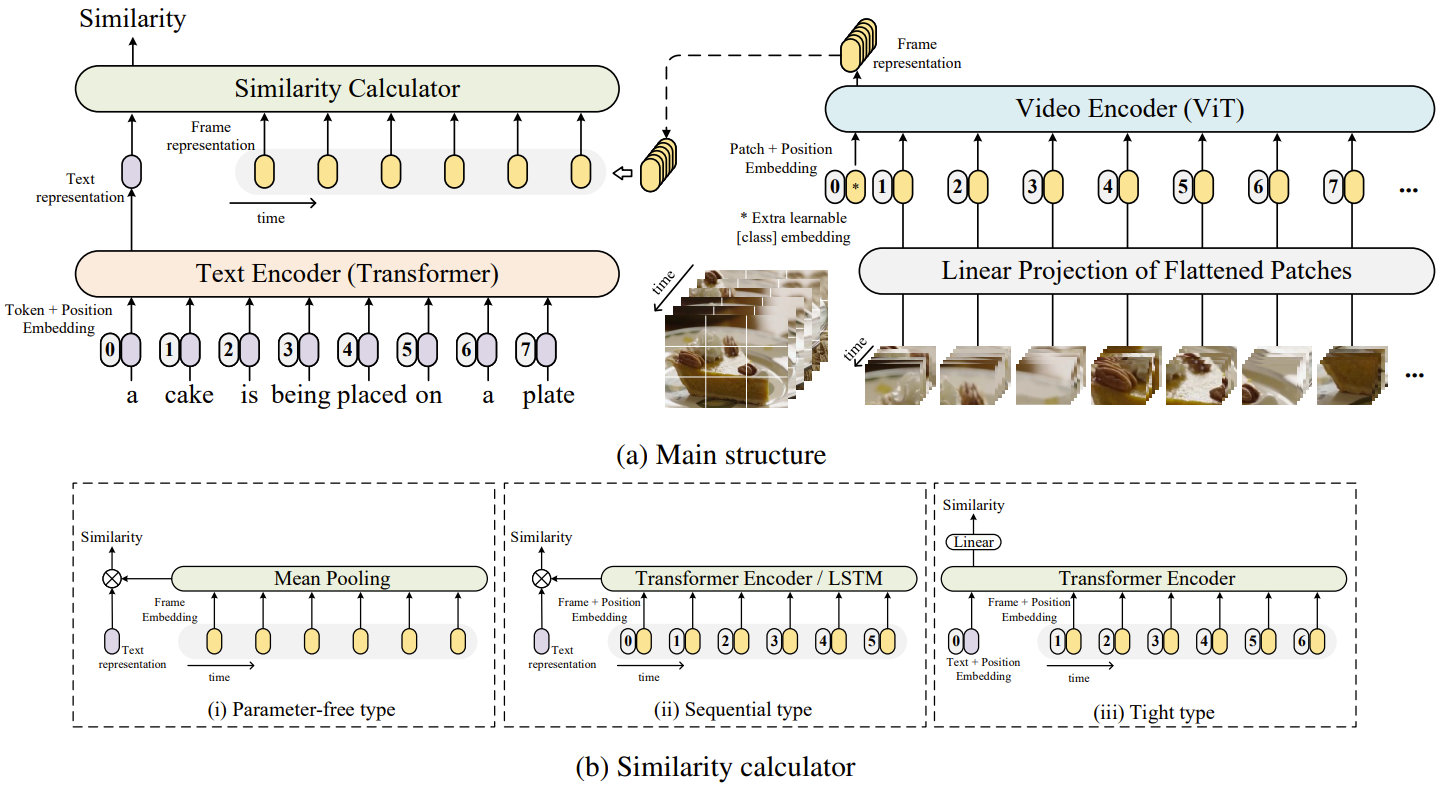
对含有时序的视频特征处理,假设10帧
10个图像的特征直接取平均 (没有考虑到这个时序的特性)
一个是一个人逐渐的在坐下,另外一个是一个人逐渐的站起来;只是取一个这个平均的话,这两个动作无法区分
late fusion: 最原始的lstm把这10个特征扔给一个lstm,把最后的输出拿出来 (时序建模:Transformer替代)
early fusion:把文本和这个图像帧的特征一起在学习
ActionCLIP
文章标题:ActionCLIP: A New Paradigm for Video Action Recognition
作者:Mengmeng Wang, Jiazheng Xing, Yong Liu
发表时间:( 2021)
动作识别
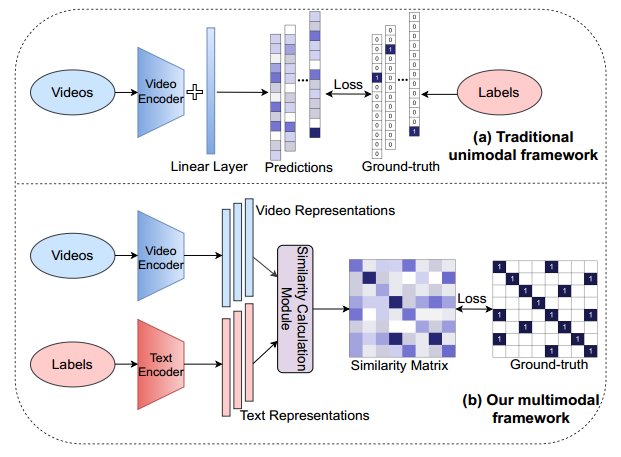
视频的输入通过一个视频编码器得到一些特征,把标签当做文本给一个文本编码器得到一些文本的特征;去计算文本和图像之间的相似度;相似度矩阵和提前定义好的ground truth算一个loss。
把cross entropy loss换成KL divergence
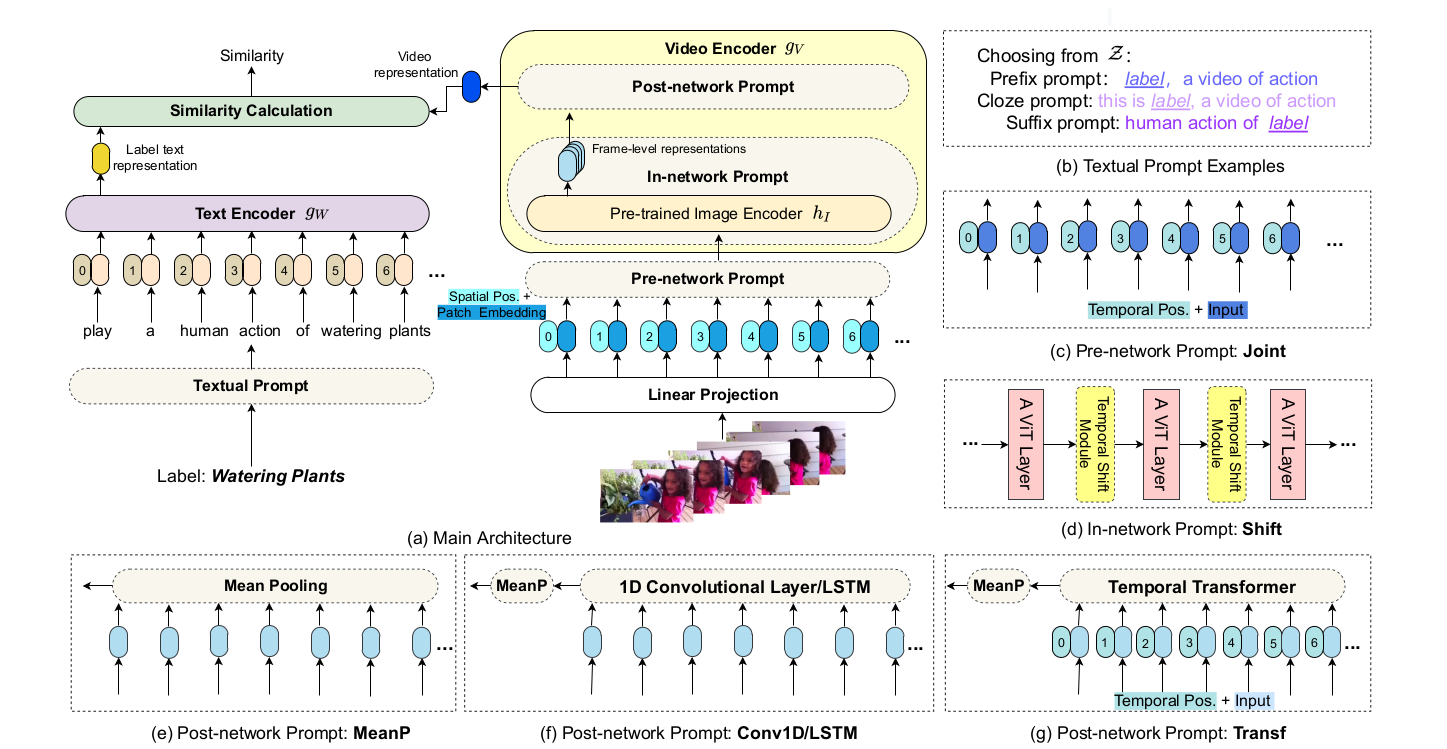
PointCLIP
文章标题:PointCLIP: Point Cloud Understanding by CLIP
作者:Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li
发表时间:(CVPR 2022)
3D点云
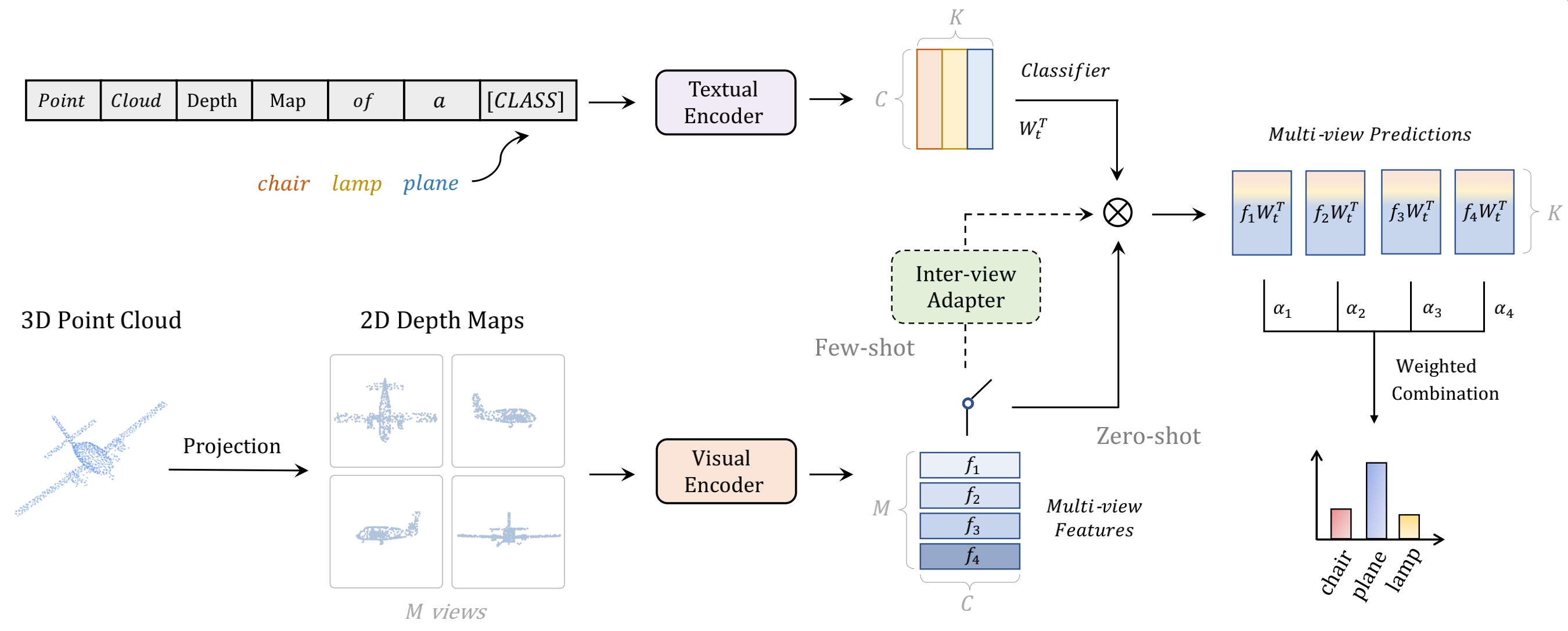
把3D点云投射到2D平面上变成了2D的深度图,扔给clip的视觉编码器得到视觉表征。
文本端通过prompt变成了句子point cloud depth Map of a 『CLASS』
DepthCLIP
文章标题:Can Language Understand Depth?
作者:Renrui Zhang, Ziyao Zeng, Ziyu Guo, Yafeng Li
发表时间:(CVPR 2022)
用文本跨界估计深度
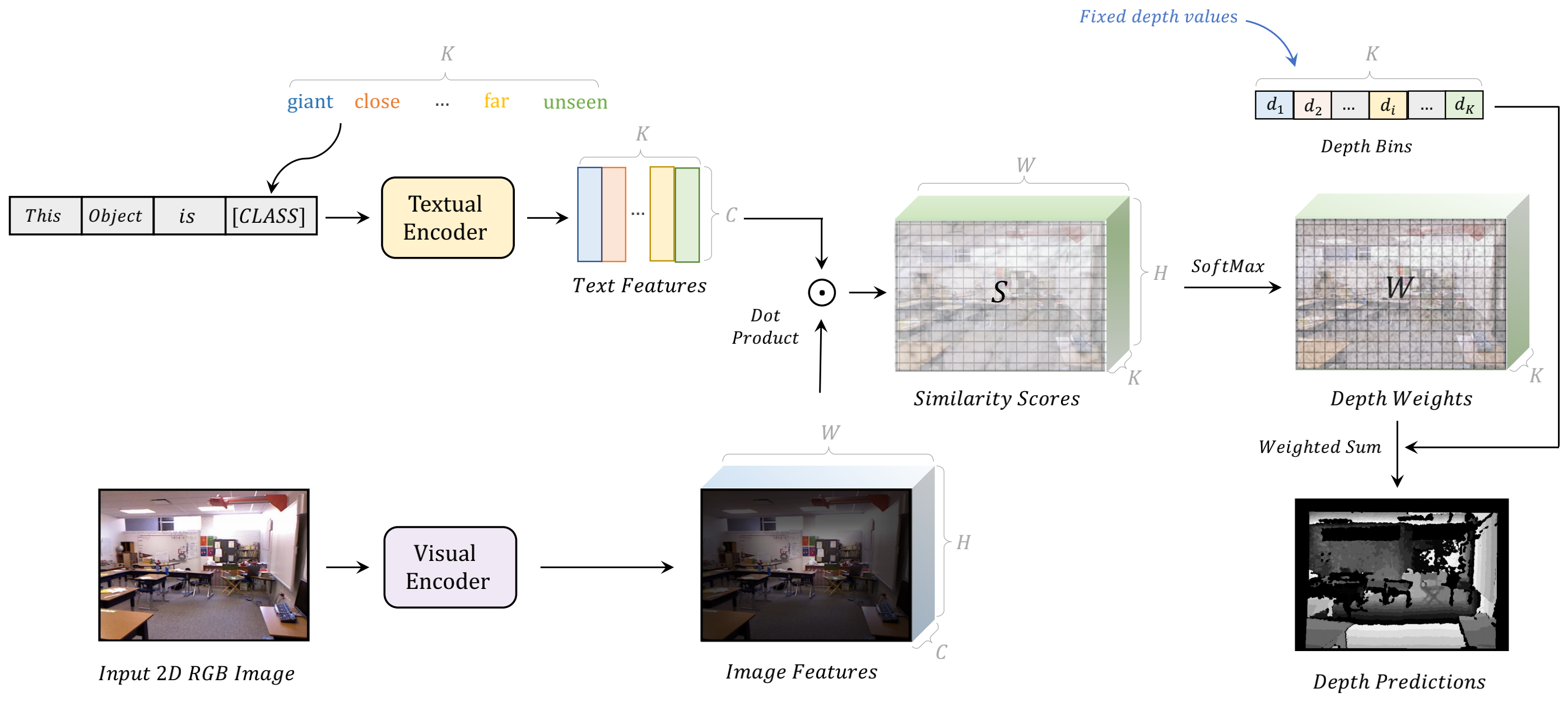
把深度估计看成了一个分类问题,强制性的把深度距离分成了7大类