YOLO
[toc]
YOLO V1
文章标题:You Only Look Once:Unified, Real-Time Object Detection 作者:Joseph Redmon, Santosh Divvalay, Ross Girshick, Ali Farhadi 发表时间:(CVPR 2016)
YOLO算法是单阶段目标检测的经典算法,能实现快速、实时、高精度的图像识别和目标检测。
Abstract
介绍yolo算法及其速度快的优点
将检测变为一个 regression problem,YOLO 从输入的图像,仅仅经过一个 neural network,直接得到 bounding boxes 以及每个 bounding box 所属类别的概率。正因为整个的检测过程仅仅有一个网络,所以它可以直接 end-to-end 的优化。
速度快:标准的 YOLO 版本每秒可以实时地处理 45 帧图像。一个较小版本:Fast YOLO,可以每秒处理 155 帧图像,它的 mAP(mean Average Precision) 依然可以达到其他实时检测算法的两倍。
出现较多coordinate errors定位误差,但YOLO 有更少的 background errors背景误差。
Introduction
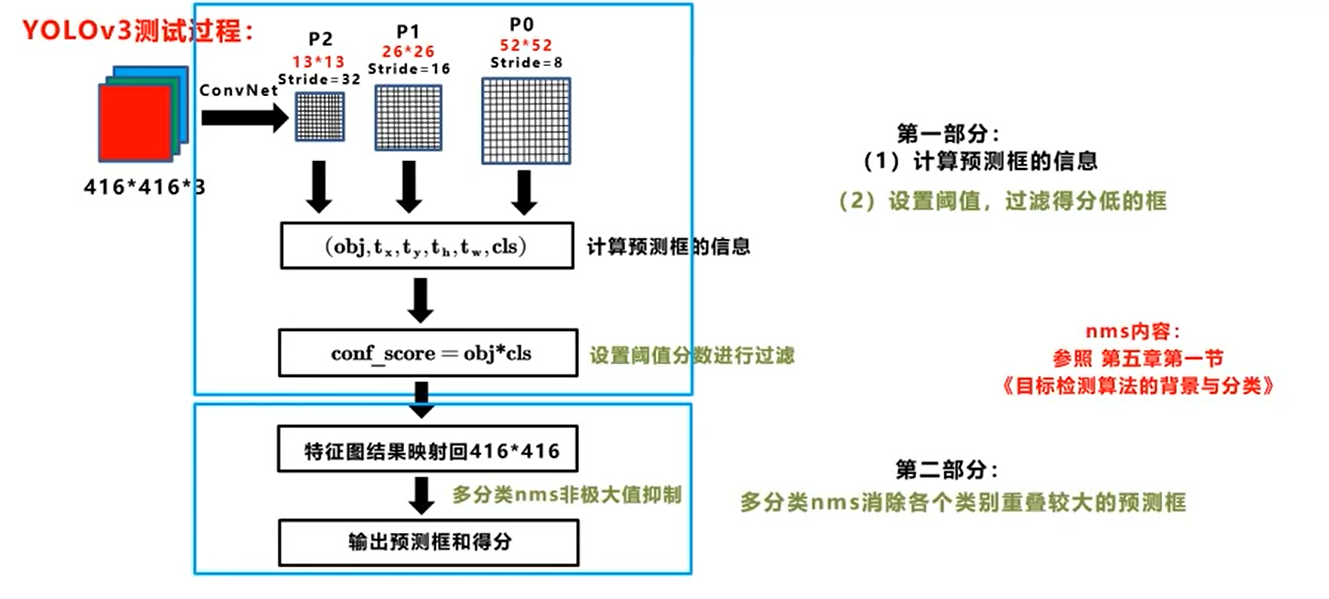
yolo简单原理图;与R-CNN相比yolo的优点;与传统检测算法相比yolo的优点
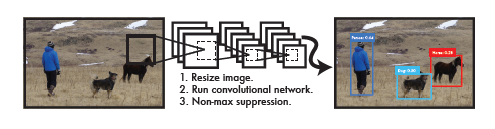
- Resize image.将图片尺寸变为448*448
- Run convolutional network.输入到神经网络中
- Non-max suppression.使用非极大值抑制到最后结果
Unified Detection
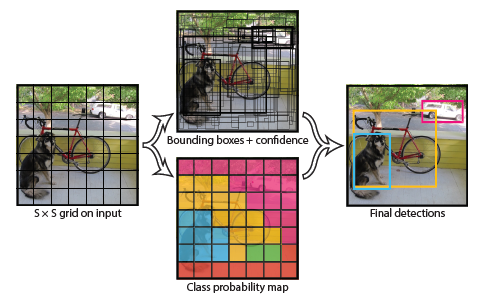
one stage detection算法的原理与细节
将图片隐式的分为S*S个网格(grid cell)
物体的中心落在哪个网格内,哪个网格就负责预测这个物体
每个网格需要预测B个bounding box,C个类别(这B个框预测的为一个类别,一个物体)
如果一个网格内出现两个物体中心?
一个网格里包含了很多小物体?
yolo对靠的很近的物体以及小目标群体检测效果不是很好
每个框包含了位置信息和置信度(x,y,w,h,confidence)
xy表示bounding box的中心相对于cell左上角坐标偏移
宽高则是相对于整张图片的宽高进行归一化的。(物体相对grid cell的大小)
图中框线粗细表示confidence的大小
一张图预测的信息有S*S*(B*5+C)(注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。)
Comfidence Score:指的是一个边界框中包含某个物体的可能性大小以及位置的准确性(即是否恰好包裹这个物体)。
Pr(object)是bounding box内存在对象的概率。Pr(object)并不管是哪个对象,它表示的是有或没有对象的概率。如果有object落在一个grid cell里,第一项取1,否则取0。第二项是预测的bounding box和实际的groundtruth之间的IoU值。其中IOU表示了预测的bbox与真实bbox(GT)的接近程度。置信度高表示这里存在一个对象且位置比较准确,置信度低表示可能没有对象或即便有对象也存在较大的位置偏差。
训练阶段:
Pr(object)标签值非0即1;$IOU^{truth}_{pred}$按实际计算
两者乘积即为Comfidence Score的标签值
对于负责预测物体的box,这个便签值就是$IOU^{truth}_{pred}$
预测阶段:
回归多少就是多少
隐含包含两者
YOLO的bbox是没有设定大小和形状的,只是对两个bbox进行预测,保留预测比较准的bbox。YOLO的2个bounding box事先并不知道会在什么位置,只有经过前向计算,网络会输出2个bounding box,这两个bounding box与样本中对象实际的bounding box计算IOU。
Network design
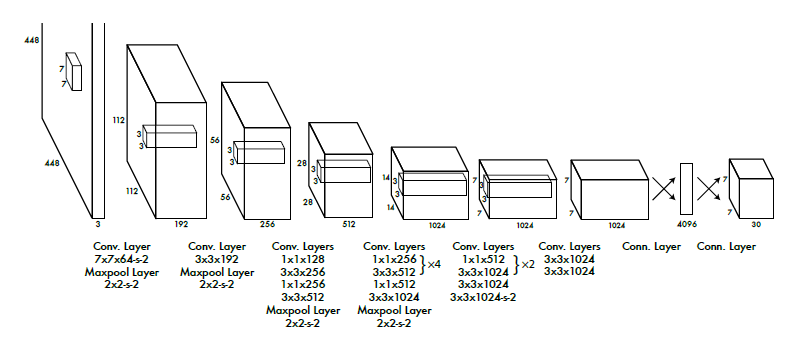
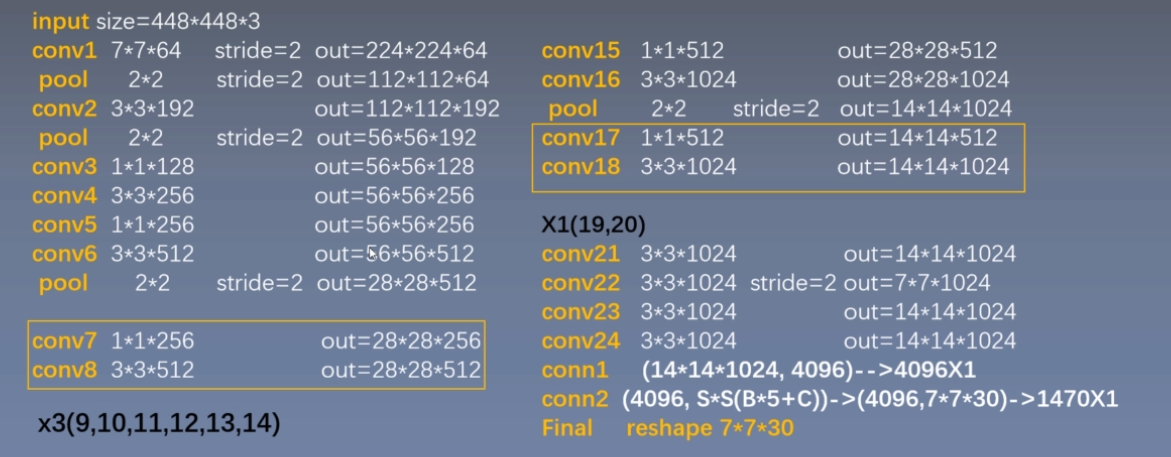
24层卷积层提取图像特征
2层全连接层回归得到$7\times7\times30$的Tensor
Training
yolo训练方法,损失函数及参数
最后一层用线性激活函数,其他层用leaky ReLU;
相比于ReLU,leaky并不会让负数直接为0,而是乘以一个很小的系数(恒定),保留负数输出,但是衰减负数输出
损失函数
设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。

$\mathbb I_{i j}^{obj}$:第$i$个grid cell的第$j$个bounding box若==负责==预测物体则为1,否则为0;
$\mathbb I_{i j}^{nobj}$:第$i$个grid cell的第$j$个bounding box若==不负责==预测物体则为1,否则为0;
$\mathbb I_{i }^{obj}$:第$i$个grid cell是否包含物体,即是否有ground truth 框的中心点落在此grid cell中,若有则为1,否则为0
全部采用sum-squared error loss存在的问题:
第一,8维的localization error和20维的classification error同等重要显然是不合理的;
第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。
解决办法:
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight,记为$\lambda_{coord}$在pascal VOC训练中取5。
对没有object的box的confidence loss,赋予小的loss weight,记为$\lambda_{noobj}$在pascal VOC训练中取0.5。
有object的box的confidence loss和类别的loss的loss weight正常取1。
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。而sum-square error loss中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。
.png) yolov1损失函数
yolov1损失函数
训练设置
batchsize=64;momentum=0.9(动量因子);decay=0.0005(权重衰减$ L_2$正则化)
第一个迭代周期学习率从$10^{-3}$到 $10^{-2}$;$10^{-2}$训练第2-75轮;$10^{-3}$再训练30轮;$10^{-4}$再训练30轮;
在第一个连接层之后,丢弃层使用=.05的比例,防止层之间的互相适应
数据增强:
引入原始图像$20%$大小的随机缩放和转换
在HSV色彩空间中使用1.5的因子来随机调整图像的曝光和饱和度。
Inference
yolo预测阶段细节
$$ Pr(Class_i|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr(Object)*IOU^{truth}_{pred} $$等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
Limitations of YOLO
速度快:把检测作为回归问题处理,流程简单,仅需要输入一张图
泛化能力强:yolo可以学习到物体的通用特征,泛化能力更好。应用在新领域不会崩掉。
全局推理:对整张图处理,利用全图信息,假阳性错误少(背景当作物体错误率少)
精度与最先进的算法比不高,对小物体不友好
分类正确但定位误差大
Comparison to Other Detection Systems
DPM
传统特征:HOG
传统分类器:SVM
滑窗套模板
弹簧模型:子模型+主模型
R-CNN
候选区域生成
提取特征
SVM进行分类
NMS剔除重叠建议框
使用回归器精细修正候选框位置
Deep MultiBox
OverFeat
使用全卷积网络进行高效滑窗运算
Experiments

与实时检测器相比:
fast yolo 不仅速度而且map还高
yolo的map比fast yolo高,而且也可以达到实时检测
与速度稍慢的检测器相比:yolo在保证不错的精度同时速度最快。
各类错误比例分析
Real-Time Detection In The Wild
yolo可以连接摄像头进行实时检测
Conclusion
结论再次强调yolo的优点:one-stage 快速 鲁棒
拓展阅读
Object Detection in 20 Years: A Survey
Joseph Redmon
[简历]([https://pjreddie.com/static/Redmon%20Resume.pdf](https://pjreddie.com/static/Redmon Resume.pdf))
2017年8月TED演讲:How computers learn to recognize objects instantly | Joseph Redmon
2018年6月TED演讲:Computers can see. Now what? | Joseph Redmon | TEDxGateway
YOLO V2
文章标题:YOLO9000: Better, Faster, Stronger 作者:Joseph Redmon, Ali Farhadi 发表时间:(CVPR 2017)
YOLOV2是YOLO目标检测系列算法的第二个版本。
第一部分:在YOLOV1基础上进行了若干改进优化,得到YOLOV2,提升算法准确度和速度。特别是增加了Anchor机制,改进了骨干网络。
第二部分:提出分层树状的分类标签结构WordTree,在目标检测和图像分类数据集上联合训练,YOLO9000可以检测超过9000个类别的物体。
CVPR 2017论文:YOLO9000: Better, Faster, Stronger,获得CVPR 2017 Best Paper Honorable Mention
Better
其目的是弥补YOLO的两个缺陷:
定位误差
召回率(Recall)较低(和基于候选区域的方法相比)
Recall 是被正确识别出来的物体个数与测试集中所有对应物体的个数的比值。

Batch Normalization
CNN网络通用的方法,不但能够改善网络的收敛性,而且能够抑制过拟合,有正则化的作用。
BN与Dropout通常不一起使用
High Resolution Classifier
在YOLO V2中使用ImageNet数据集,首先使用224×224的分辨率训练160个epochs,然后调整为448×448在训练10个epochs。
Convolutional With Anchor Boxes
在YOLO V2中借鉴 Fast R-CNN中的Anchor的思想。
去掉了YOLO网络的全连接层和最后的池化层,使提取特征的网络能够得到更高分辨率的特征。
使用$416\times416$代替$448\times448$作为网络的输入,得到的特征图的尺寸为奇数。
奇数大小的宽和高会使得每个特征图在划分cell的时候就只有一个center cell
网络最终将$416\times416$的输入变成$13\times13$大小的feature map输出,也就是缩小比例为32。(5个池化层,每个池化层将输入的尺寸缩小1/2)。
Anchor Boxes( 提高object的定位准确率)在YOLO中,每个grid cell只预测2个bbox,最终只能预测$7\times7\times2=98$个bbox。在YOLO V2中引入了Anchor Boxes的思想,,每个grid cell只预测5个anchor box,预测$13\times13\times5=845$个bbox。 总性能下降;recall增大;precision降低
Dimension Clusters (聚类)
(解决每个Grid Cell生成的bounding box的个数问题)
K均值聚类
距离度量指标:$d(box,centroid)=1-IOU(box,centroid)$
针对同一个grid cell,其将IOU相近的聚到一起
选择k=5
Direct location prediction
模型不稳定,由于预测box的位置(x,y)引起的
Faster RCNN:
$x=(t_x\times w_a)+x_a$
$y=(t_y\times h_a)+y_a$
$x,y$是预测边框的中心, $x_a,y_a$是先验框(anchor)的中心点坐标, $w_a,h_a$是先验框(anchor)的宽和高, $t_x,t_y$是要学习的参数。输出的偏移量
YOLOV2:将预测边框的中心约束在特定gird网格内
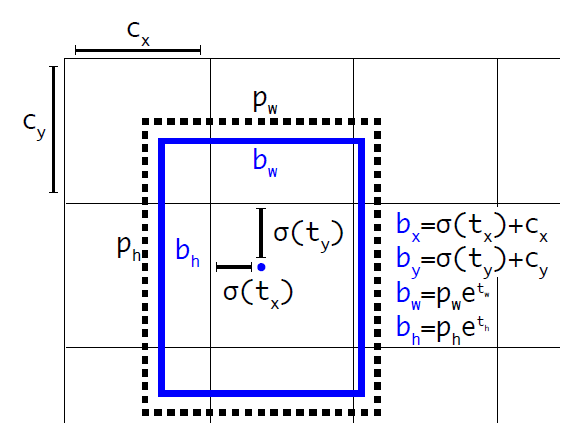
$b_x=\sigma(t_x)+c_x$
$b_y=\sigma(t_y)+c_y$
$b_w=p_we^{t_w}$
$b_h=p_he^{t_h}$
$Pr(object)*IOU(b,object)=\sigma(t_o)$
$b_x,b_y,b_w,b_h$是预测边框的中心和宽高。 $Pr(object)∗IOU(b,object)$是预测边框的置信度,YOLO1是直接预测置信度的值,这里对预测参数$t_o$进行σ变换后作为置信度的值。 $c_x,c_y$是当前网格左上角到图像左上角的距离,要先将网格大小归一化,即令一个网格的宽=1,高=1。 $p_w,p_h$是先验框的宽和高。 $\sigma$ 是sigmoid函数。 $t_x,t_y,t_w,t_h,t_o$是要学习的参数,分别用于预测边框的中心和宽高,以及置信度。
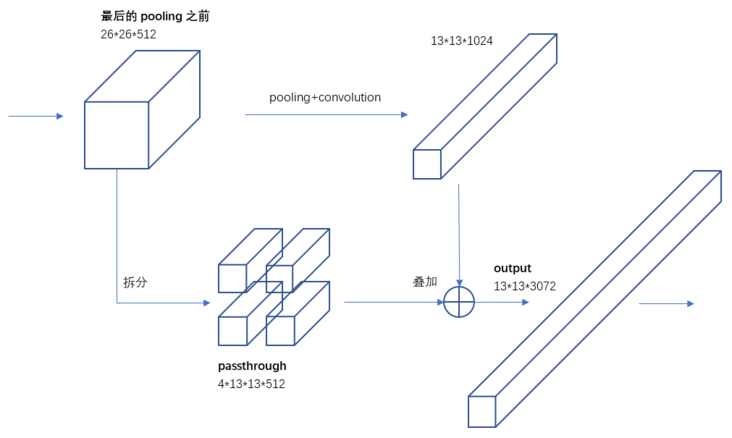
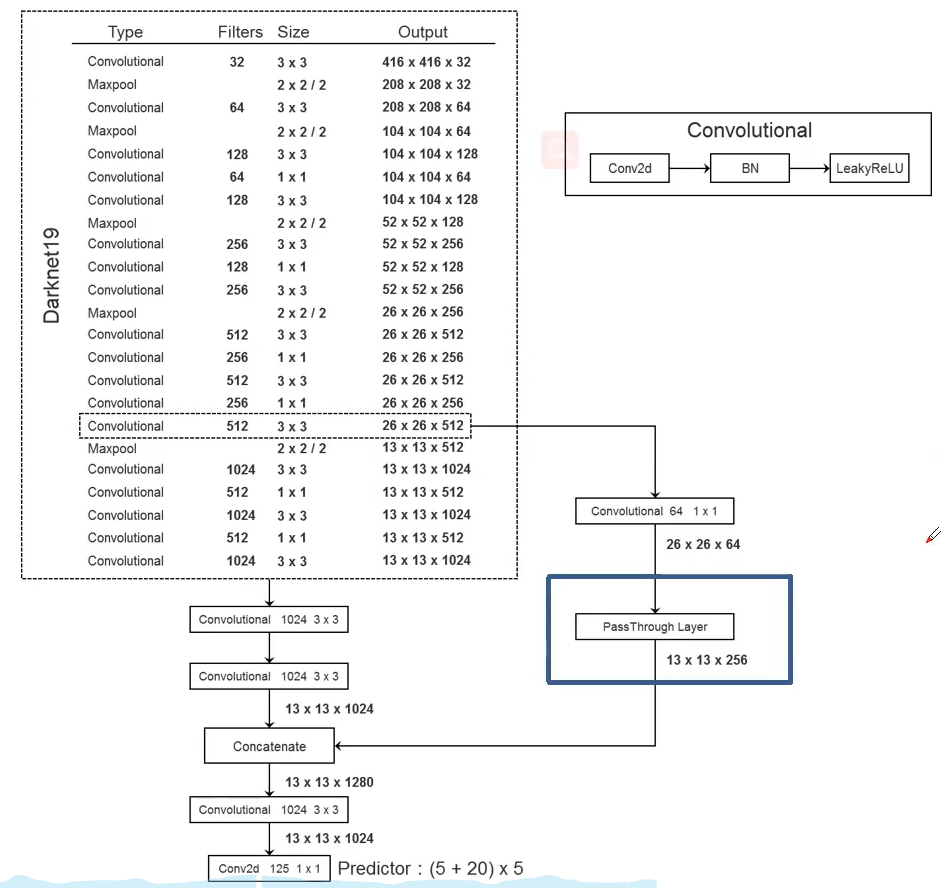
Fine-Grained Features 细粒度特征
提出一种称之为“直通”层(passthrough layer)的操作,也是将具有丰富纹理信息的浅层特征与具有丰富语义信息的深层特征进行融合,实现对目标的“大小通吃”。
据YOLO2的代码,特征图先用$1\times1$卷积从$ 26\times26\times512 $降维到$ 26\times26\times64$,再做1拆4并passthrough。
Multi-Scale Training
通过不同分辨率图片的训练来提高网络的适应性。
采用了{320,352,…,608}等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是{10,11,…19}。训练时每10个batch就随机更换一种尺寸,使网络能够适应各种大小的对象检测。
Faster
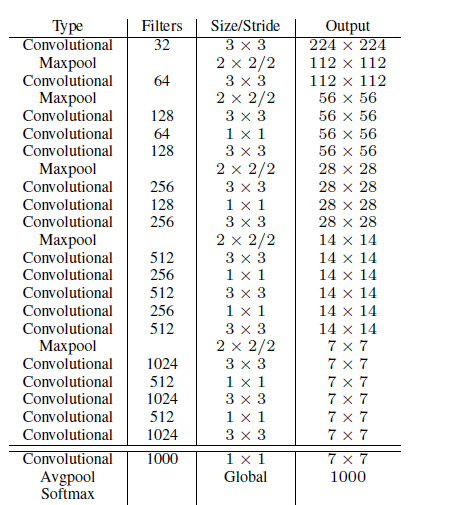
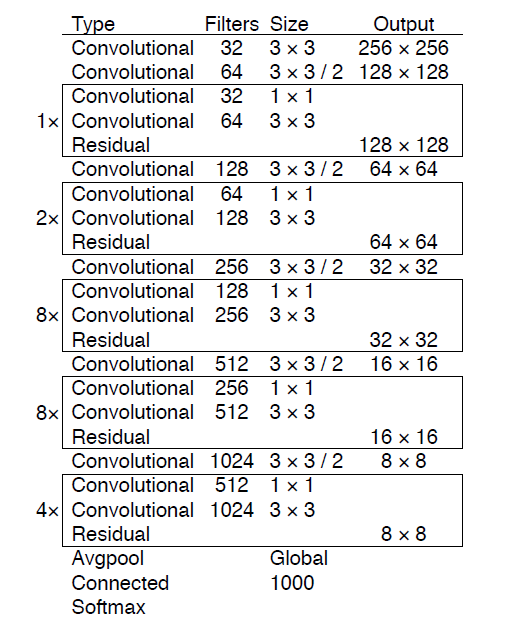
Darknet-19
Training for detection
损失函数
$$ \begin{array}{r} \operatorname{loss}_{t}=\sum_{i=0}^{W} \sum_{j=0}^{H} \sum_{k=0}^{A} \mathbb I_{\text {Max IOU }<\text { Thresh }} \lambda_{\text {noobj }} *\left(-b_{i j k}^{o}\right)^{2} \\ +\mathbb I_{t<12800} \lambda_{\text {prior }} * \sum_{r \in(x, y, w, h)}\left(\text { prior }_{k}^{r}-b_{i j k}^{r}\right)^{2} \\ +\mathbb I_{k}^{\text {truth }}\left(\lambda_{\text {coord }} * \sum_{r \in(x, y, w, h)}\left(\text { truth }^{r}-b_{i j k}^{r}\right)^{2}\right. \\ +\lambda_{o b j} *\left(I O U_{\text {truth }}^{k}-b_{i j k}^{o}\right)^{2} \\ \left.+\lambda_{\text {class }} *\left(\sum_{c=1}^{C}\left(\operatorname{truth}^{c}-b_{i j k}^{c}\right)^{2}\right)\right) \end{array} $$W:输出特征图宽度13;H:输出特征图高度13; A:先验框个数为5
置信度误差(边框内无对象)background的置信度误差
$b_{ijk}^o$预测框置信度
计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background
预测框与Anchor位置误差(前12800次迭代)
$prior_k^r$:Anchor位置;$b_{ijk}^r$:预测框位置
$\mathbb I_k^{truth}$:该Anchor和ground truth的IOU最大对应的预测框负责预测物体(IOU>0.6但非最大的预测框忽略其损失)
定位误差(边框内有对象)
$truth^r$:标注框位置;$b_{ijk}^r$:预测框位置
置信度误差(边框内有对象)
$I O U_{\text {truth }}^{k}$ :Anchor与标注框的IOU; $b_{i j k}^{o}$:预测框置信度
分类误差(边框内有对象)
$truth^c$:标注框类别;$b_{ijk}^c$:预测框类别
Stronger
拓展阅读
知乎:<机器爱学习>YOLOv2 / YOLO9000 深入理解
YOLO V3
文章标题:YOLOv3: An Incremental Improvement 作者:Joseph Redmon ,Ali Farhadi 发表时间:(CVPR 2018)
YOLOV3是单阶段目标检测算法YOLO系列的第三个版本,由华盛顿大学Joseph Redmon发布于2018年4月,广泛用于工业界。
改进了正负样本选取、损失函数、Darknet-53骨干网络,并引入了特征金字塔多尺度预测,显著提升了速度和精度。
The Deal
[Bounding Box Prediction](###Direct location prediction)
正负样本的匹配
预测框(每个GT仅分配一个Anchor负责预测)
正例:与GT IOU最大
负例:IOU<0.5
忽略:IOU>0.5但非最大
Predictions Across Scales多尺度
| 输入 | grid cell | Anchor | 预测框数 | 输出张量的数据结构 | |
|---|---|---|---|---|---|
| YOLO V1 | $448\times448$ | $7\times7$ | 0 | $7\times7\times2=98$ | $7\times7\times(5\times B+C)$ |
| YOLO V2 | $416\times416$ | $13\times13$ | 5 | $13\times13\times5=845$ | $845\times(5+20)$ |
| YOLO V3 | $256\times256$ | $32\times32$,$16\times16$,$8\times8$ | 3 | $4032$ | $4032\times(5+80)$ |
| $416\times416$ | $52\times52$,$26\times26$,$13\times13$ | 3 | $10647$ | $10647\times(5+80)$ |
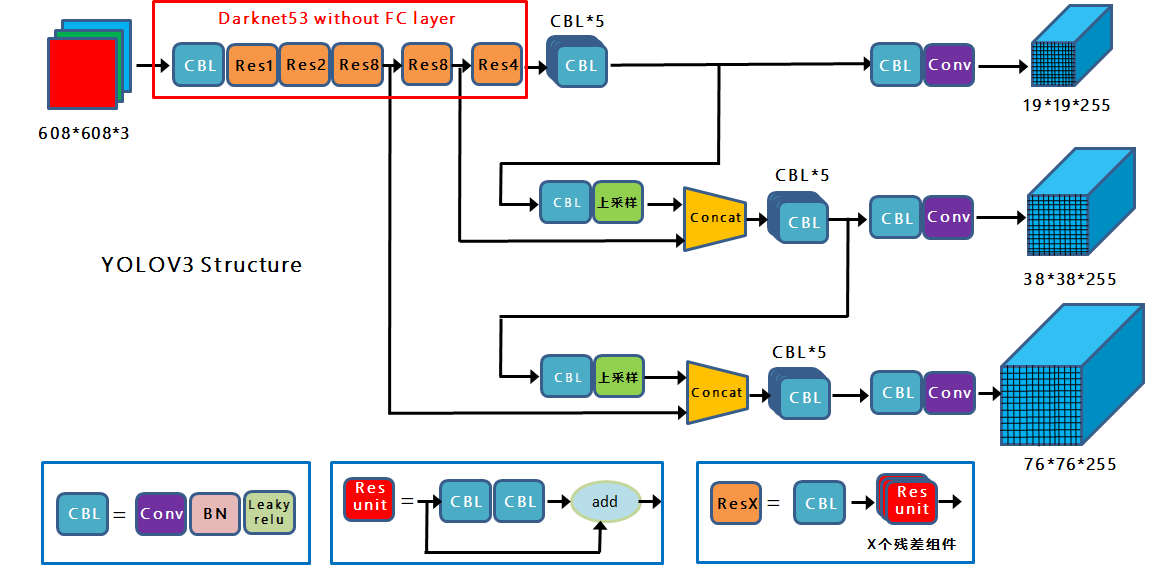
Yolov3借鉴了FPN特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为 $N\times N\times[3\times(4+1+80)]$,$N\times N为$输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值$t_x,t_y,t_w,t_h$ ,1维预测框置信度,80维物体类别数。
yolov3网络图
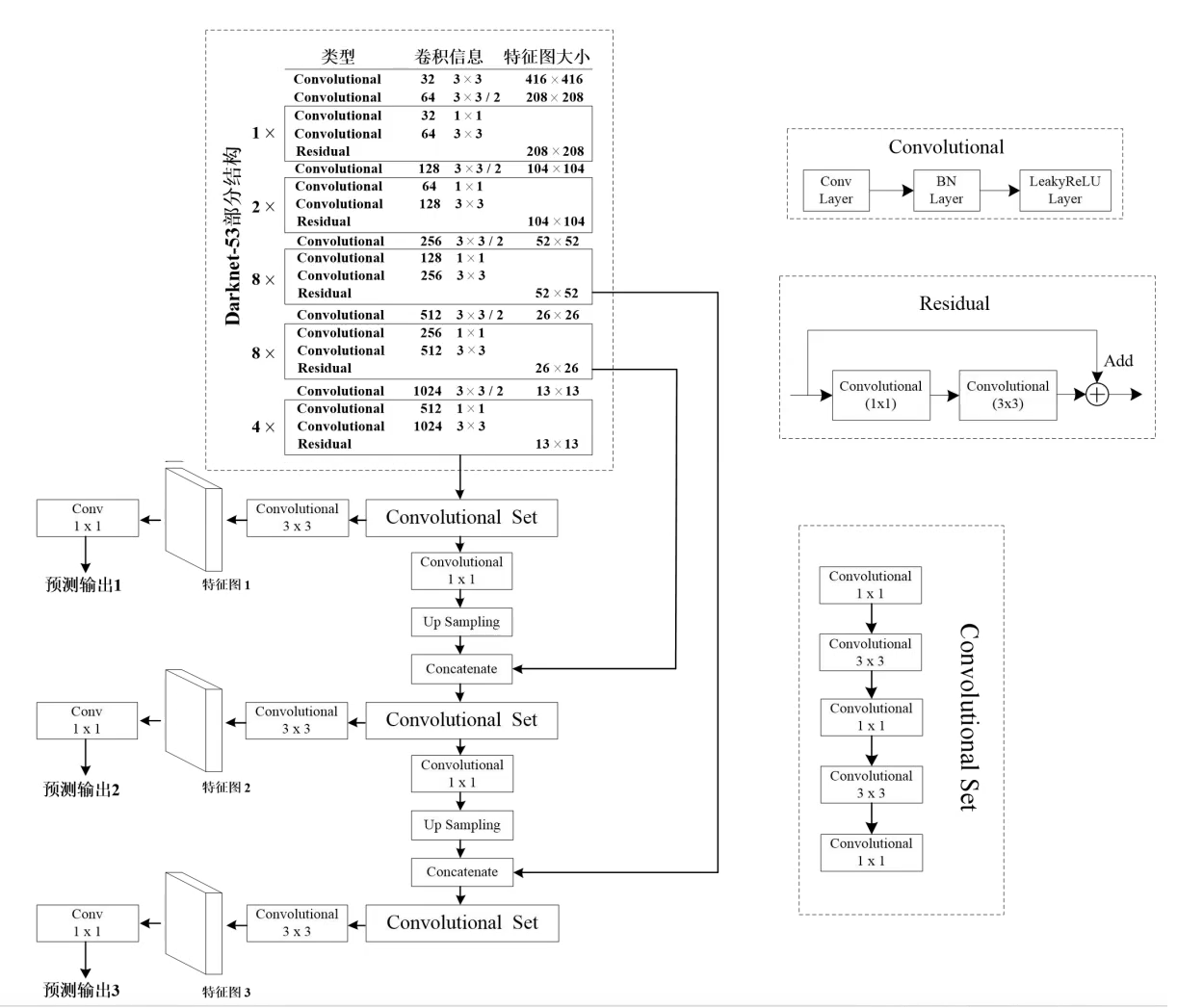
- Yolov3中,只有卷积层,通过调节卷积步长控制输出特征图的尺寸
- concat操作与加和操作的区别:加和操作来源于ResNet思想,将输入的特征图,与输出特征图对应维度进行相加,即$y=f(x)+x$ ;而concat操作源于DenseNet网络的设计思路,将特征图按照通道维度直接进行拼接,例如的$8\times8\times16$特征图与$8\times8\times16$的特征图拼接后生成$8\times8\times32$的特征图。
- 上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将$8\times8$的图像变换为$16\times16$。上采样层不改变特征图的通道数。
损失函数
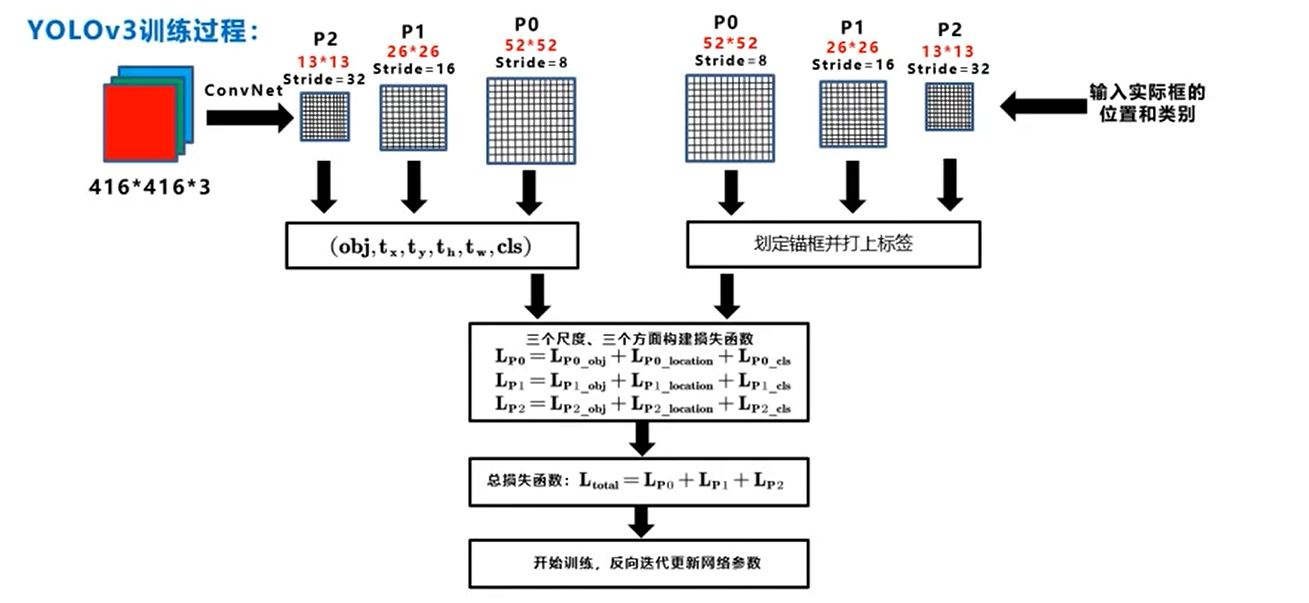
$$ \begin{equation} \begin{split} {loss} &= \sum_{i=0}^{K^2}\sum_{j=0}^{M}\mathbb{I}_{i,j}^{obj}\cdot (2-w_i\cdot h_i)(-x_i log(\hat x_i)-(1-x_i)log(1-\hat x_i))\\ &+\quad\sum_{i=0}^{K^2}\sum_{j=0}^{M}\mathbb{I}_{i,j}^{obj}\cdot (2-w_i\cdot h_i)(-y_i log( \hat y_i)-(1-y_i)log(1-\hat y_i))\\ &+\quad\ \sum_{i=0}^{K^2}\sum_{j=0}^{M}\mathbb{I}_{i,j}^{obj}\cdot (2-w_i\cdot h_i)[(w_i-\hat w_i)^2+(h_i-\hat h_i)^2]\\ &- \quad \sum_{i=0}^{K^2}\sum_{j=0}^{M}\mathbb{1}_{i,j}^{obj}\cdot[C_ilog(\hat C_i)+(1-C_i)log(1-\hat C_i)]\\ &- \quad \sum_{i=0}^{K^2}\sum_{j=0}^{M}\mathbb{1}_{i,j}^{noobj}\cdot[C_ilog(\hat C_i)+(1-C_i)log(1-\hat C_i)]\\ &-\quad \sum_{i=0}^{K^2}\sum_{j=0}^{M}\mathbb{1}_{i,j}^{obj}\cdot\sum_{c\in classes}[p_i(c)log(\hat p_i(c))+(1-p_i(c))log(1-\hat p_i(c))] \\ \end{split}\end{equation} $$一个是目标框位置$x,y,w,h$(左上角和长宽)带来的误差,又分为$x,y$带来的BCE Loss以及$w,h$带来的MSE Loss。
K:grid size;M:Anchor box;$\mathbb{I}_{i,j}^{obj}$表示如果在$i,j$处的box有目标,则为1,否则为0;w 和 h 分别是ground truth 的宽和高
带$\hat x$号代表预测值;不带的表示标签
一个是目标置信度带来的误差,也就是obj带来的loss(BCE Loss)
$\mathbb{I}_{i,j}^{noobj}$:是否为负样本
最后一个是类别带来的误差,也就是class带来的loss(类别数个BCE Loss)。
$BCE=-\hat c_ilog(c_i)-(1-\hat c_i)log(1-c_i)$:二元交叉熵损失函数(Binary Cross Entropy);$\hat c_i$标签值(非0即1);$ c_i$预测值(0-1之间)
拓展阅读
代码复现
Ultralytics公司:https://github.com/ultralytics/yolov3
https://github.com/qqwweee/keras-yolo3
https://github.com/bubbliiiing/yolo3-pytorch
cvpods:https://github.com/Megvii-BaseDetection/cvpods/blob/master/cvpods/modeling/meta_arch/yolov3.py
博客
YOLO V4
文章标题:YOLOv4: Optimal Speed and Accuracy of Object Detection 作者:Alexey Bochkovskiy,Chien-Yao Wang, Hong-Yuan Mark Liao 发表时间:(CVPR 2020)
Introduction
- 提出了一种实时、高精度的目标检测模型。 它是可以使用1080Ti 或 2080Ti 等通用 GPU 来训练快速和准确的目标检测器;
- 在检测器训练阶段,验证了一些最先进的 Bag-of-Freebies 和 Bag-of-Specials 方法的效果;
- 对 SOTA 方法进行改进,使其效率更高,更适合单 GPU 训练,包括 CBN,PAN 和 SAM 等。
Related work
Bag of freebies
只改变训练策略或只增加训练成本,不影响推理成本的方法;白给的提高精度(赠品)
Data Augmentation 数据增强
增加输入图片的可变性;更高的鲁棒性。
像素级调整;保留调整区域内的所有原始像素信息。
photometric distortions 光照畸变
brightness, contrast,hue, saturation, and noise of an image亮度、对比度、色调、饱和度和噪声
geometric distortions 几何畸变
random scaling, cropping, flipping, and ro-tating 随机缩放、裁剪、翻转和旋转
模拟对象遮挡
random erase 随机擦除
CutOut :随机屏蔽输入的方形区域的简单正则化技术填充0像素值
hide-and-seek:训练图像中随机隐藏patches,当最具区别性的内容被隐藏时,迫使网络寻找其他相关内容
grid mask:通过生成1个和原图相同分辨率的mask,然后将该mask和原图相乘得到一个GridMask增强后的图像。
正则化
DropOut:随机删除减少神经元的数量,使网络变得更简单
DropBlock:将Cutout应用到每一个特征图。并不是用固定的归零比率,而是在训练时以一个小的比率开始,随着训练过程线性的增加这个比率;可应用于网络的每一层;不同组合,灵活
图像融合
MixUp:使用两个图像以不同的系数比率进行乘法和叠加,然后用这些叠加的比率调整标签
CutMix:把Mixup和Cutout结合,切割一块patch并且粘贴上另外一张训练图片相同地方的patch,对应的label也按照patch大小的比例进行混合
风格迁移
类别不平衡
Two stage:RCNN …
hard negative example mining:用初始的正负样本(一般是正样本+与正样本同规模的负样本的一个子集)训练分类器, 然后再用训练出的分类器对样本进行分类, 把其中负样本中错误分类的那些样本(hard negative)放入负样本集合, 再继续训练分类器, 如此反复, 直到达到停止条件(比如分类器性能不再提升).
online hard example mining:自动地选择难分辨样本来进行训练
One stage:SSD,yolo…
One-hot难表达类别之间的关联
label smoothing(Inception V3):将硬标签转化为软标签进行训练,可以使模型更具有鲁棒性
knowledge distillation:引入知识蒸馏的概念并用于设计标签细化网络
BBox Regression
- 重叠面积
- 中心点距离
- 长宽比
发展历程:IOU_Loss(2016)->GIOU_Loss(2019)->DIOU_Loss(2020)->CIOU_Loss(2020)
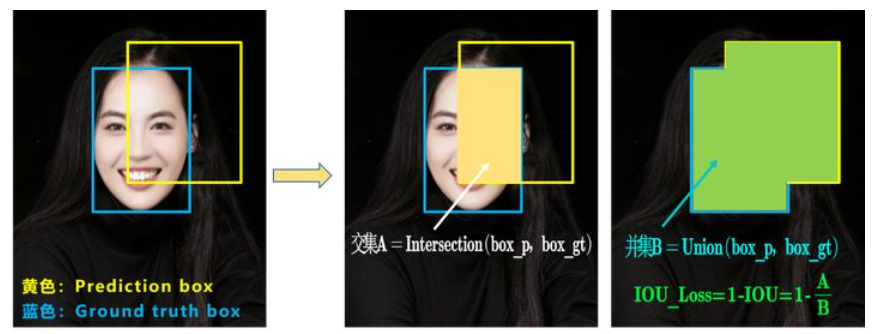
IOU_Loss
A:预测框与真实框的交集;B:预测框与真实框的并集
$IOU=\frac{A}{B}$
$IOU_{Loss}=1-IOU$ :考虑了预测BBox面积和ground truth BBox面积的重叠面积
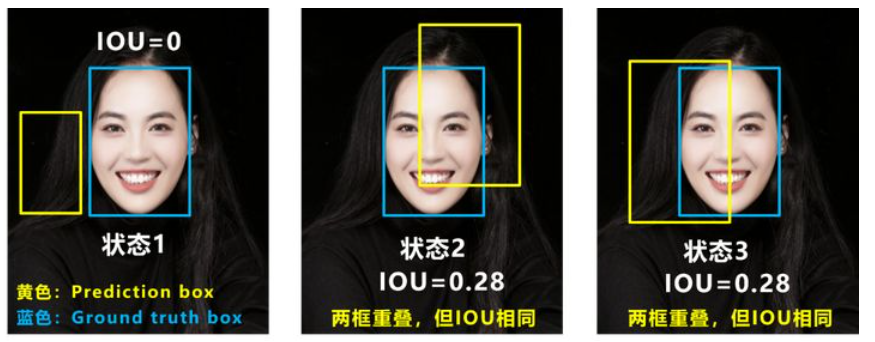
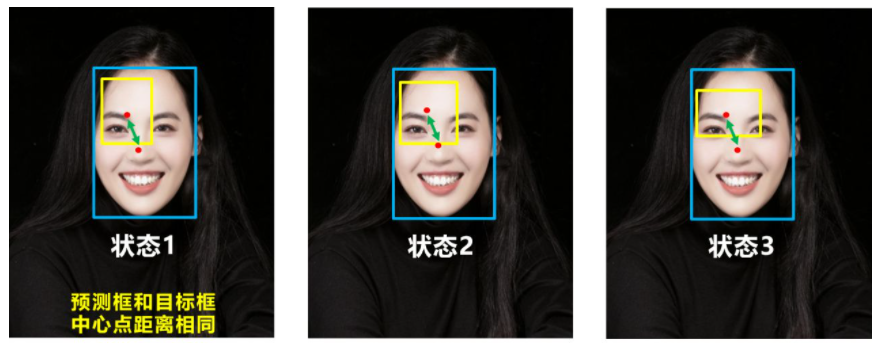
Q1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
Q2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
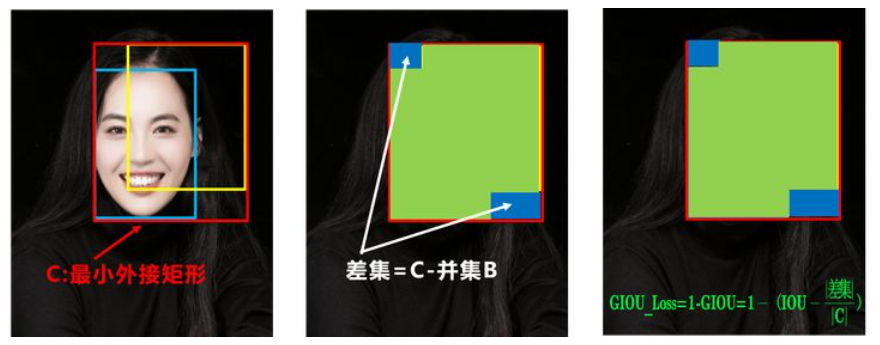
GIOU_Loss
$GIOU=IOU-\frac{|C-B|}{|C|}$;C:两框的最小外接矩形;差集=C-并集B
$GIOU_{Loss}=1-GIOU$ :增加了相交尺度的衡量方式
Q:状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
DIOU_Loss
$DIOU=IOU-\frac{{Distance_2}^2}{Distance_C^2}$;Distance_C:C的对角线距离;Distance_2:两个框的两个中心点的欧氏距离$DIOU_Loss=1-DIOU$ :考虑了重叠面积和中心点距离;当目标框包裹预测框的时候,直接度量2个框的距离,因此DIOU_Loss收敛的更快。
Q:目标框包裹预测框;预测框的中心点的位置都是一样的
CIOU_Loss
$CIOU=IOU-\frac{{Distance_2}^2}{Distance_C^2}-\frac{v^2}{(1-IOU)+v}$ $v=\frac{4}{\pi^2}(arctan\frac{w^{gt}}{h^{gt}}-arctan\frac{w^{p}}{h^{p}})^2$ : gt表示目标框的宽高;p表示预测框的宽高
$CIOU_{Loss}=1-CIOU$:同时考虑到重叠面积和中心点之间的距离以及长宽比


Bag of specials
少量增加了推理成本,却显著提升性能的插件模块和后处理方法;不免费,但很实惠(特价)
Enlarging Receptive Field 扩大感受野
SPP :SPP将SPM集成到CNN使用max-pooling操作而不是bag-of-word运算;
源于SPM
将特征图分割成几个d×d相等大小的块,其中d可以是{1,2,3,…},从而形成空间金字塔,然后提取bag-of-word特征。
[YOLOV3](###YOLO V3)改进版SPP模块:将SPP模块修改为融合$k×k$池化核的最大池化输出,其中$k = {1,5,9,13}$,步长等于1。
一个相对较大的$k×k$有效地增加了backbone的感受野
ASPP :和改进版SPP模块区别是主要由原来的步长1、核大小为$k×k$的最大池化到几个$3×3$核,缩放比例为$k$,步长1的空洞卷积。
RFB :几个$k×k$核,缩放比例为$k$,步长1的空洞卷积
Attention Mechanism 注意力机制
channel-wise attention
point-wise attention
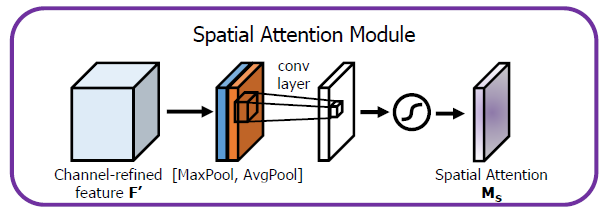
SAM 对卷积层的输出特征图应用最大池化和平均池化。将这两个特征做concat操作来,然后在一个卷积层中传递,然后应用 sigmoid 函数,该函数将突出显示最重要的特征所在的位置。
Feature Integration 特征融合模块
skip connection (FCN)
SFAM :使用SE模块在多尺度串联的特征图上执行channel-wise级别的重新加权
ASFF :使用softmax作为point-wise级别重新加权,然后添加不同尺度的特征图
BiFPN :提出了多输入加权残差连接以执行按 scale-wise级别重新加权,然后添加不同尺度的特征图。
Activation Function 激活函数
让梯度更有效地传播,同时不会造成太多额外的计算成本
ReLU:基本上解决梯度消失问题 traditional:$tanh,sigmoid$
LReLU ,PReLU :解决输出小于零时ReLU的梯度为零的问题。
ReLU6 (MobileNet),hard-Swish (MobileNet V3):专为量化网络设计
Scaled ExponentialLinear Unit (SELU) :self-normalizing 神经网络设计
Mish 的下界和上界为 [≈ -0.31,∞]。由于保留了少量的负面信息,Mish通过设计消除了**Dying ReLU现象**所必需的先决条件。较大的负偏差会导致 ReLu 函数饱和,并导致权重在反向传播阶段无法更新,从而使神经元无法进行预测。
Mish 属性有助于更好的表现力和信息流。由于在上面无界,Mish 避免了饱和,这通常会由于接近零的梯度而导致训练减慢。下界也是有利的,因为它会产生很强的正则化效果。
Post-processing Method 后处理方法
用来过滤对同一物体预测不好的BBoxes,只保留响应较高的候选BBoxes
Greedy NMS (R-CNN):增加分类置信度;由高到低顺序
Soft NMS :考虑了对象的遮挡可能导致具有IoU得分的Greedy NMS中的置信度得分下降的问题
DIOU NMS:在soft NMS的基础上,在BBox筛选过程中加入中心点距离信息。
Anchor free里不使用NMS后处理:NMS都没有直接涉及提取特征图
Methodology
目的是在输入网络分辨率、卷积层数目、参数数量和每层输出个数之间找到最佳平衡
Selection of architecture
检测器和分类器不同点
- 更大的输入网络尺寸(分辨率)——用于检测多个小尺寸目标
- 更多的层数——获得更大的感受野以便能适应网络输入尺寸的增加
- 更多参数——获得更大的模型容量以便在单个图像中检测多个大小不同的物体。
不同大小的感受野的影响
- 最大目标尺寸——允许观察到整个目标
- 最大网络尺寸——允许观察到目标周围的上下文
- 超出网络尺寸——增加图像像素点与最终激活值之间的连接数
Selection of BoF and BoS
[Activations](####Activation Function 激活函数): ReLU, ==leaky-ReLU==, parametric-ReLU,ReLU6, SELU, ==Swish==, ==Mish==
RRelu和SELU难训练;ReLU6是量化网络专用(排除选项)
[Bounding box regression loss](####Post-processing Method 后处理方法): MSE, IoU, GIoU,CIoU, DIoU
不用CIOU_nms:影响因子v包含标注框信息;前向推理没有标注框信息
[Data augmentation](####Data Augmentation 数据增强l): CutOut, MixUp, CutMix,Mosaic
[Regularization method](####Data Augmentation 数据增强l): DropOut, DropPath ,Spatial DropOut , DropBlock
DropBlock最优
Normalization : BN, CGBN or SyncBN) ,FRN,CBN)
一个GPU:排除SyncBN
Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections(MiWRC), Cross stage partial connections (CSP)
Additional improvements
引入了一种新的数据增强方法Mosaic和自对抗训练方法(Self-Adversarial Training,SAT)
Mosaic:随机裁剪4个训练图片,再拼接到1张图片(COCO数据集目标分布不均衡)
丰富数据集
减少GPU
归一化计算每层的4张不同图片计算激活统计信息
减少large mini-batch size的需求
Augementation for small object dection 2019:界定大中小目标$(0-32;32-96;96-∞)$
Self-Adversarial Training (SAT) 自对抗训练
以2个forward backward stages的方式进行操作。在第一个阶段,神经网络改变的是原始图像而不是的网络权重。这样神经网络对其自身进行对抗性攻击,改变原始图像并创造出图像上没有目标的假象。在第2个阶段中,通过正常方式在修改的图像上进行目标检测对神经网络进行训练。
使用遗传算法选择最优超参数
修改的SAM、修改的PAN和Cross mini-Batch Normalization (CmBN)
Modified SAM Modified PAN SAM从spatial-wise attention修改为point-wise attention。
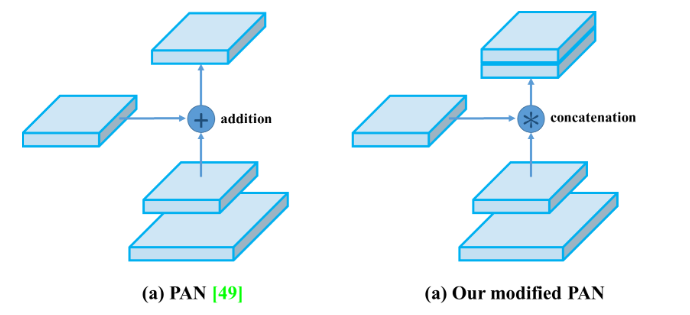
PAN的 shortcut connection改为concatenation。
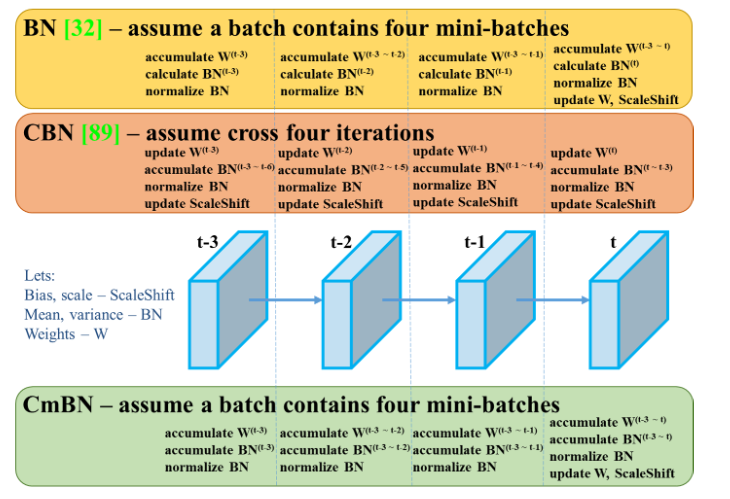
BN是对当前mini-batch进行归一化, Cross mnin-Batch NormalizationCBN是对当前以及当前往前数3个mini-batch的结果进行归一化,
CmBN 表示 CBN 修改版本,这仅在单个批次内的mini-batch之间收集统计信息。
当batch size变小时,BN不会执行。标准差和均值的估计值受样本量的影响。样本量越小,就越不可能代表分布的完整性。

YOLO V4
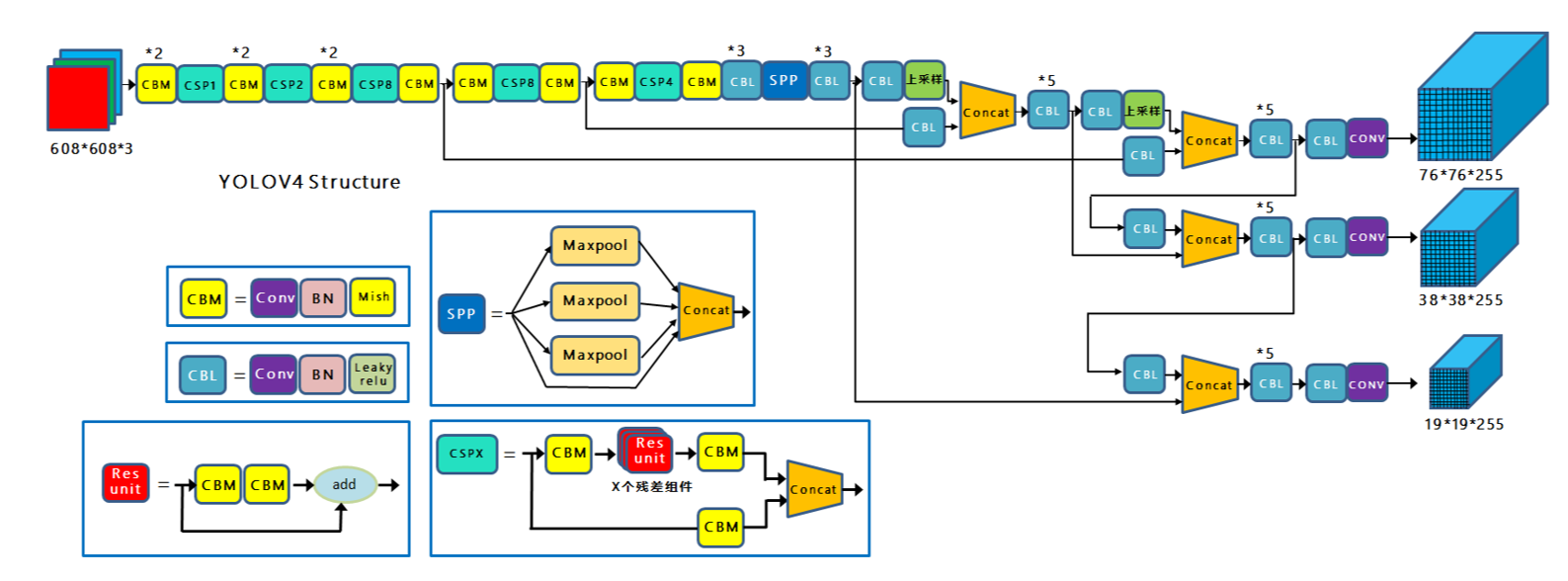
Backbone :CSPDarkNet53
每个CSP模块前面的卷积核的大小都是$3\times3$,stride=2,起到下采样的作用。
因为Backbone有5个CSP模块,输入图像是$608\times608$,所以特征图变化的规律是:608->304->152->76->38->19
Cross Stage Partial Network 跨阶段局部网络:CSPNet
CSPNet: A New Backbone that can Enhance Learning Capability of CNN
CSP模块,解决网络优化中的梯度信息重复
将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并
通过截断梯度流来防止过多的重复梯度信息。
增强CNN学习能力,使得在轻量化的同时保持准确性
降低计算瓶颈
降低内存成本
Neck:PAN ,[SPP](####Enlarging Receptive Field 扩大感受野)
SPP模块:显著地增加了感受野,分离出最显著的上下文特征,并且几乎没有造成网络运行速度的降低。
《DC-SPP-Yolo》:主干网络采用SPP比单一的使用最大池化方式更加有效地增加主干特征的接收范围;可以显著分离上下文特征。
FPN,自顶向下,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图。传达强语义特征
PAN,自顶向上,传达强定位特征
Head:YOLOV3
使用技巧
Bag of Freebies (BoF) for backbone
CutMix和Mosaic数据增强,DropBlock正则化, 类标签平滑
Bag of Specials (BoS) for backbone
Mish激活函数,跨阶段部分连接(CSP),多输入加权残差连接 (MiWRC)
Bag of Freebies (BoF) for detector:
CIoU损失函数, CmBN, DropBlock正则化,Mosaic数据增强,自对抗训练(SAT),Eliminate grid sensitivity,为每个真实标签使用多个anchor,Cosine annealing scheduler,优化的超参数,随机的训练形状
Bag of Specials (BoS) for detector:
Mish激活函数,SPP模块,SAM模块,路径聚合模块(PAN), DIoU-NMS
Experiments
实验设置
ImageNet图像分类实验
训练步骤:8,000,000
batch size=128;mini-batch size=32
多项式衰减调度策略初始学习率=0.1
warm-up步骤=1,000
动量因子=0.9;衰减权重=0.005
均使用1080 Ti或2080 Ti GPU进行训练
MS COCO目标检测实验
训练步骤:500,500
batch size=64执行多尺度训练;mini-batch size=8或者4
步阶衰减学习率调度策略,初始学习率=0.01,分别在40万步和45万步上乘以系数0.1
动量因子=0.9;衰减权重=0.0005
遗传算法使用YOLOv3-SPP训练GIoU损失,并搜索300个epoch的最小5k集
搜索学习率=0.00261,动量=0.949,IoU阈值= 0.213, loss normalizer 0.07。
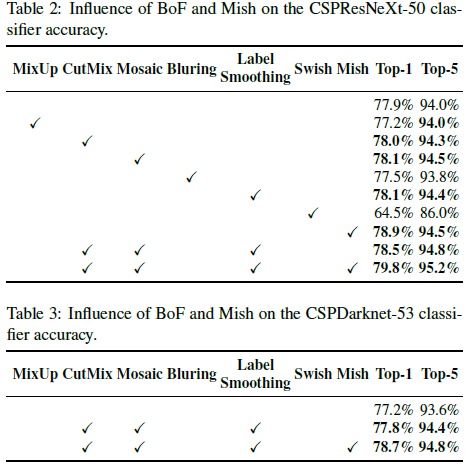
不同技巧对分类器和检测器训练的影响
分类器训练的BoF-backbone (Bag of Freebies)包括CutMix和Mosaic数据增强、类别标签smoothing。

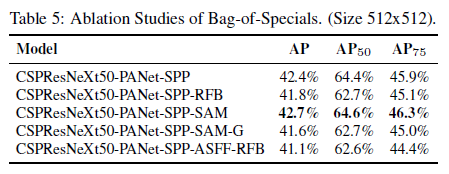
不同backbone和预训练权重对检测器训练的影响
CSPDarknet53比CSPResNeXt50更适合于做检测器的backbone
不同的mini-batch size对检测器训练的影响
训练时加入BoF和BoS后mini-batch大小几乎对检测器性能没有任何影响
不再需要使用昂贵的GPU来进行训练;一个即可
拓展阅读
知乎:深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解
YOLOv4重磅发布,五大改进,二十多项技巧实验,堪称最强目标检测万花筒
Explanation of YOLO V4 a one stage detector
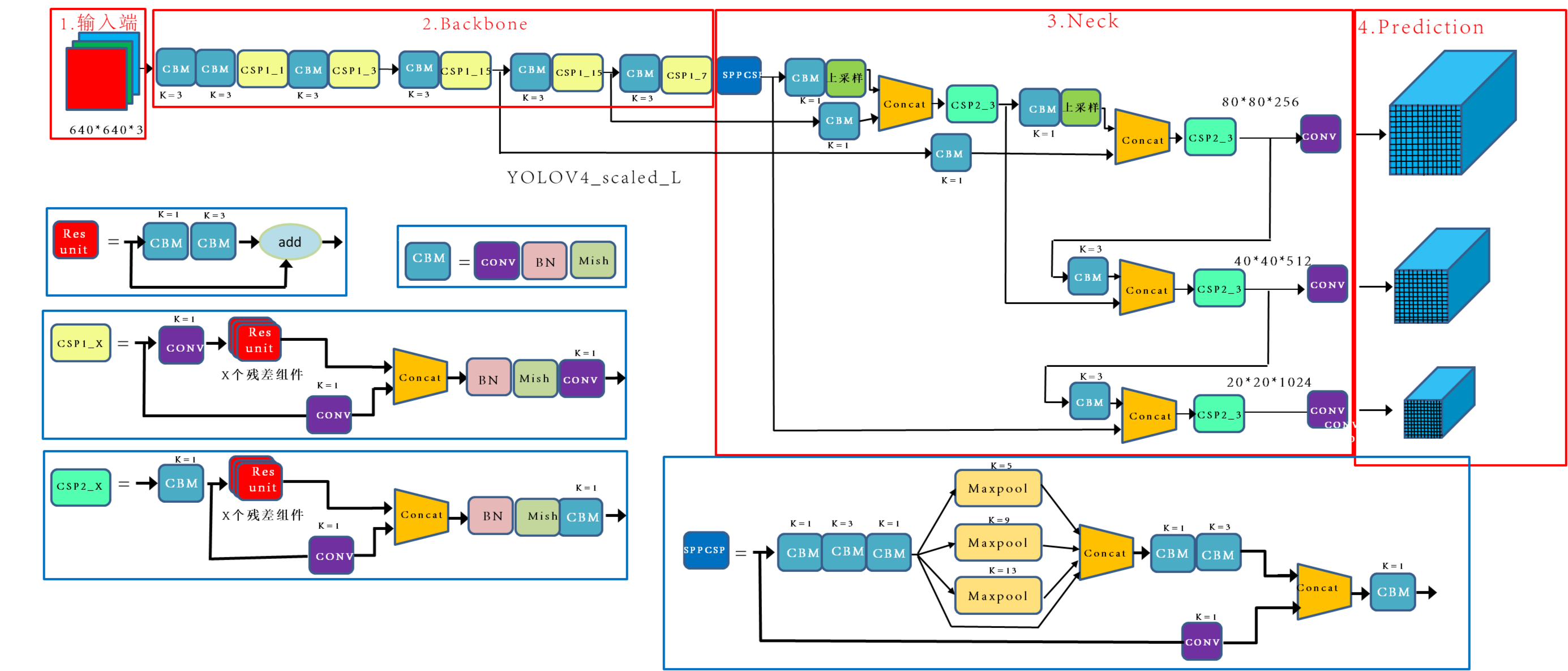
Scaled-YOLOv4
文章标题:Scaled-YOLOv4: Scaling Cross Stage Partial Network
作者:Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao
发表时间:(CVPR 2021)
拓展阅读
Review — Scaled-YOLOv4: Scaling Cross Stage Partial Network
YOLO V5
6.1
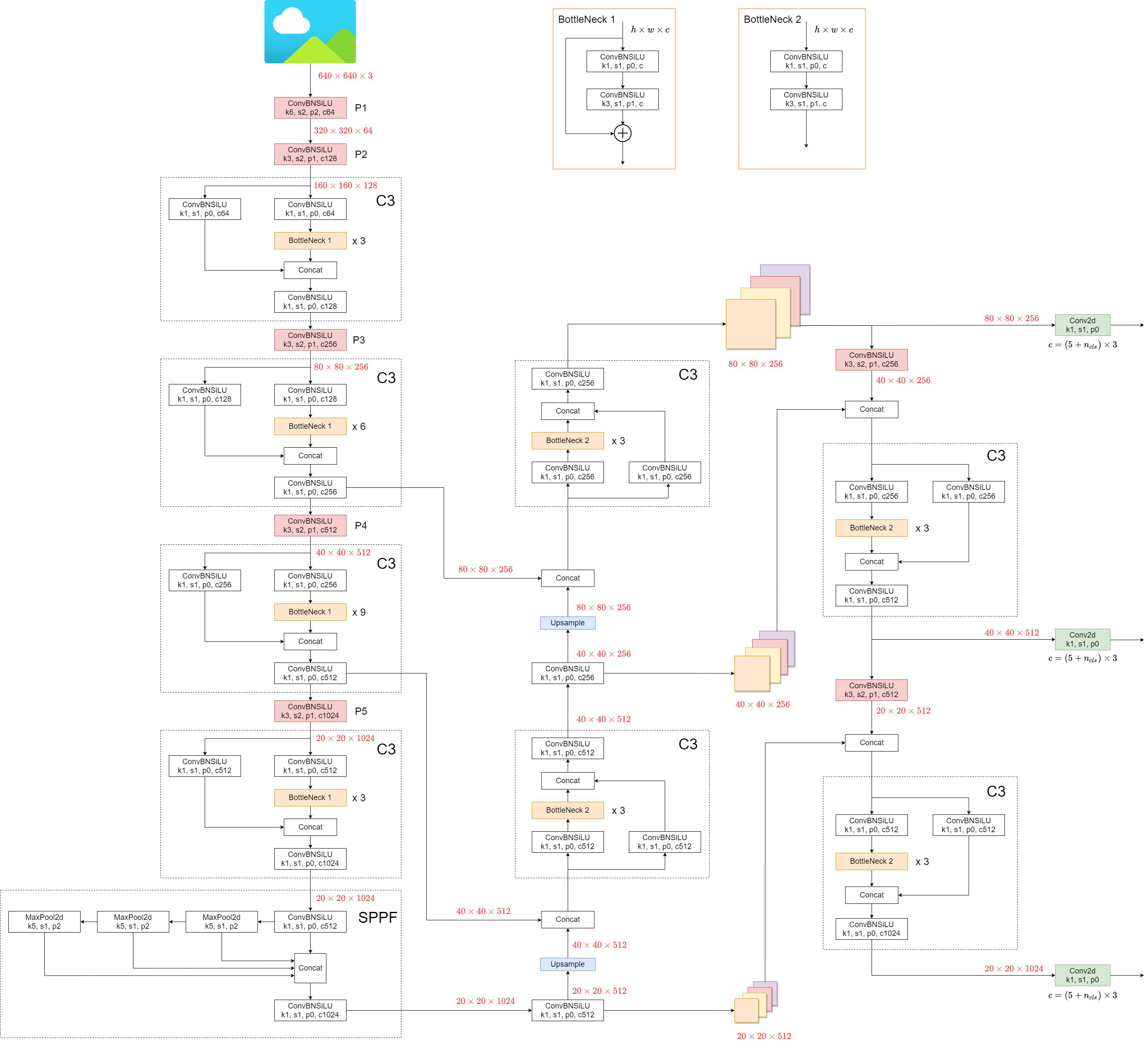
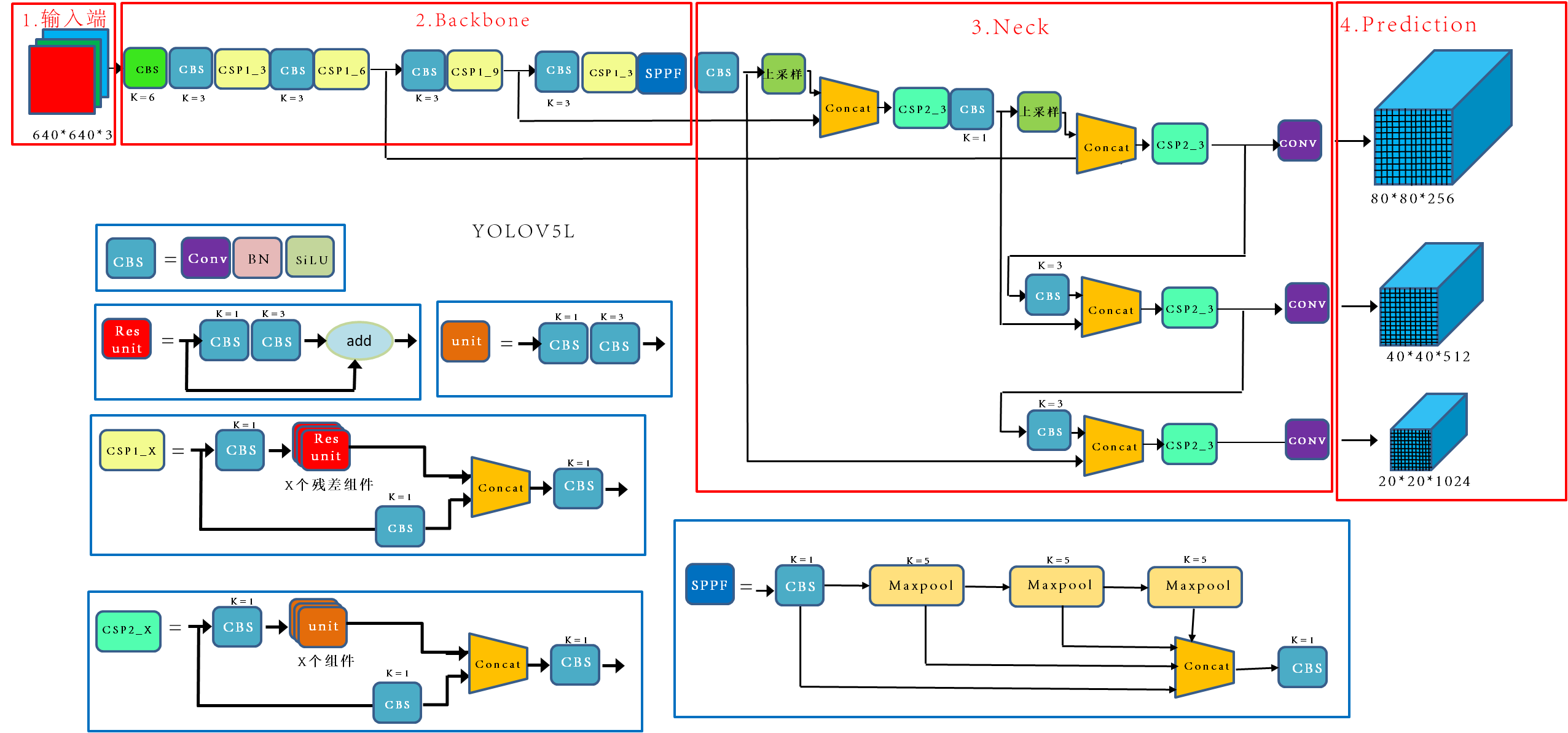
数据增强
data/hyps/hyp.scratch-high.yaml配置
Mosaic
copy paste:不同目标复制粘贴拼接
Random affine
MixUp
Albumentations 数据增强库
Augment HSV
Random horizontal flip
训练策略
Multi-scale training (0.5~1.5x)
AutoAnchor (For training custom data)
Warmup and Cosine LR scheduler
EMA (Exponential Moving Average)
Mixed precision
Evolve hyper-parameters
损失计算
Classes loss, 分类损失,采用的是BCE loss, 注意只计算正样本的分类损失。
Objectness loss, obj损失,采用的依然是BCE loss,注意这里的ob指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的obj损失。
$$ Loss = \lambda_1L_{cls} + \lambda_2L_{obj} + \lambda_3L_{loc} $$平衡不同尺度损失
$$ L_{obj} = 4.0\cdot L_{obj}^{small}+1.0 L_{obj}^{medum}+0.4 L_{obj}^{large} $$拓展阅读
YOLOv5 教程
- 训练自定义数据 🚀推荐的
- 获得最佳训练结果的提示 ☘️ 推荐的
- 权重和偏差记录 🌟新的
- 用于数据集、标签和主动学习的 Roboflow 🌟新的
- 多 GPU 训练
- PyTorch 集线器 ⭐新的
- TFLite、ONNX、CoreML、TensorRT 导出 🚀
- 测试时间增强 (TTA)
- 模型合奏
- 模型修剪/稀疏
- 超参数演化
- 冻结层的迁移学习 ⭐新的
- 架构总结 ⭐新的
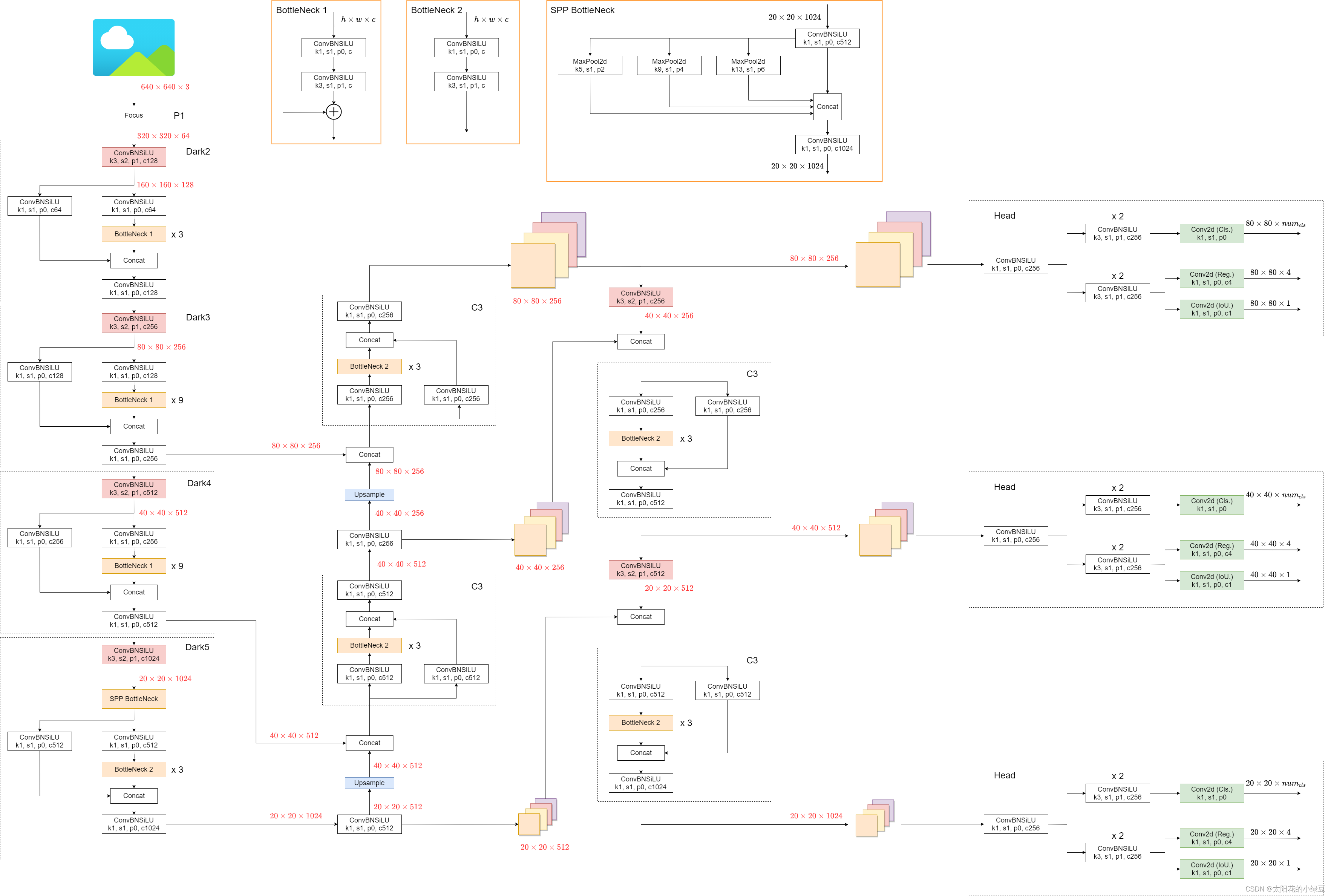
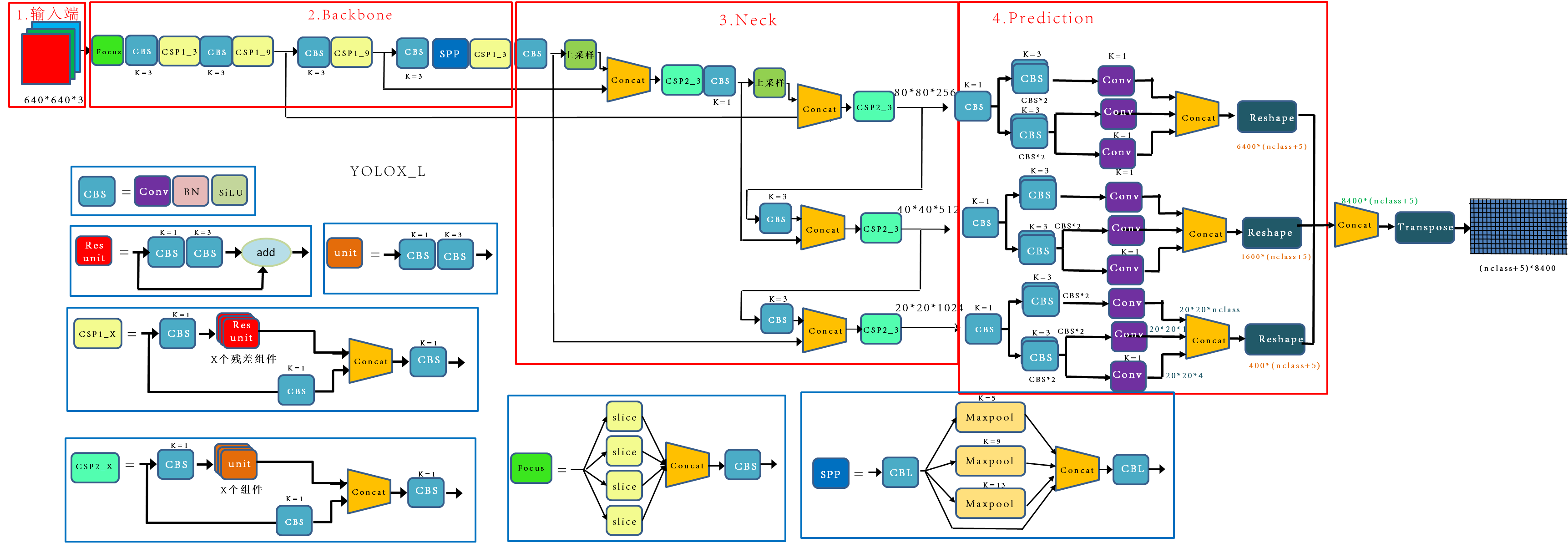
YOLOX
文章标题:YOLOX: Exceeding YOLO Series in 2021
作者:Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun
发表时间:(CVPR 2021)
Anchor-Free
和yolov5的v5.0不同的是head部分
拓展阅读
YOLO V7
文章标题:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
作者:Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao
发表时间:( 2022)