MAE
MAE
文章标题:Masked Autoencoders Are Scalable Vision Learners 作者:Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick
发表时间:2021
BERT的CV版
Masked Autoencoders are scalable vision learners 带掩码的自编码器 是可扩展的视觉学习器
两个词的用法
scalable:可扩展的,模型比较大 efficient:算法特别快
vision learners:一个 backbone 的模型 masked:来源于 BERT: 每次挖掉一些东西,然后去预测挖掉的东西 Auto-encoder: auto “自”,ML模型 auto 自模型; 样本 x 和 标号 y 来自于同样的句子里面的词 –> auto 加 auto 在 encoder之前,MAE 的图片标号是图片本身,区分于其它工作
What makes masked autoencoding different between vision and language?
什么使得 带掩码的自编码器模型在 CV 和 NLP 处理上的不一样呢?
CV 使用 CNN,卷积窗口不好将 mask 放进去
CNN 在一张图片上,使用一个卷积窗口、不断地平滑,来汇聚一些像素上面的信息 + 模式识别 Transformer 的一个 mask 对应的是一个特定的词,会一直保留,和别的词区分开来 卷积上不好做掩码:图片的一块盖住 by 像素替换成一个特定的值,卷积窗口扫过来、扫过去时,无法区分边界,无法保持 mask 的特殊性,无法拎出来 mask;最后从掩码信息很难还原出来
卷积不好加入位置编码? 不那么充分
Transformer 需要位置编码:attention 机制没有位置信息 卷积自带位置信息,不断平移时,不需要加入位置信息
语言和图片的信息密度不同
NLP 的一个词是一个语义的实体,一个词在字典里有很长的解释;一句话去掉几个词,任务很难,i.e., 完形填空 –> BERT 的 mask 比例不能过高 CV 的图片的Mask
Mask块太少,直接通过对邻居的像素值进行插值还原,太简单
随机去掉很高比例的块,极大降低图片的冗余性,迫使模型学习更好的表征:nontrivial 任务,使模型去看 一张图片的 holistic 全局信息,而不仅关注局部
The autoencoder‘s decoder
CV 还原图片的原始像素:低层次的表示 NLP 还原句子里的词:语义层次更高,i.e., BERT 的一个全连接层还原词 图片分类、目标检测的 decoder:一个全连接层 语义分割(像素级别的输出):一个全连接层不够,很有可能使用一个转置的卷积神经网络、来做一个比较大解码器。
Approach
随机盖住图片里的一些块(patch, image 的一个块),再重构缺失的像素。
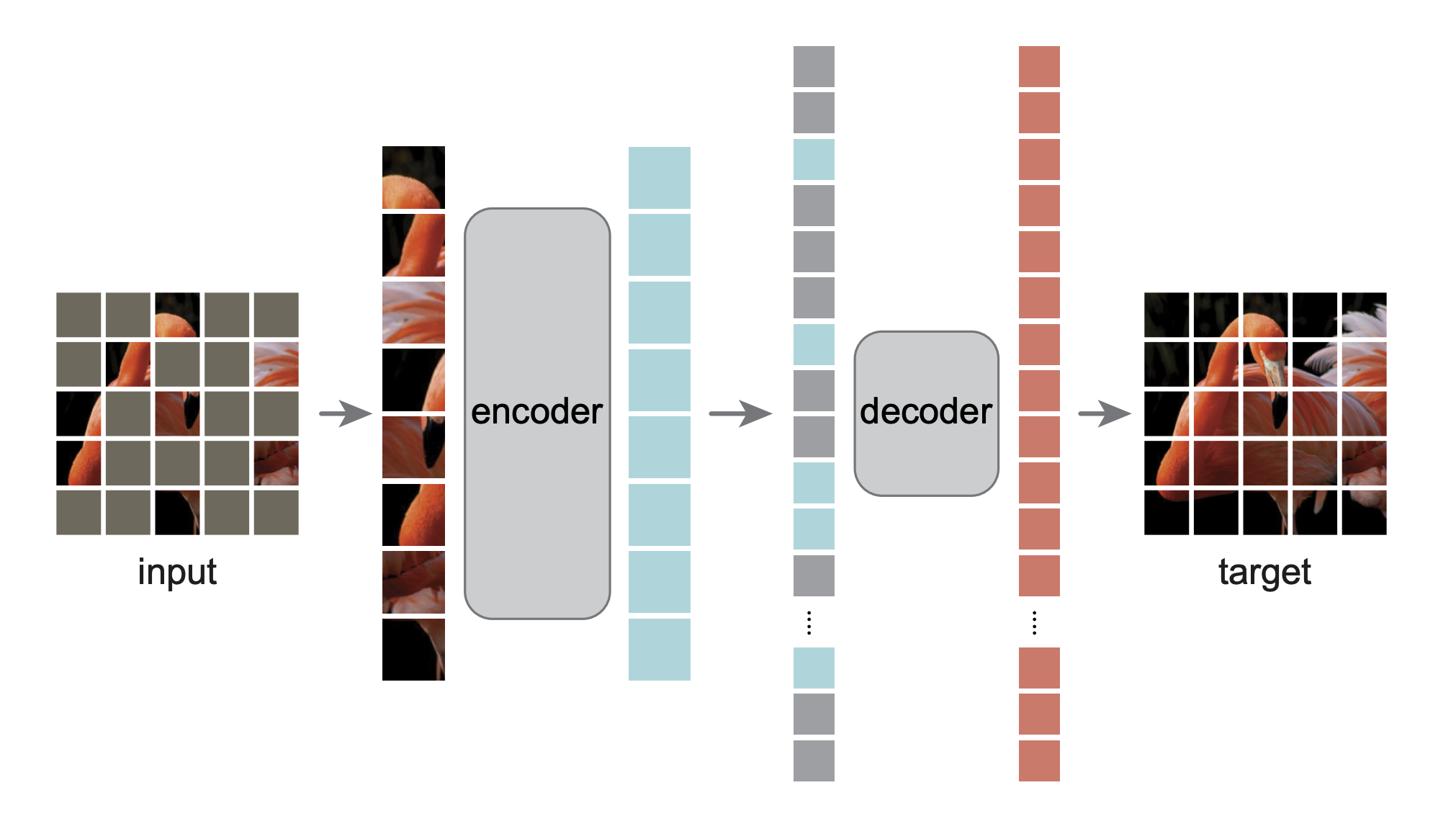
预训练流程:input –> patches –> masked –> unmasked patches in encoder –> unmasked + masked 按位置排列进 decoder –> decoder 重构 masked patches 的像素
patches + masked:一张红色鸟图片进来,切成 patches,masked 块 (3/4) 是 灰色的。 unmasked patches,encoder:没有 masked (1 / 4) 的块 进入 encoder (ViT),得到每一块的特征(蓝色)。 encoder 的输出 和 masked tokens 按照在图片中的原始位置排列成一长条向量 (包含位置信息)。 长条向量 进入 decoder,解码器尝试重构缺失的像素信息,还原原始图片
解码器的最后一层: a linear projection
一个 patch 是 16 * 16 像素的话,线性层会投影到长为 256 的维度,再 reshape(16, 16), 还原原始像素信息 损失函数: MSE,像素值相减,再平方和(只作用于非可见块的损失,和 BERT 一样)
encoder 比 decoder 高:计算量主要来自于 encoder,对图片的像素进行编码
用 MAE 做一个 CV 的任务,只需要用编码器。一张图片进来,不需要做掩码,直接切成 patches 格子块,然后得到所有 patches 的特征表示,当成是这张图片的特征表达,用来做 CV 的任务
Simple implementation
对每一个输入 patch 生成 a token:一个一个 patch 的线性投影 + 位置信息 随机采样:randomly shuffle 随机打断序列,把最后一块拿掉。
从头部均匀的、没有重置的样本采样 25% 意味着 随机 shuffle, 只保留前 25%
after encoding 解码时:append 跟以前长度一样的这些掩码的一些词源 mask tokens (一个可以学习的向量 + 位置信息),重新 unshuffle 还原到原来的顺序
MSE 算误差时,跟原始图的 patches 对应