VIT
[toc]
Vision Transformer (VIT)
文章标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 作者:Alexey Dosovitskiy; Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn,Xiaohua Zhai 发表时间:(ICLR 2021)
Transformer杀入CV界
每一个方格都是 16 * 16 大小,图片有很多 16 * 16 方格 patches –> an image is worth 16 * 16 words
一个 224 * 224 图片 变成一个 196 个的 16 * 16 图片块(words in NLP)。
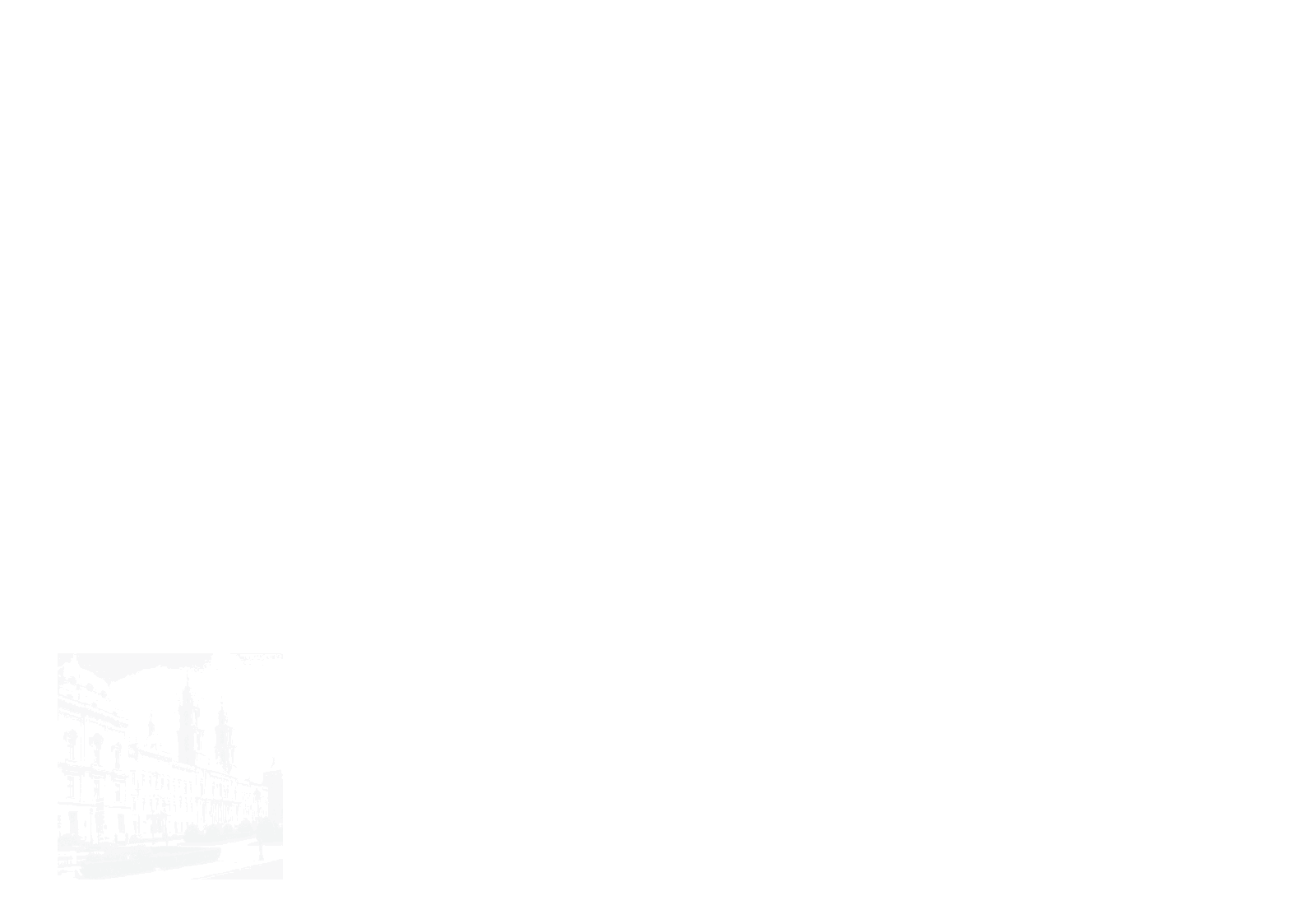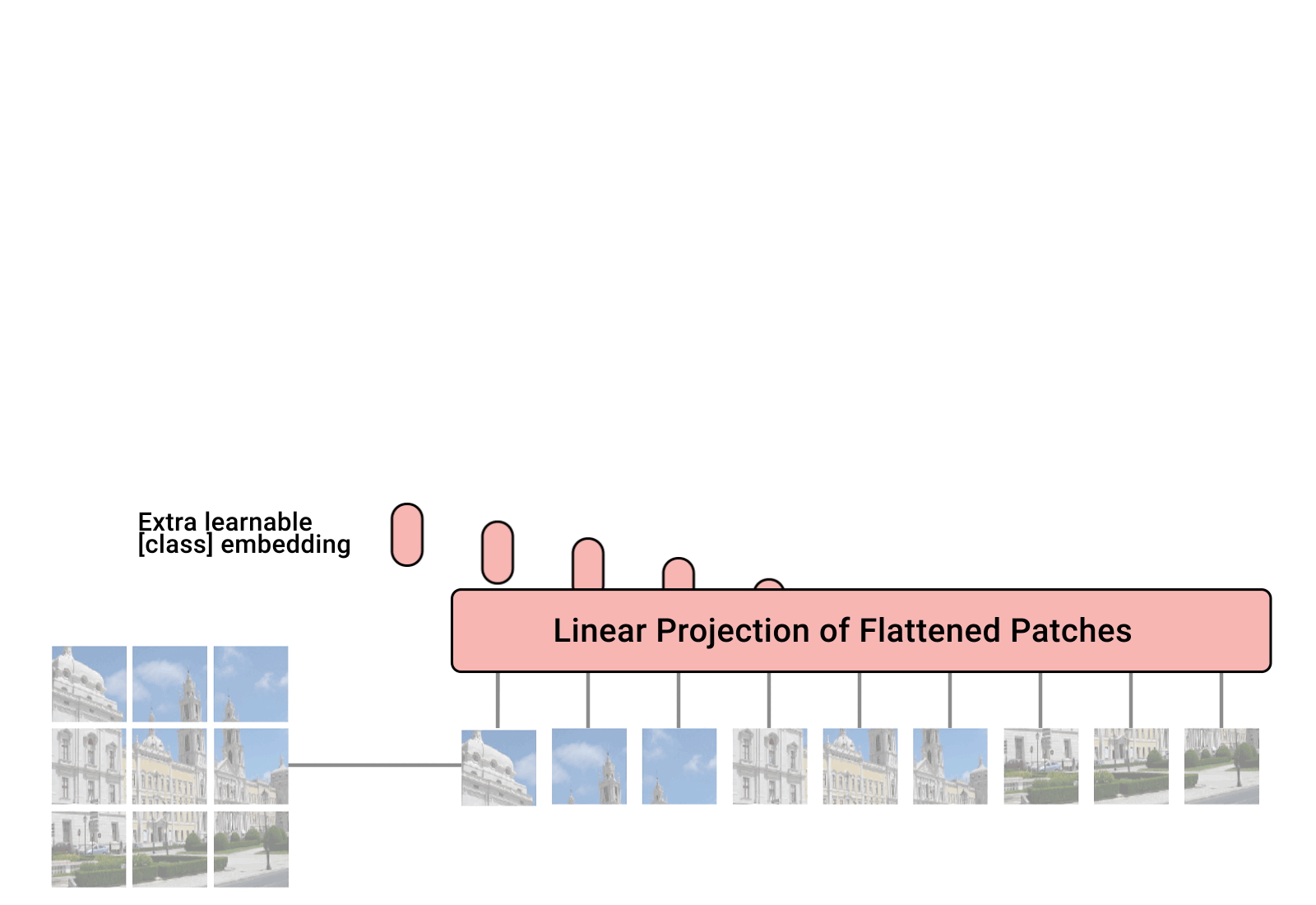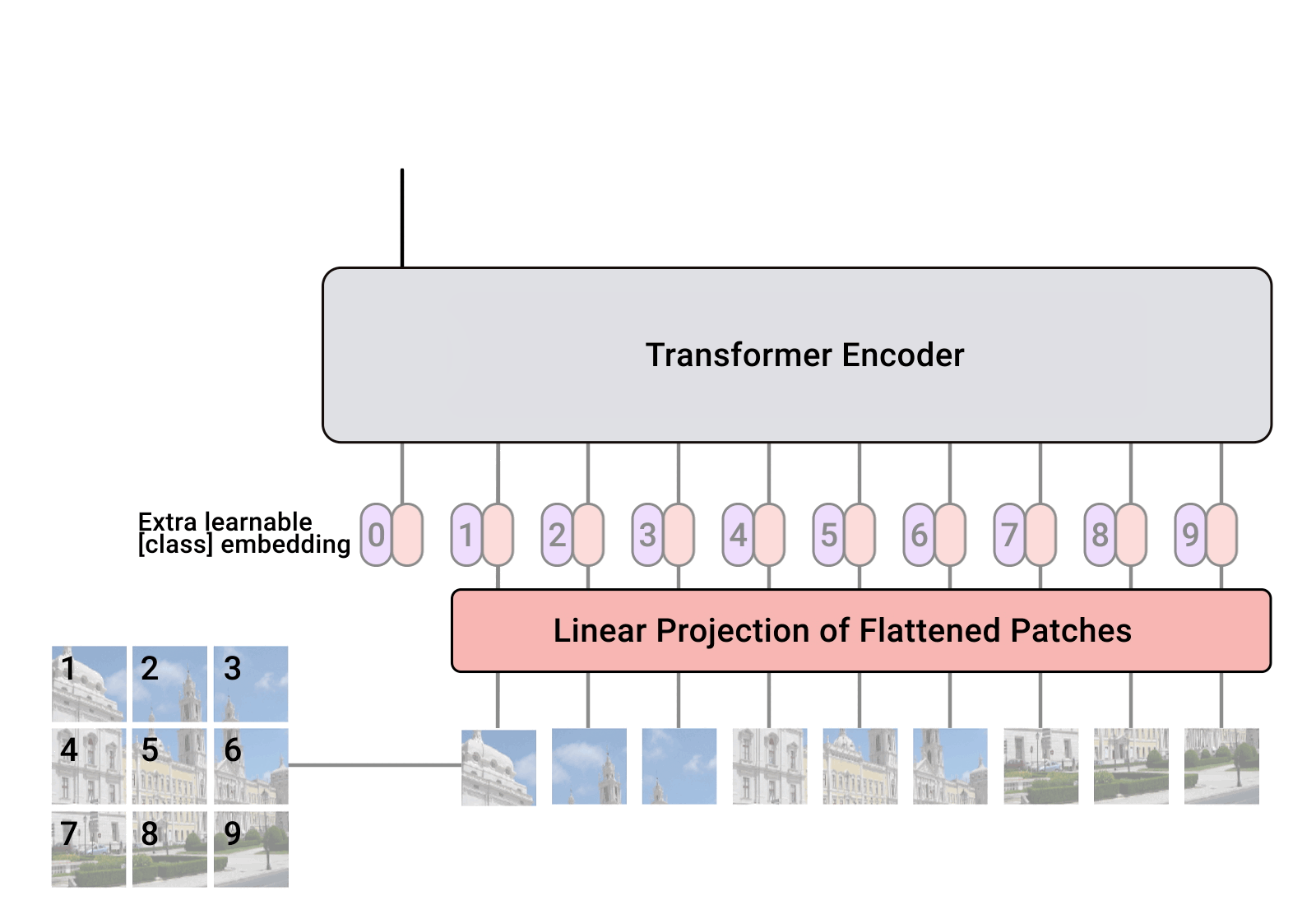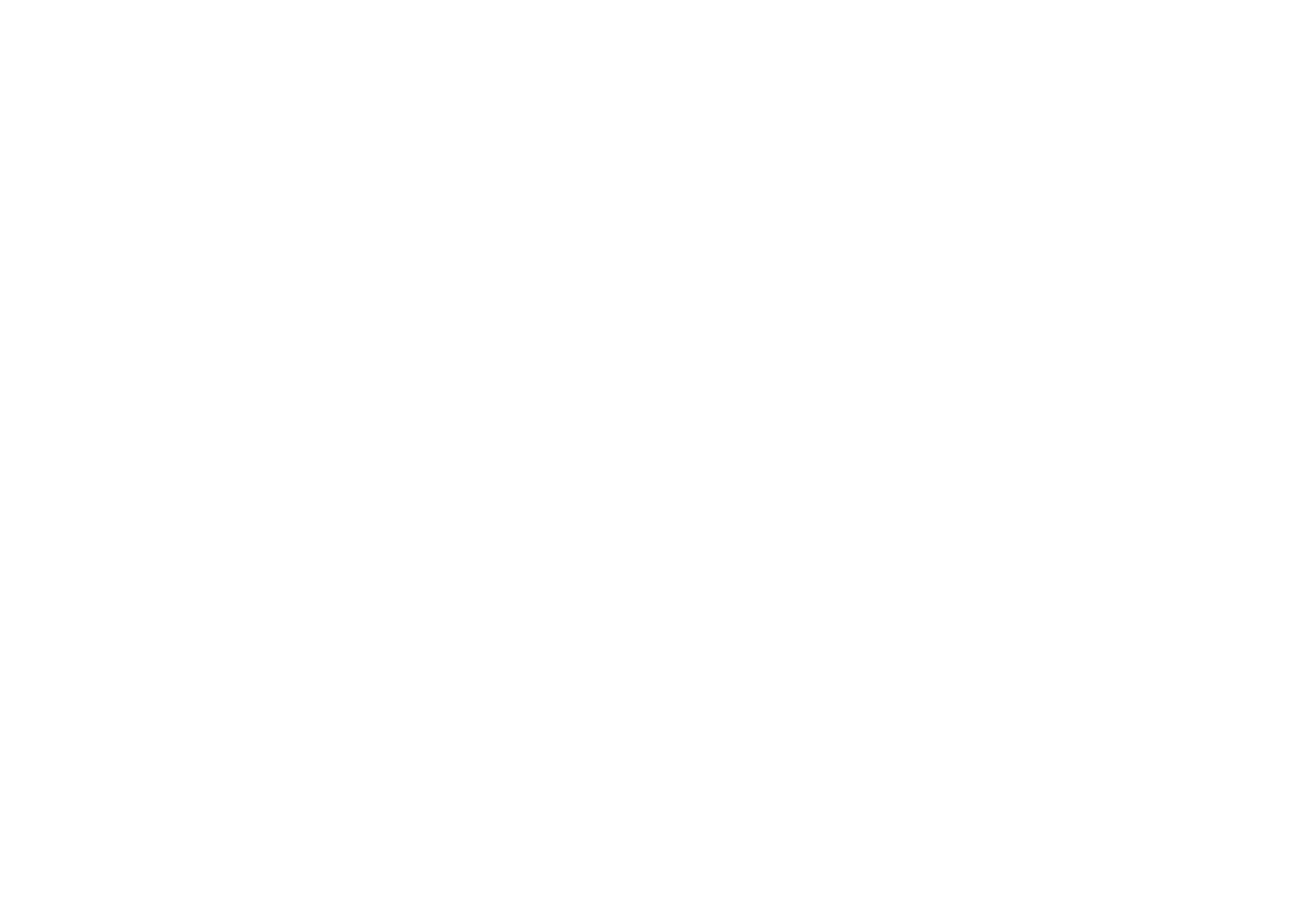
Introdouction
Transformer 应用在 CV 的难点
计算像素的 self-attention,序列长,维度爆炸
Trnasformer 的计算复杂度是序列长度 n 的 平方即 $O(n^2)$
224 分辨率的图片,有 50176 个像素点,(2d 图片 flatten)序列长度是 BERT(512) 的近 100 倍。
CV 如何用attention( 降低序列长度)
CNN 结构 + self-attention
Non-Local Network, 网络中的特征图当作输入 Transformer
attention 替代卷积
stand-alone attention 孤立自注意力
用 local window 局部小窗口控制 transformer 的计算复杂度
axial attention 轴注意力
2d变成2个1d 顺序操作,降低计算复杂度
Transformer 比 CNN 少 inductive biases 归纳偏置(先验知识 or 提前的假设)
CNN 的 inductive biases 是 locality 和 平移等变性 translation equaivariance(平移不变性 spatial invariance)
locality: CNN用滑动窗口在图片上做卷积。假设是图片相邻的区域有相似的特征。
translation equaivariance:f (g(x)) = g( f(x) );f 和 g 函数的顺序不影响结果。
CNN 的卷积核 像一个 template 模板,同样的物体无论移动到哪里,遇到了相同的卷积核,它的输出一致
Transformer 没有这些先验信息,只能从图片数据里,自己学习对视觉世界的感知。
ViT 用了图片 2d 结构 的 inductive bias 地方:resolution adjustment 尺寸改变 和 patch extraction 抽patches
Related work
ICLR 2020 从输入图片里抽取 2 * 2 patches。
CIFAR-10 32 * 32 图片,2 * 2足够,16 * 16 会过大。 抽好 patch 之后,在 patches 上 做 self-attention。
VIT Model
ViT-B/16为例
Model Patch_size Layers Hidden_size D MLP_size 4D Heads Params $Vit_{base}$ $16\times16$ 12 768 3071 12 86M $Vit_{large}$ $16\times16$ 24 1024 4096 16 307M $Vit_{huge}$ $14\times14$ 32 1280 5120 16 632M
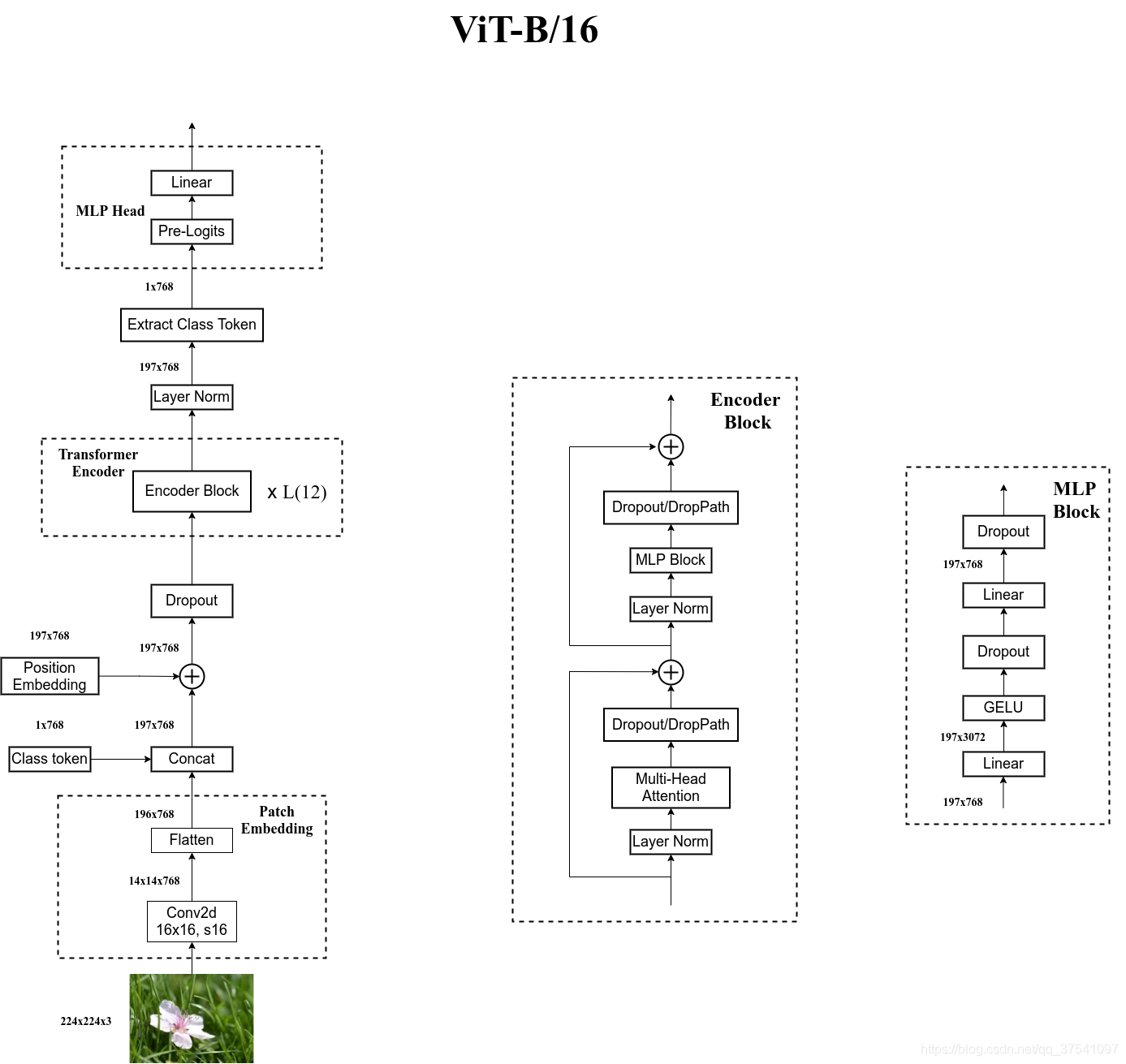
划分 patches,flatten patches 的线性投影 + patches 的位置信息,得到输入transformer 的 tokens
将图像$224×224×3$划分成大小$16×16$的patch(小方块),每个patch块可以看做是一个token(词向量),共有$(224/16)^2=196$个token,每个token的长度为$16×16×3=768$。
[16, 16, 3] -> [768]在代码实现中,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积
[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768]如果改变图像的输入大小,ViT不会改变patchs的大小,那么patchs的数量会发生变化,那么之前学习的pos_embed就维度对不上了,ViT采用的方案是通过插值来解决这个问题
[class] token:可训练的参数,长度为768的向量,
Concat([1, 768], [196, 768]) -> [197, 768]所有的 tokens 在做两两的交互信息。因此,[CLS] 也会和所有的图片patches 的token 交互,从而 [CLS] 从图片 patches + position 的 embedding 学到有用信息,最后用**[CLS]** 做分类判断。
CV 通常的全局特征:feature map (14 * 14) –> GAP globally average-pooling 全局平均池化 –> a flatten vector 全局的图片特征向量 –> MLP 分类
同样的,Transformer 的输出元素 + GAP也可以用做全局信息 + 分类,效果差异不大;
ViT 对齐 标准的 transformer,选用 NLP 里常用的 CLS 和 1d position embedding
Position Embedding:采用的是一个可训练的参数(1D Pos. Emb.)
Add([197, 768], [197, 768]) -> [197, 768]
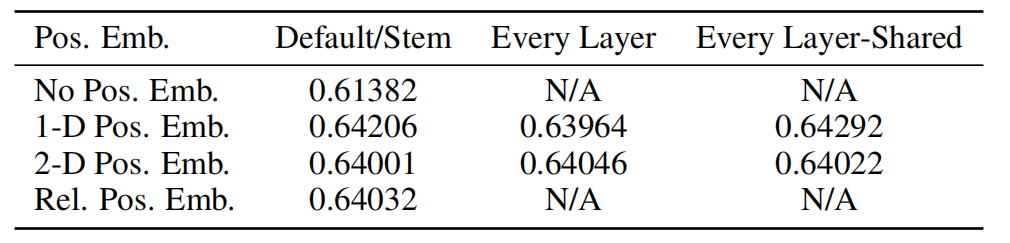
选择不同位置编码几乎没有差异,原因是Transformer是直接在patch上操作而不是基于像素级,较少数量的 patches 之间的相对位置信息,容易学到,因此,空间信息编码方式差异没那么重要
Vit Architecture
MLP Head
整个Encoder的输出为
[197, 768]我们仅仅保留最前面的CLS token作为全连接的输入[1, 768],然后接上全连接层及分类数n_class,使用交叉熵损失函数计算损失,反向传播更新网络的权重和参数。在训练ImageNet21K时是由
Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可
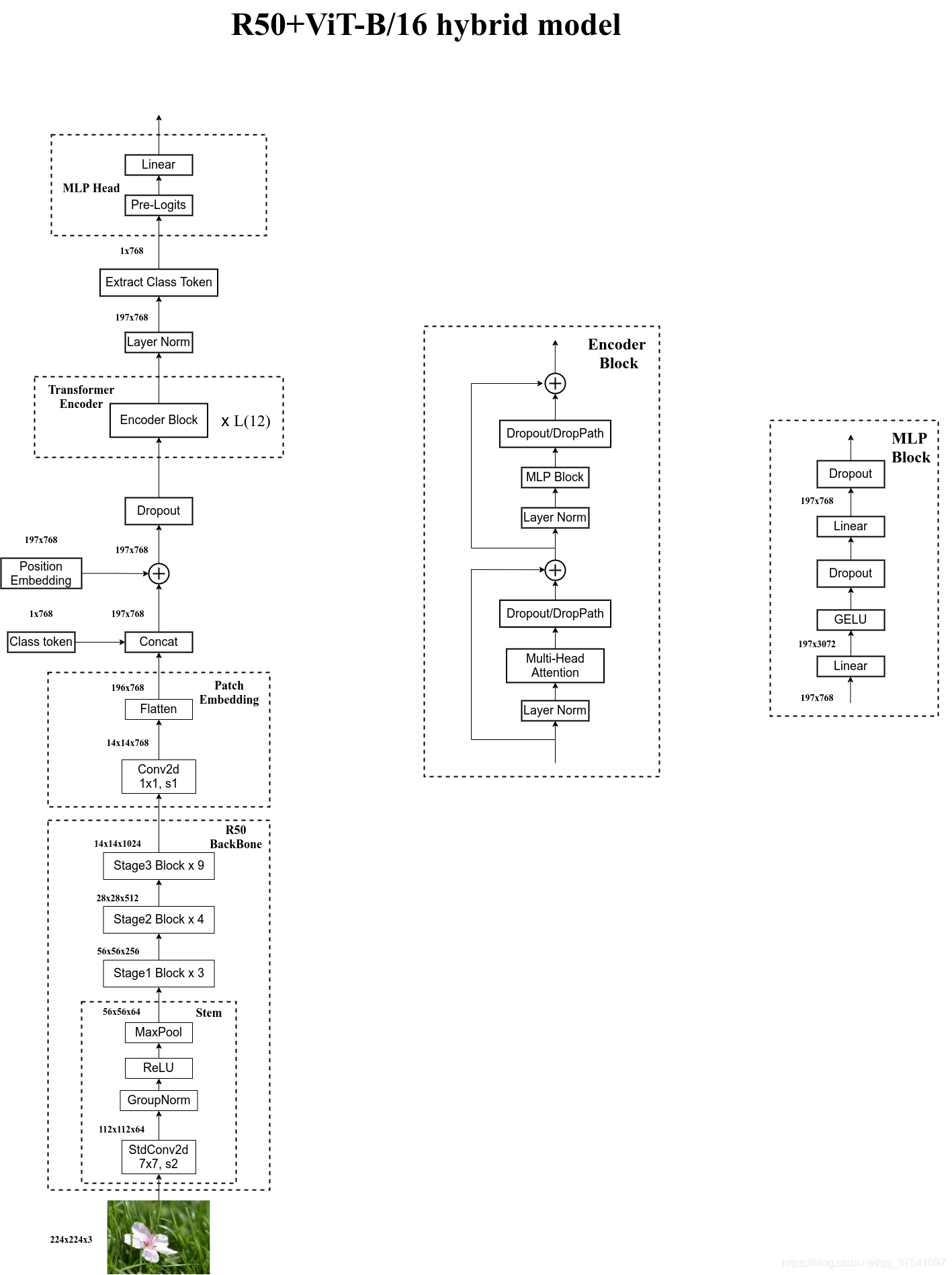
Hybrid Architecture
前 CNN + 后 Transformer
R50不同之处
R50的卷积层采用的StdConv2d不是传统的Conv2d
所有的BatchNorm层替换成GroupNorm层。
在原Resnet50网络中,stage堆叠次数 [3,4,6,3]。R50中,把stage4中的3个Block移至stage3中,变成 [3,4,9]。
通过R50 Backbone进行特征提取后,得到的特征矩阵shape是[14, 14, 1024],接着再输入Patch Embedding层,注意Patch Embedding中卷积层Conv2d的kernel_size和stride都变成了1,只是用来调整channel。
拓展阅读
代码
State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow
Swin Transformer
文章标题:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 作者:Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo
发表时间:(ICCV 2021)
多层次的Vision Transformer
Swin Transformer是一个用了移动窗口的层级式的Vision Transformer
Swin:来自于 Shifted Windows
更大的效率
通过 shifting 移动的这个操作,能够让相邻的两个窗口之间有了交互,所以上下层之间就可以有 cross-window connection,从而变相的达到了一种全局建模的能力
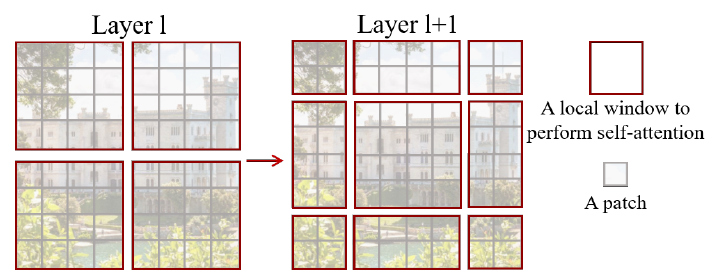
层级式 Hierarchical
减少序列长度方式
用后续的特征图来当做Transformer的输入,
把图片打成 patch
把图片画成一个一个的小窗口,然后在窗口里面去做自注意力
借鉴了很多卷积神经网络的设计理念以及先验知识
采取了在小窗口之内算自注意力
利用了卷积神经网络里的 Locality 的 Inductive bias,就是利用了局部性的先验知识,同一个物体的不同部位或者语义相近的不同物体还是大概率会出现在相连的地方
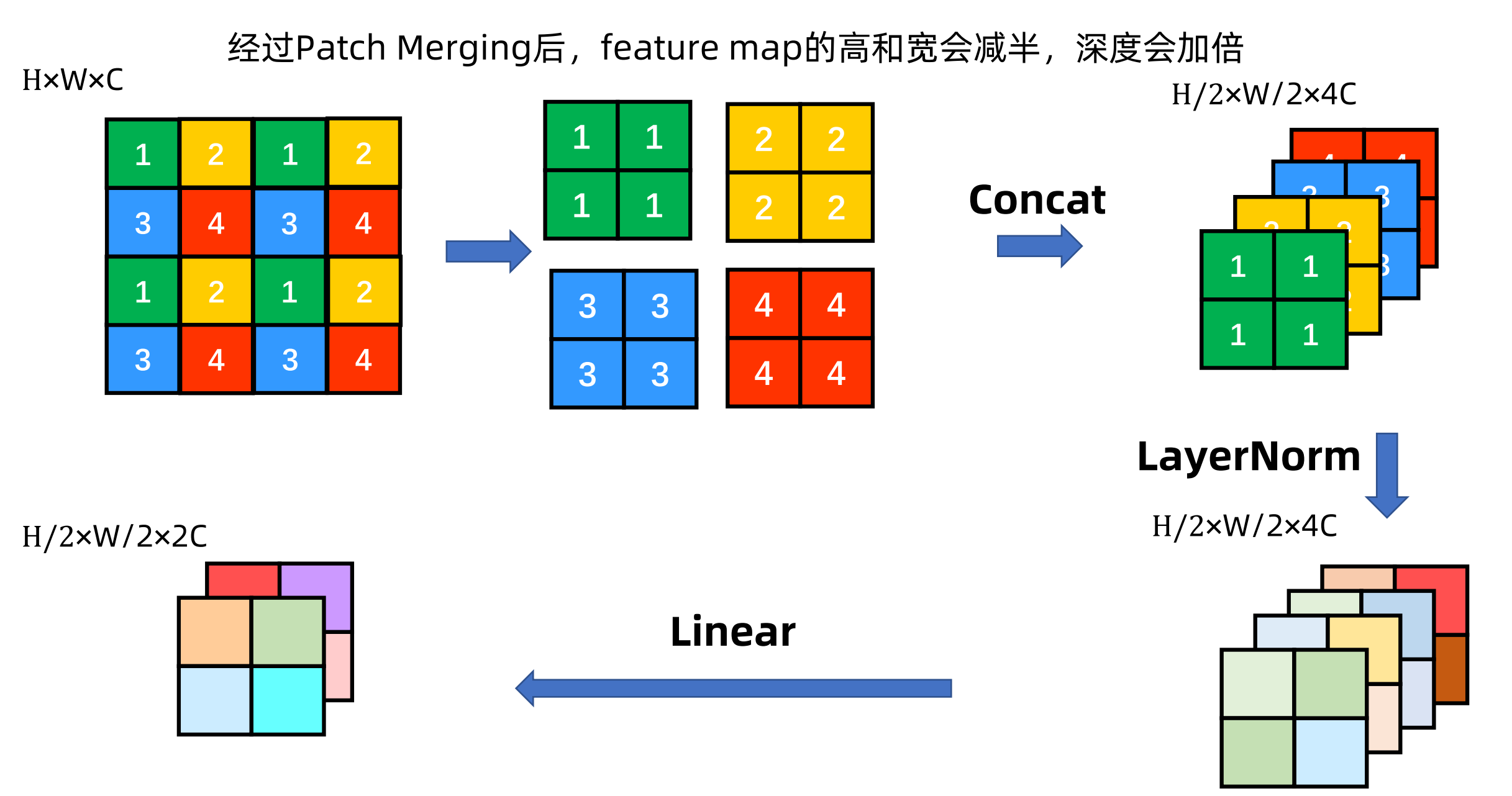
提出来了一个类似于池化的操作叫做 patch merging
把相邻的小 patch 合成一个大 patch,这样合并出来的这一个大patch其实就能看到之前四个小patch看到的内容,它的感受野就增大了,同时也能抓住多尺寸的特征
Overall Architecture
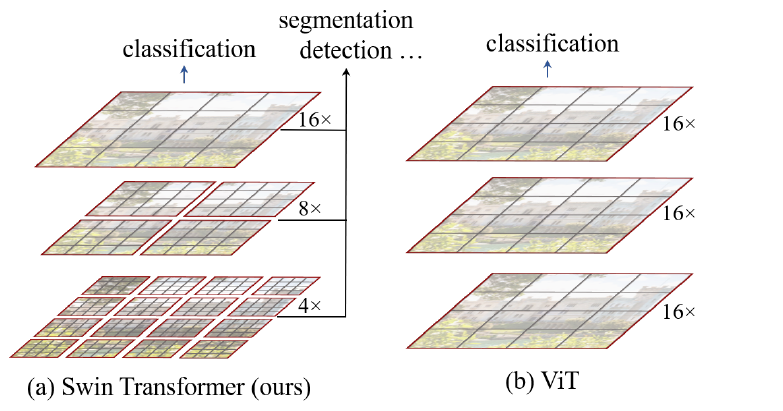
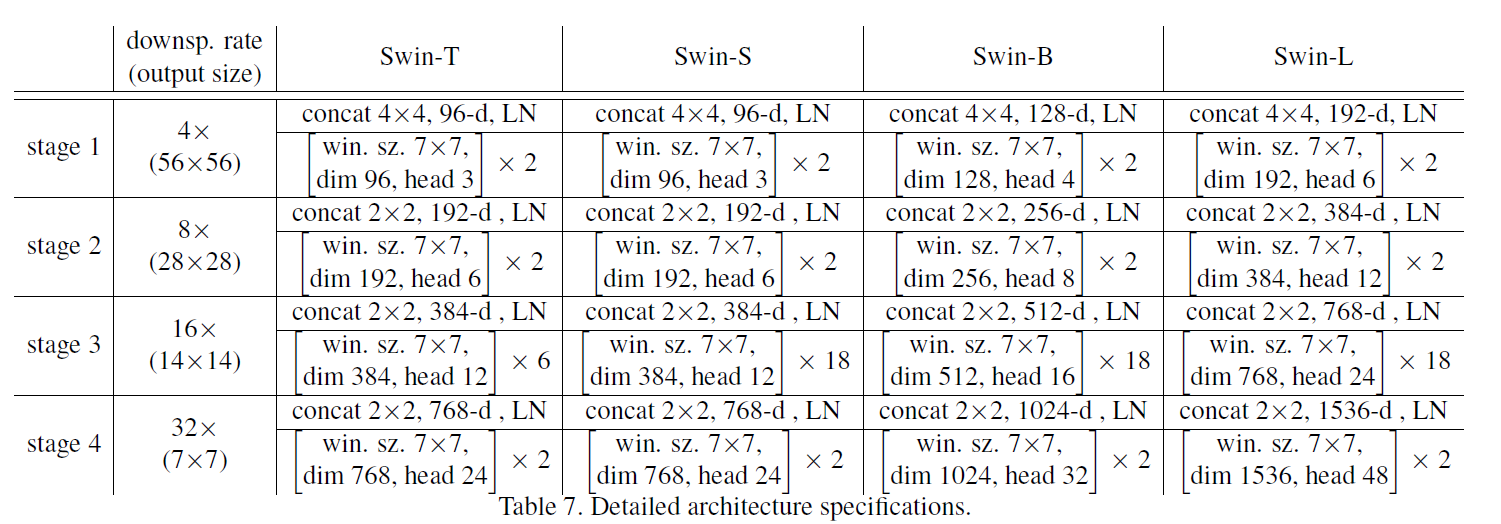
win. sz. 7x7表示使用的窗口(Windows)的大小dim表示feature map的channel深度(或者说token的向量长度)head表示多头注意力模块中head的个数
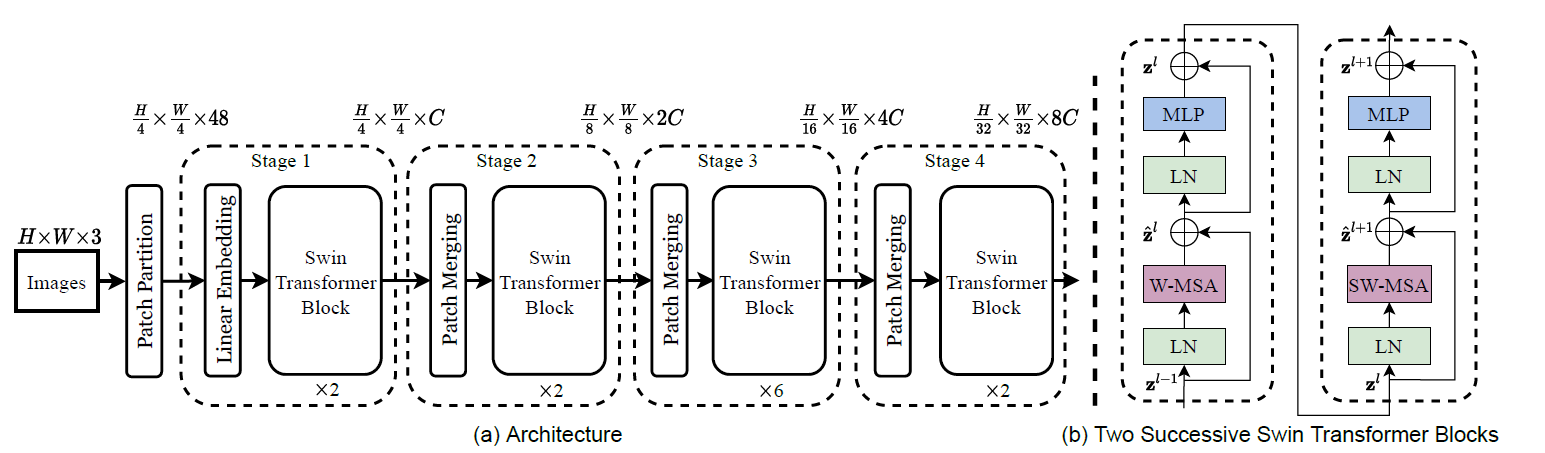
patch partition:将图像$224×224×3$划分成大小$4×4$的patch(小方块),得到$56\times56\times48$大小。
($224/4=56,\ 4\times4\times3=48$)
[224, 224, 3] -> [56, 56, 48]
Linear Embedding:要把向量的维度变成一个预先设置好的值C,对于 Swin tiny来说$C=96$
[56, 56, 48] ->[56, 56, 96]Patch Partition 和 Linear Embedding 就相当于是 ViT 里的Patch Projection 操作,而在代码里也是用一次卷积操作就完成
$56\times56=3136$太长,引入了基于窗口的自注意力计算,每个窗口按照默认来说,都只有$M^2=7^2=49$个 patch,所以说序列长度就只有49就相当小了
共有$ (56/7)\times(56/7)=8\times8=64 $个窗口。
Stage 1 经过 2 个 Swin Transformer Block,做了窗口滑动后输出的尺寸依然为 $56\times56\times96$。
Stage 2 经过 Patch Merging后,尺寸减半,通道数翻倍,变成了$ 28\times28\times192$,再经过 2 个 Swin Transformer Block,输出$ 28\times28\times192$。
Stage 3 经过Patch Merging后,尺寸减半,通道数翻倍,变成了$ 14\times14\times384$,再经过 6 个 Swin Transformer Block,也就是窗口滑动了 3 次,输出 $ 14\times14\times384$。
Stage 4 经过Patch Merging后,尺寸减半,通道数翻倍,变成了$ 7\times7\times768$,再经过 2 个 Swin Transformer Block,输出$ 7\times7\times768$。
Path Merging
$H\times W \times C -> \ \frac{H}{2}\times \frac{W}{2} \times 4C-> \ \frac{H}{2}\times \frac{W}{2} \times 2C$
Swin Transformer Block
$$ Attention(Q,K,V)=softmax(\frac{Q\dot K^T}{\sqrt d}V) $$W-MSA
MSA W_MSA 拿stage1举例:尺寸为$56\times56\times96$;每个窗口按照默认来说,都只有$M^2=7^2=49$个 patch;共有$ (56/7)\times(56/7)=8\times8=64 $个窗口。这64个窗口里分别去算它们的自注意力。
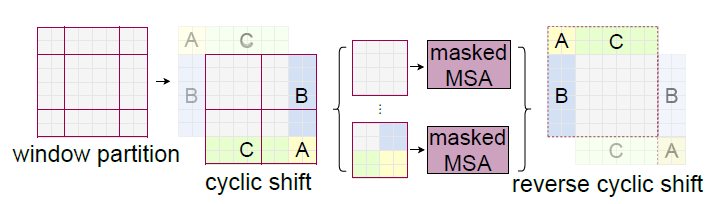
SW-MSA
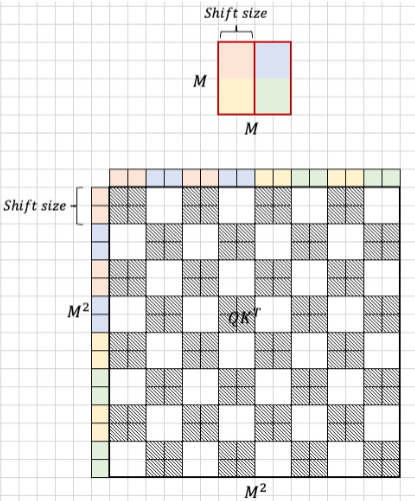
移动窗口就是把原来的窗口往右下角移动一半窗口(M/2)的距离
SW_MSA SW_MSA 如果Transformer是上下两层连着做这种操作,先是 window再是 shifted window 的话,就能起到窗口和窗口之间互相通信的目的。
两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构。所以堆叠Swin Transformer Block的次数都是偶数。



SA模块
$X^{hw\times C} \cdot W^{C\times C}_q = Q^{hw\times C}$ 矩阵运算量计算:$hw\times C \times C$
$X^{hw\times C} $:将所有像素(token)拼接在一起得到的矩阵(一共有hw个像素,每个像素的深度为C)
$W^{C\times C}_q$:生成query的变换矩阵
同理K,V的生成也是$hw\times C \times C$,共$3hwC^2$
$Q\cdot K^T$:$(hw \times C )\cdot(C \times hw)->(hw)^2C$
$\frac{Q\dot K^T}{\sqrt d}V$:$(hw \times hw )\cdot(hw \times C)->(hw)^2C$
一共$3hwC^2+2(hw)^2C$
MSA模块
多头注意力模块相比单头注意力模块的计算量多最后一个线性投影层$(hw \times C )\cdot(C \times C)->hwC^2$
一共$4hwC^2+2(hw)^2C$
W_MSA模块
对每个窗口内使用多头注意力模块,一共有$\frac{h}{M}\times \frac{w}{M}$个窗口,窗口高宽M
计算量:$\frac{h}{M}\times \frac{w}{M} \times(4hwC^2+2(hw)^2C)=4hwC^2+2M^2hwC$
Shifted Window Attention
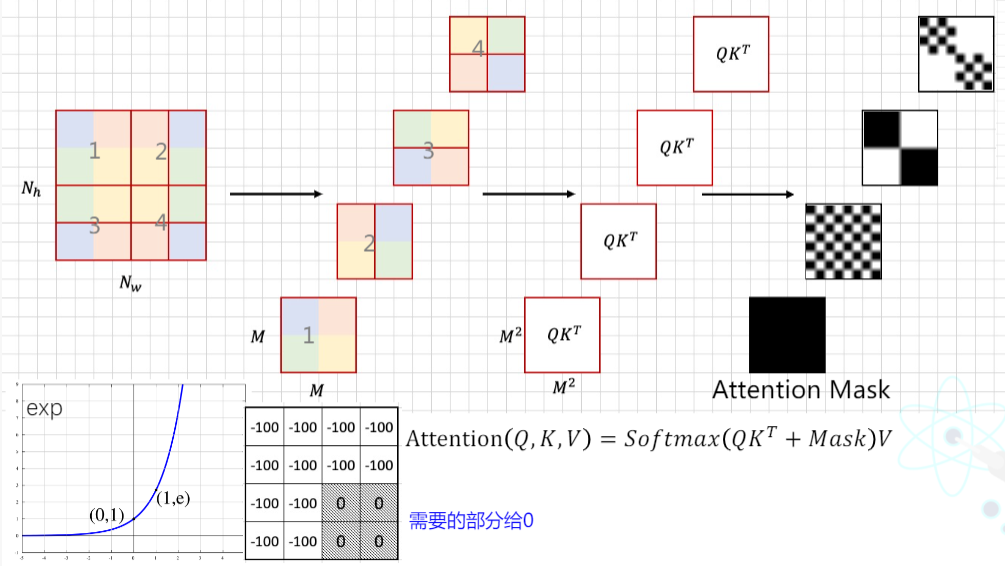
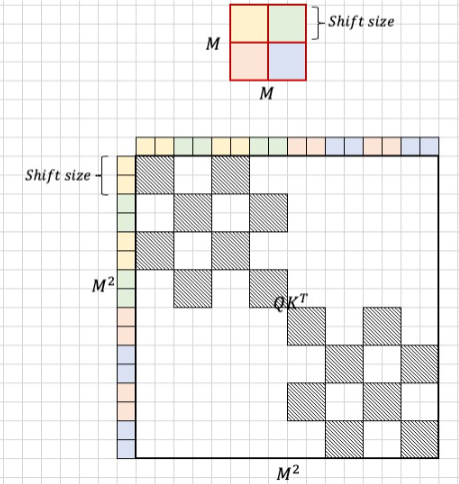
通过对特征图移位,并给Attention设置mask来间接实现的
特征图移位:使用torch.roll (x, shifts=-1, dims=0)将第一排数值移动到最下面,再使用torch.roll (x, shifts=-1, dims=1)将变换后的第二张图中的第一列移动到最右边

 |  |  |
| Mask_1 | Mask_2 | Mask_3 |
上图黑色区域是需要的,白色需要Mask,加上较大负数如-100即可。
最后还要恢复位置reverse cyclic shift
Relative position bias
$$ Attention(Q,K,V)=softmax((\frac{Q\dot K^T}{\sqrt d}+B)V) $$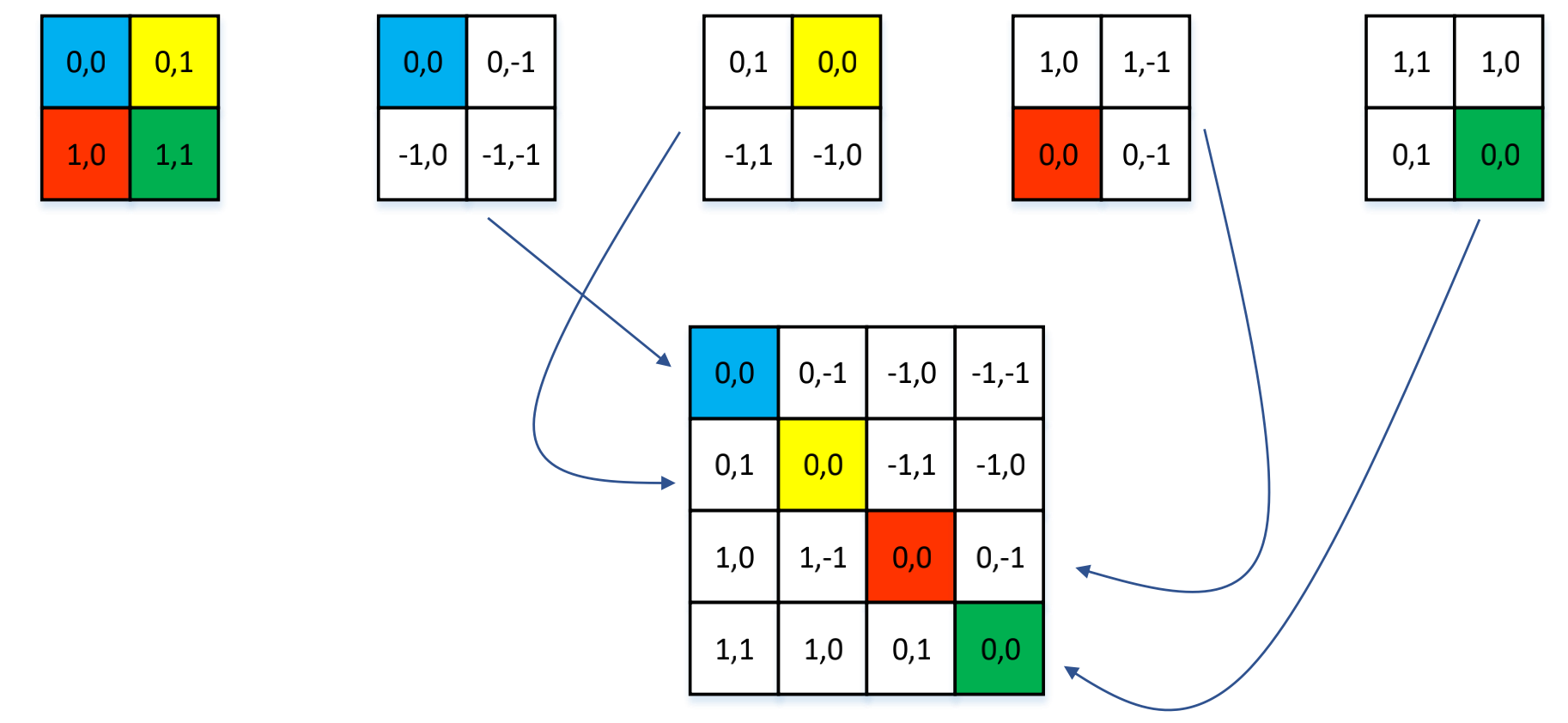
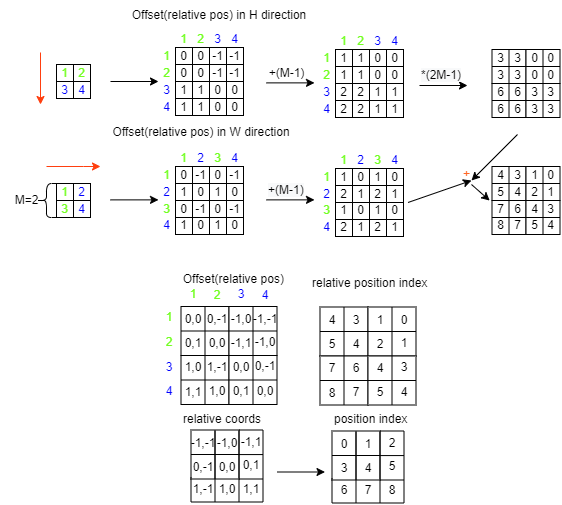
上图中的窗口中有 2*2 个 patch,分别给这四个位置标上绝对位置索引,分别为 (0,0)、(0,1)、(1,0)、(1,1),第一个序号代表行,第二个序号代表列。以蓝色像素为参考点。用蓝色像素的绝对位置索引与其他位置索引进行相减,就得到其他位置相对蓝色像素的相对位置索引。我们将各个相对位置索引展开成一个行向量,再进行拼接得到了下面的矩阵。

将该矩阵加上一个 M-1,M 为窗口的大小,在 Swin Transformer 中为 7,这里为 2。再将每一个行标都乘以 2M-1,最后将行标和列标求和,就得到最后一个矩阵的值,这个矩阵中的值就是相对位置索引
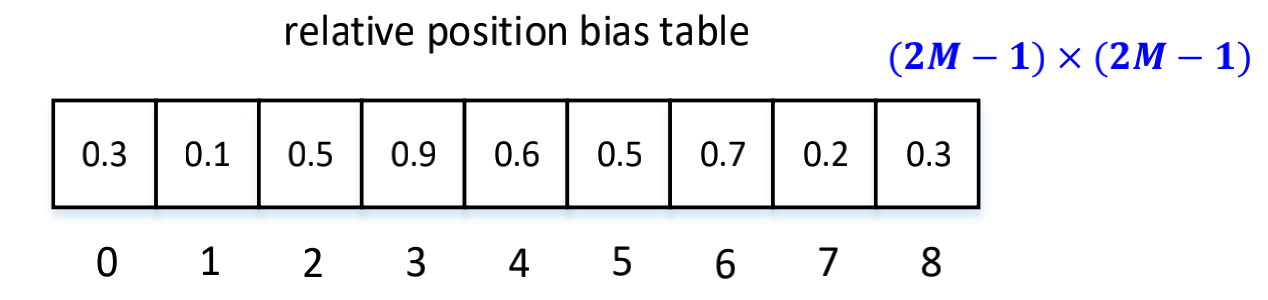
这个相对位置索引需要去索引的值会有一个相对位置偏置表 (relative position bias table);这个表的元素的个数为 (2M-1)*(2M-1)。